特性讲解
经典应用场景:
- 缓存。
因为Redis是基于内存的,内存的速度非常快。
- 计数器
可以用String类型来进行自增自减。
- 海量数据统计
位图: 存储是否参加过某次活动。
- 分布式队列,阻塞队列
通过List来实现
- 排行榜
zsort
Redis的key
Redis用C语言来写的,每一个key都是String,但并没有用原生的C的字符数组:
// 没有用以下结构char data[] = "wenlang\0";
而是用了SDS,即Simple Dynamic String。
原因就是结尾的\0. 如果传过来的是”guo\0jia”就会出问题。
SDS:free: 0 表示还剩多少空间len: 8char: buf[] = "wen\0lang"// 扩容// 小于1M时,进行成倍扩容len: 8addLen: 3新的长度:(len + addLen) * 2 = 18// 此外,会在结尾自动加上\0字符,以此来兼容C函数库
所以是二进制安全的。
SDS
在老版本,SDS的数据类型设计的不合理,会有很大的空间浪费。
后来更新版本以后,采用不同的数据类型来存不同的字符串,由小到大:
sdshdr5
sdshdr8
sdshdr16
...
底层数据结构
字典(map)类型的数据库。
底层实现类似于Java中的HashMap,采用数组 + 链表实现。
- 将key转化成hash
- 对长度取余得到index
- 如果index没有重复,直接放入
- 如果重复了,发现是同一个key,则覆盖
- 如果重复了,但是不生同一个key, 则采用头插法(链表)
- 如果放满了,就会成倍扩容,已防止频繁发生哈希冲突。
扩容:
从旧数组old搬到新数组,当访问某个值的时候,搬几个key到新的数组,直到旧数组搬空后释放。
亿级用户日活统计(bitmap)
面试题
亿级活跃用户,如何实现日活统计,为了增强用户黏性,上线一个连续打卡发放积分的功能,如何实现连续打卡用户统计。
日活统计:
在redis中,提供了setbit来设置bit位, setbit key offset 0 或者 1:
即将offset位置上的bit位设置为0或者1。
// 将第100位设置为1
setbit login:10:27 100 1
那么,我们可以以用户的Id为offset,就会有
setbit login:10:27 100 1
setbit login:10:27 30 1
setbit login:10:27 5 1
那么通过bitcount就可以统计出来bit位为1的总数,就是我们的日活数量。
bitcount login:10:27
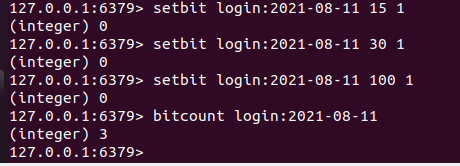
连续登陆
通过bitop进行按位与操作:
1 0 0 1 0 // 2021-08-11
1 1 0 0 1 // 2021-08-12
&
---------
1 0 0 0 0 // 为1表示两天都登录了
// and 表示与操作
// and 后面的那个login:and:08-11-12表示新的key
BITOP and login:and:08-11-12 login:2021-08-11 login:2021-08-12
BITCOUNT login:and:08-11-12
周活
通过bittop进行按位或操作:
1 0 0 1 0 // 2021-08-11
1 1 0 0 1 // 2021-08-12
|
---------
1 1 0 1 1 // 为1表示至少有一天登录了,因为是周活,统计7天即可。
// or 表示或操作
// and 后面的那个login:or:08-11-12表示新的key
BITOP or login:or:08-11-12 login:2021-08-11 login:2021-08-12
BITCOUNT login:or:08-11-12
值类型
有5个类型,String , list , set, zset, hash
这些类型都只是给客户端使用,用来规范客户端的API使用的。其底层其实更复杂。
事实上,我们在存储时,redis会给value值再封装一层,封装成redisObject对象,即: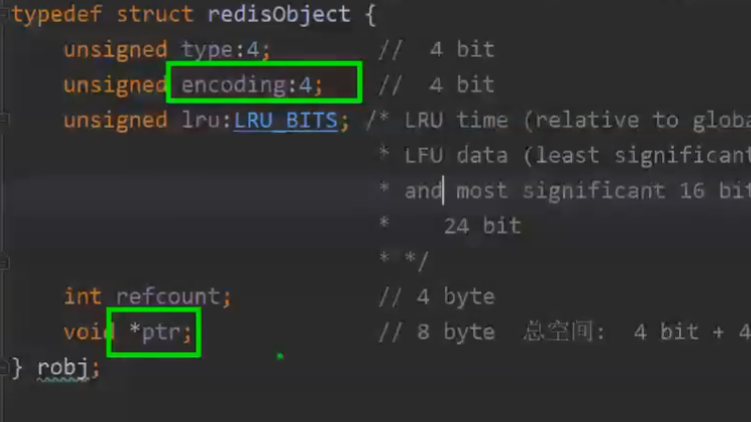
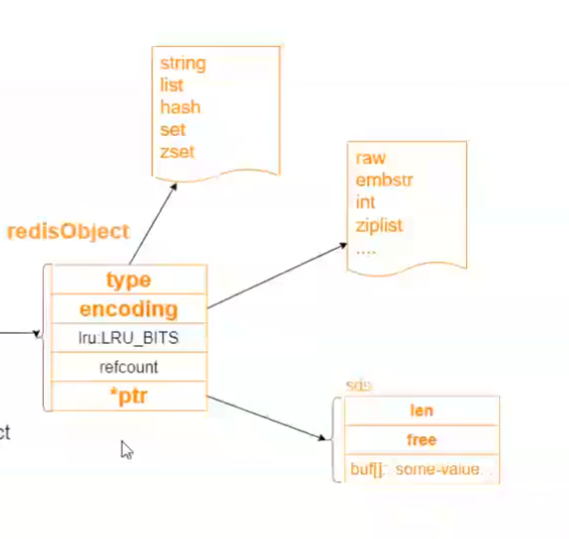
String类型
例如,我们用set进行设置时,value都是String类型,但是,当我们查看底层数据类型时,发现一个是embstr,一个是int。这就说明,redis会根据实际存入的值的不同,采取不同的存储策略。
127.0.0.1:6379> set string_test hello
OK
127.0.0.1:6379> set int_test 100
OK
127.0.0.1:6379> object encoding string_test
"embstr"
127.0.0.1:6379> object encoding int_test
"int"
int:
例如,当我们存储的值如果在整数范围内,在源码可以看到,当长度小于20时,ptr指针不再指向一个对象,而是直接存储该值。
embstr
我们的CPU在读取时,缓存行的大小为64byte, 一个redisObject仅为16byte,还剩余48byte。
然后会用sds占据4个字节,用来保存len, alloc, flags和填充的\0。还剩44byte。
当我们的value长度小于等于44byte时,就存成embstr类型,将其和redisObject一起读出来。
cpu:
cache line: 64byte
[redisObject: 16 byte, sds: 4 byte, embstr: <= 44 byte]
127.0.0.1:6379> set string_44 aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd1234
OK
127.0.0.1:6379> object encoding string_44
"embstr"
127.0.0.1:6379> set string_45 aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd12345
OK
127.0.0.1:6379> object encoding string_45
"raw"
以上代码可以看到,存成44个字节时,为embstr, 大于44就变成了raw

若有收获,就点个赞吧
0 人点赞
