类型
- String
- Hash
- List
- Set
- Zset (有序)
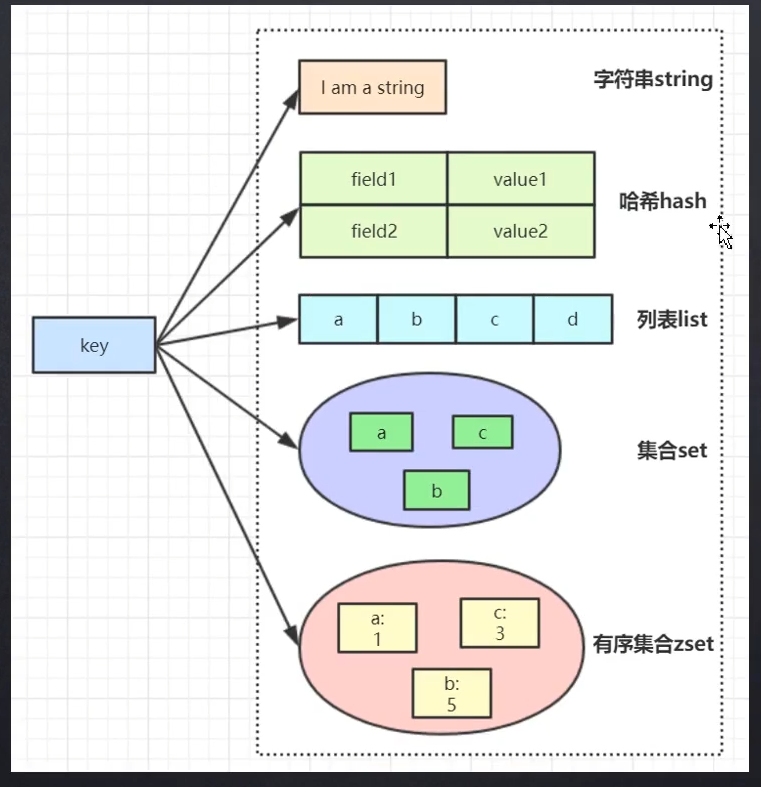
注意,都是key + value的形式,数据结构不同仅仅是Value的结构不同而已。
String
命令:
SET KEY VALUE
SET name lang
GET KEY
GET name// 返回lang
MSET key1 value1 key2 value 2 (批量设置)
MSET name1 wenlang name2 maomao
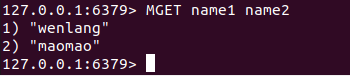
MGET key1 key2
MGET name1 name2
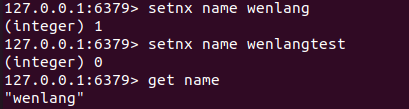
SETNX key value(不存在时才设置)
SETNX name wenlangSETNX name wenlangtest
GET name // 仍然为wenlang,因为第二次不会进行设置。
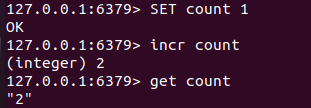
INCR KEY (让key对应的value加1)
SET count 1INCR countGET count // 2
Hash
命令:
HSET key field value
HSET member name wenlangHGET key field
HSET member name
HMSET key field1 value1 field2 value2 [field3 value3 …] 批量设置
hmset user 1:name wenlang 1:grade 100 2:name maomao 2:grade 99HMGET key field1 field2 [field3 field 4…]
hmget user 1:name 1:grade 2:name 2:grade
场景
电商购物车:
- 用户id为key
- 产品id为field
- 商品数量为value
购物车操作:
- 添加商品: hset cart:1001 10088 1
- 增加数量:incrby cart:1001 10088 1
- 商品总数:hlen cart:1001(hlen就是获取cart:1001下的字段总数,每一个字段对应一个商品,因此这里可以得到商品总数)
- 删除商品:hdel cart:1001 10088
- 获取购物车所有商品:hgetall cart:1001
List
命令
- LPUSH key value
左边添加
LPUSH myArray 1
LPUSH myArray 2
LPUSH myArray 3
// 最后得到3, 2, 1
- RPUSH key value
右边添加
- LRANGE key start end ```sql LRANGE myArray 0 10
1) “3” 2) “2” 3) “1”
4. LPOP key 左边弹出并返回
4. BLPOP key timeout如果有值,则从左边弹出,否则等待timeout秒,直到有值插入了。
<a name="pL2vl"></a>
## 场景
微信微博消息流<br />我关注了A,B,C<br />1) A发文章,消息为10000<br />LPUSH msg:我的ID 10000<br />2) B发文章,消息为10001<br />LPUSH msg:我的ID 10001<br />3) C发文章,消息为10002<br />LPUSH msg:我的ID 10002
这样子在我的文章列表里,分别为:10002, 10001, 10000倒叙,这也就是完成了最新的消息在最前面。
但是会有一个问题,当很多个人都关注了A,B,C的时候,每次发布一篇文章,就要给很多个人做LPUSH操作
```sql
LPUSH msg:用户1 10000
LPUSH msg:用户2 10000
LPUSH msg:用户3 10000
LPUSH msg:用户4 10000
LPUSH msg:用户5 10000
...
几百万个操作
Set
Set里的数据是不能重复的。
命令:
- SADD key value 添加进set中
例如,参加抽奖
SADD act:10001 333
SADD act:10001 444
SADD act:10001 555
SADD act:10001 666
SADD act:10001 777
SADD act:10001 888
- SMEMBERS key 获取key下的所有值
例如,获取所有参加抽奖的人
SMEMBERS act:10001
- SRANDOMMEMBER key count 随机取出count个元素(但是不删除)
例如:随机取出2个人,表示中奖了
SRANDOMMEMBER act:10001 2
- SPOP key count 随机移除并取出count个元素(会移除)
例如:随机取出两个人,表示中奖了,并且不再参加后续的抽奖
SPOP act:10001 2
- SREM key value (移除key下的某个value)
例如:取消点赞
// 用户333取消对消息1234的点赞
SREM like:1234 333
- SISMEMBER key value (判断value是否在Key中)
例如:判断是否点过赞
// 判断用户333是否给1234点过赞
SISMEMBER like:1234 333
- SCARD key (获取key下有多少个value)
例如:判断一共有多少个用户点过赞
SCARD like:1234
场景
可以看出来,set很适合做抽奖.
微信微博点赞。
集合运算
- SINTER set1 set2 set3 求交集
- SUNUION set1 set2 set3 求并集
- SDIFF set1 set2 set3 求差集,具体是set1减去set2和set3的并集
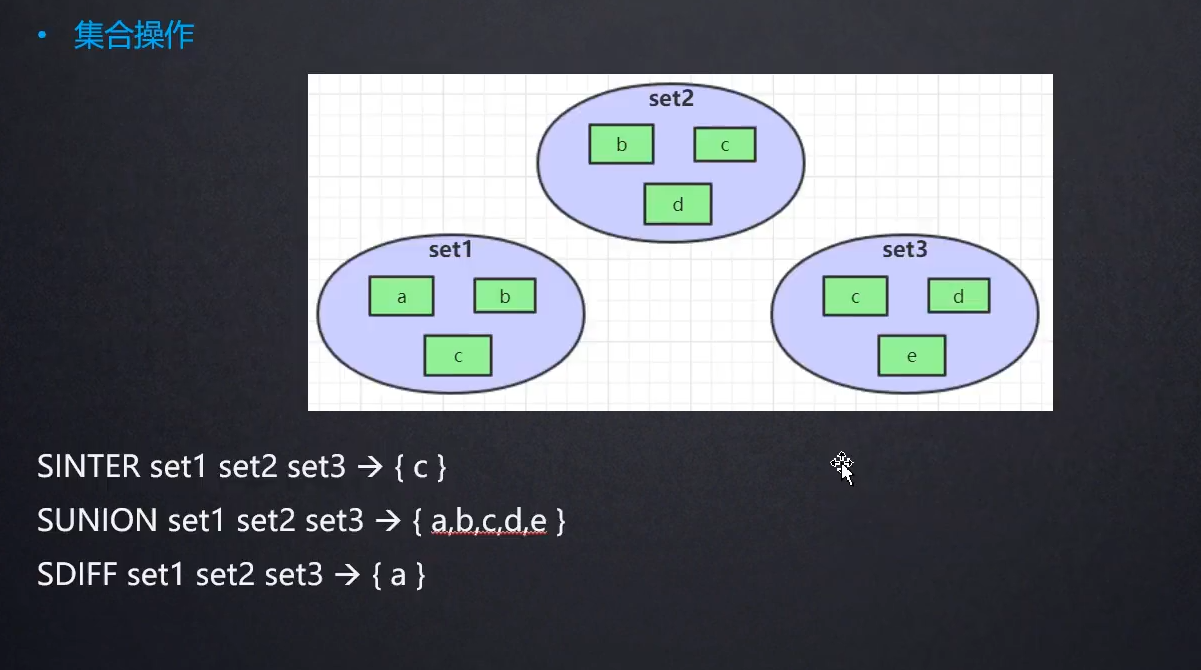
可以看到SDIFF:
{a, b, c} - {b, c, d, e} = {a}
集合运算的场景
- 共同关注:
wenlang -> {许昕, 张继科}
maomao -> {许昕, 樊振东}
那么SINTER wenlang maomao -> {许昕}
- 我可能认识的人:
SDIFF maomao wenlang -> 用毛毛的删掉我的,得到 {樊振东}, 我可能认识樊振东,因为毛毛跟我关系熟,毛毛关注的人可能我也是认识的。这里是可能。不一定精准。
ZSet
Zset是带分数的Set
命令:
- ZADD key score value
例如设置新闻的访问次数
ZADD hotNews:20190819 1 111
- ZINCRBY key score value
例如,访问次数加1:
ZINCRBY hotNews:20190819 1 111 -> id为111的新闻访问数 + 1
注意,如果value不存在,会创建一个value, 默认值为0, 然后再 + 1
- ZREVRANGE key start end WITHSCORE: 根据score, 倒序获得set里的值
例如:热搜的排行榜
- ZUNIONSTORE newSet numsOfSets set1 set2 …
合并多个set为一个新set, 新set的名字为newSet, 合并的时候,会将重复的value合并成一个,得到新的score为旧score的和。
例如,七日搜索排行榜:
ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 hotNews:20190814 ... 一共有七个

若有收获,就点个赞吧
0 人点赞
