准备
先创建测试表,往表里插入10W条数据
CREATE TABLE `employees` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',PRIMARY KEY (`id`),KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());‐‐ 插入一些示例数据drop procedure if exists insert_emp;delimiter ;;create procedure insert_emp()begindeclare i int;set i=1;while(i<=100000)doinsert into employees(name,age,position) values(CONCAT('zhuge',i),i,'dev');set i=i+1;end while;end;;delimiter ;call insert_emp();
示例1
优化前
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
虽然我们这里有索引可用,但是Mysql可能分析出来第一个字段就用范围查询,结果集应该很大,回表效率不高,还不如全表查询。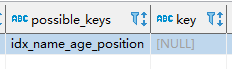
- possible_keys表示可能能使用的索引
- key表示实际上用的索引
- row表示扫描行数,但是并不是说扫描行数越多就越慢。
优化后
我们推测是因为可能需要回表,所以导致性能消耗过多,因此我们采用覆盖索引来防止回表。
EXPLAIN SELECT name, age, position FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
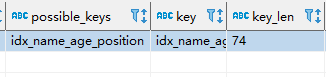
示例2
EXPLAIN SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager';
like kk% 一般都会走索引
与示例1中的大于不同,like kk%的模式一般都会走索引。
这里涉及一个概念,叫索引下推。
索引下推指的是,通过第一个索引(带like)的找到一个结果以后,去判断是否符合后面的条件,这样子就能保证我们得到的结果集相对较小。
Mysql如何选择合适的索引
EXPLAIN select * from employees where name > 'a';
EXPLAIN select * from employees where name > 'zzz' ;
上面两条查询语句,第一条不会走索引,第二条则会走索引,那么Mysql到底是如何决定走不走索引呢?
我们可以通过trace工具来看Mysql是如何运行的,开启该工具会影响性能,所以应该用完之后关闭。
set session optimizer_trace="enabled=on",end_markers_in_json=on; ‐‐开启trace
select * from employees where name > 'a' order by position;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
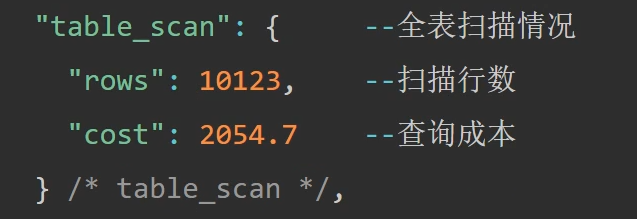
如上图,会去计算全表扫描成本。
也会去计算走索引的成本,如下图: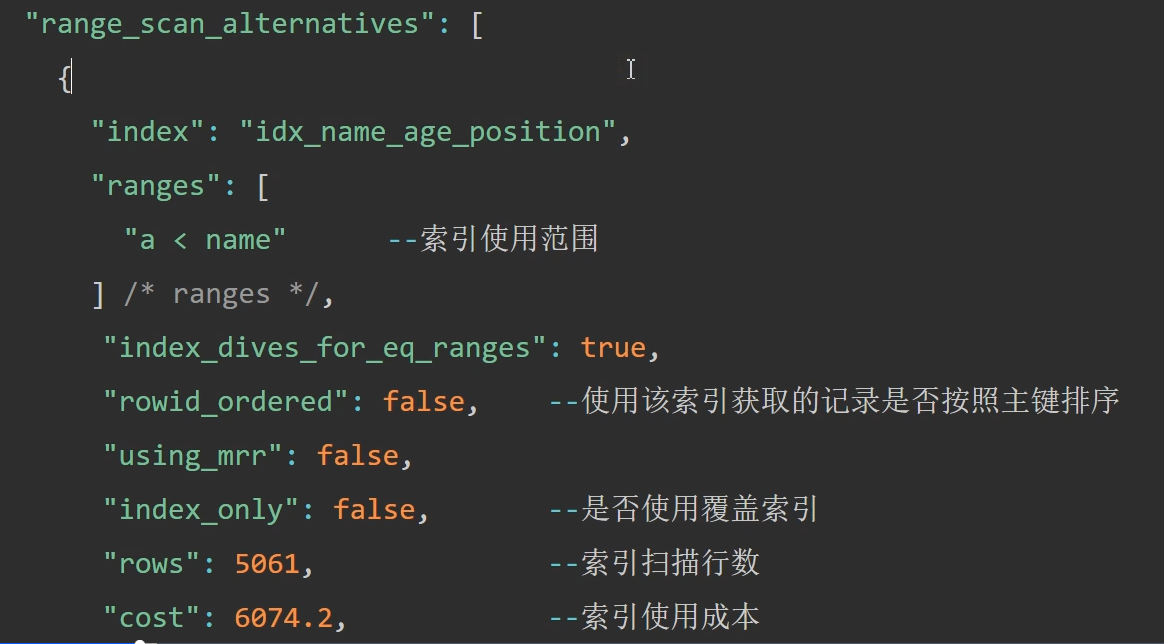
可以看到,虽然用索引扫描的行数少了,但是cost高了,所以不用索引。
常见SQL深入优化
order by 和 group by 优化
当使用order by 或者 group by时,去观察extra字段,如果是Using index, 就表示用了索引,不会体现在key_len这个长度上面。
Case 1:
原因:
这里用到了name,根据最左前缀原理,那么age必然有序,所以可以用索引;
Case 2:
这里跳过了age,此时position无序,不走索引,显示Using_filesort
Case 3:
用age加position同时进行排序,那么会走索引。先按age排序,再按position排序,所以可以走索引。
Case 4:
此时是先按照position排序,再按age排序,顺序反了,所以不走索引。
Case 5:
因为此时age = 18, 已经确定了,那么后面跟position去排序会走索引。
Case 6:
因为使用了降序,导致和索引的排序方式不同,不能使用索引。Mysql 8 以上支持降序使用索引。
Case 7:

相当于把两个结果集拼起来排序,age和position不一定有序,因而不使用索引。
Case 8: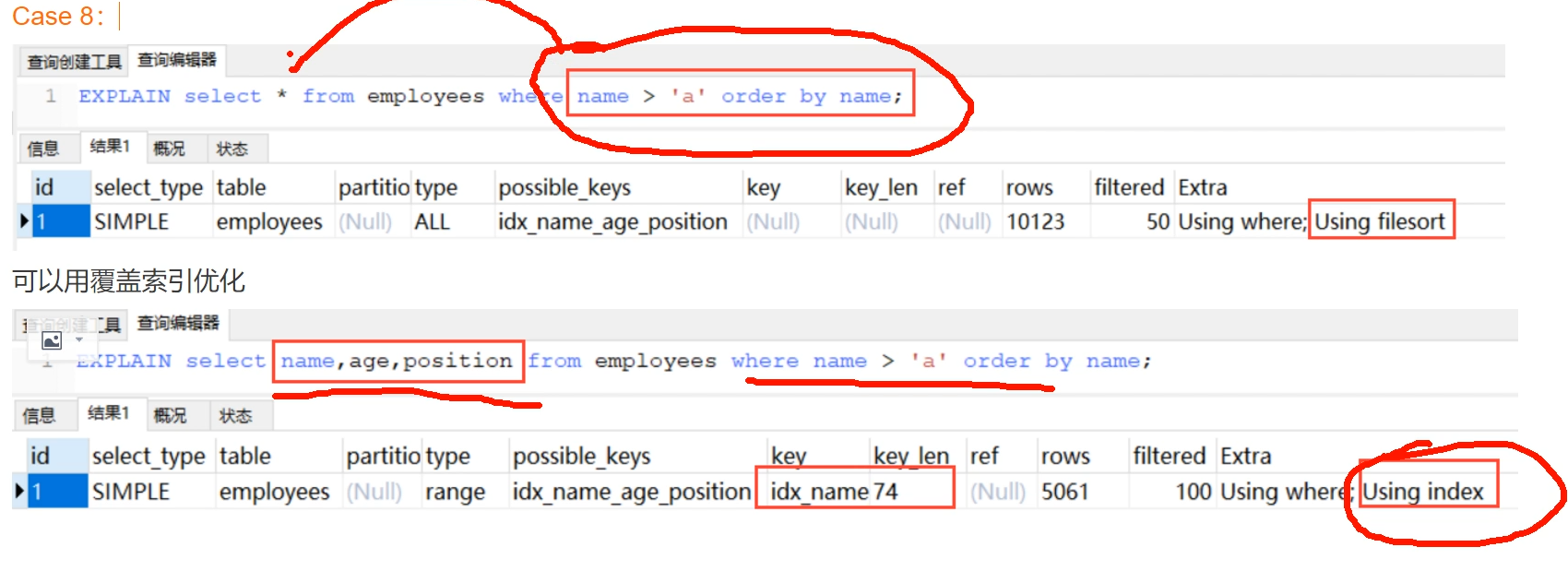
数据量太大,回表代价太大,不如全表扫描。因此用覆盖索引进行优化即可。
Using filesort文件排序(1:25:00)

若有收获,就点个赞吧
0 人点赞
