 ">
">
简介:本文章详细介绍了hadoop-2.6.0-cdh5.7.0在centos6.X上的部署流程以及生产中注意事项**
1、hadoop入门简介
1.1 Hadoop是apache开源的一个大数据组件,它包括大数据的计算存储以及资源和作业调度功能个,官网hadoop.apache.org
广义: 以apache hadoop软件为主的生态圈(hive zookeeper spark hbase等)狭义: apache hadoop软件

1.2生产上hadoop版本使用情况
1.x 企业不用2.x 主流3.x 没有企业敢用a.采坑b.很多公司都是CDH5.x部署大数据环境 (www.cloudera.com),本文章以hadoop-2.6.0-cdh5.7.0版本进行部署的

1.3hadoop的三大组成部分
hdfs:存储,分布式文件系统mapreduce:计算 但是企业不用(开发难度高 代码量大 计算慢)yarn:资源(CPU memory)和作业调度

2、下载安装包。
2.1百度搜索 cdh tar,打开第一个链接(http://archive.cloudera.com/cdh5/cdh/5/),该地址为cdh的软件仓库。
2.2搜索hadoop-2.6.0-cdh5.7.0,打开进入的是cdh版hadoop2.6.0的导航界面,该界面与hadoop官网的导航界面非常的类似,包含了详细的安装教程


2.3返回chd软件仓库界面,选择对应的tar包点击下载
3、安装前置条件
阅读cdh版hadoop2.6.0官网可知:3.1需安装JDK,具体的版本的hadoop对应JDK版本有详细的列表,生产中错误的JDk版本会有可能导致问题,如已经发现的某个JDK版本在HBase使用时会发生内存泄漏,生产严格按照要求来,采坑重要!!。3.2需安装ssh软件,并配置ssh免密码互信。

4、创建hadoop用户和上传hadoop软件
useradd hadoo #创建hadoop用户,遵循一个组件由一个用户管理原则su - hadooppmkdir app data software lib source #创建安装/数据/软件包/jar包/源码等文件夹cd softwarerz #将下载好的搜索hadoop软件以及jdk上传到software目录

5、使用root用户安装JDK
5.1解压安装
exit #退出hadoop用户java -version #查看系统是否已经默认安装了jdkrpm -qa | grep jdk #查询具体安装那些jdk软件yum -y remove XXX #将安装的jdk卸载,xxx为rpm查询的结果mkdir /usr/java # java安装目录,必须是该目录,CDH环境会识别它,采坑重要mkdir /usr/share/java #部署CDH需要mysql jdbc jar包,放在这里,采坑重要tar -zxvf /home/hadoop/software/jdk-8u152-linux-x64.tar.gz -C /usr/java/ #解压cd /usr/javall #仔细查看,很奇怪,发现拥有者是uucp,目前只发现jdk解压会这样,这是一个坑,生产特定情况下会出现问题,需要修改拥有者,采坑重要chown -R root:root jdk1.8.0_152 #修改拥有者以及所属组#扩展知识,uucp用户查看passwd文件,可知其解释器是/sbin/nologin,表示无法登录即无法su,生产中若遇到这样的账户,且必须要登录,可将/sbin/nologin改为/bin/bash

5.2 添加环境变量
vim /etc/profile #编辑环境变量文件,追加如下内容:export JAVA_HOME=/usr/java/jdk1.8.0_152export JRE_HOME=$JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JER_HOME/lib:$CLASSPATHexport PATH=$JAVA_HOME/bin:$JER_HOME/bin:$PATH保存退出。source /etc/profile #更新环境变量java -version #这时候会发现java已经变成看我们想要的

6、配置ssh免密码互信
su - hadoopssh-keygen #连续四个回车,生产~/.ssh文件夹cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #将公钥放到一个文件夹中chmod 600 authorized_keys #cdh操作指南这里没提示该步骤,但是hadoop官网有,不修改权限是后续不会成功地,采坑重要ssh localhost date #表示远程localhost机器执行date命令,不是远程过去,第一次远程需要输入yes确认

7、部署hdfs
7.1解压软件
su - hadooptar -zxvf ~/software/hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app/ #解压cd ~/app/hadoop-2.6.0-cdh5.7.0/ll #解压后的目录如下,大数据组件目录一般都有相似结构bin # 客户端相关可执行脚本bin-mapreduce1 #cloudera #etc # 配置文件目录,一般都是confexamples # 样例examples-mapreduce1 #include #lib #jar包libexec #LICENSE.txt #NOTICE.txt #README.txt #sbin # 服务端相关可执行脚本share #共享文件src #源码

7.2 编辑hadoop-env.sh配置文件
vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hadoop-env.sh #编辑该文件添加或修改如下配置,java安装家目录以及hadoop安装的家目录。export JAVA_HOME=/usr/java/jdk1.8.0_152export HADOOP_PREFIX=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0

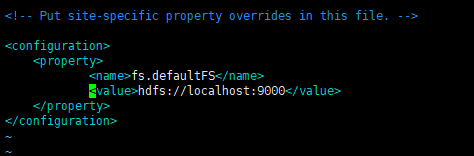
7.3 编辑core-site.xml配置文件
vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml #编辑该文件添加或修改如下配置,并保存


7.4 编辑hdfs-site.xml配置文件
vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hdfs-site.xml #编辑该文件添加或修改如下配置,并保存

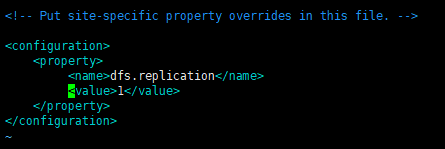

7.5 启动hdfs
~/app/hadoop-2.6.0-cdh5.7.0/bin/hdfs namenode -format #格式化文件系统,等待一会后出现successfully formatted日志信息,表示格式化成功~/app/hadoop-2.6.0-cdh5.7.0/sbin/start-dfs.sh #启动hdfs,观看控制台信息,得到如下信息:1)、日志中显示分别启动了namenode、datanode、secondarynamenode三个进程,可用jps查看。2)、启动secondary namenodes时提示我们要连接,因为该进程是在0.0.0.0服务器启动。上面我们只在localhost机器做了一次ssh登录,所以第一次ssh 0.0.0.0免秘钥时是需要yes确认的。3) hadoop的日志为在~/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-用户名-进程名-主机名称.out

通过 http://ip:50070/ 可访问hdfs界面。
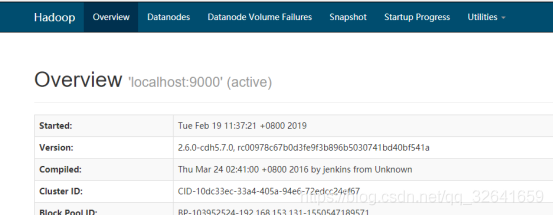

7.6 配置hadoop环境变量
su - hadoopvim ~/.bash_profile # 配置hadoop环境变量,追加如下内容export HADOOP_PREFIX=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0export PATH=$HADOOP_PREFIX/bin:$PATHsource ~/.bash_profile

7.7 hdfs命令
hdfs dfs #查找hdfs命令帮助,和linux及其相似hdfs dfs -ls / #列出/目录下所有文件,很类似于linux 的ls

8、优化-以本机hostname机器启动hdfs
重要,步骤7启动hdfs,从日志中可以看出是以localhost和0.0.0.0机器启动的,生产中这样是不行的,尤其是在集群部署时,必须配置为主机名称,也不能为ip地址,这是规范
8.1 hdfs三大守护进程简介
Jps #可展示运行的三大进程nameNode 简称nn,这里存储了文件的元信息,维护hdfs目录结构Secondary nameNode 万年老二,备份nameNode,当namendoe挂了时它顶上dateNode 真正干活的进程,即文件读写由该进程完成

8.2hadoop配置文件简介
cd ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop #配置文件存放目录llhadoop-env.sh #配置jdk目录以及hadoop安装目录 重要hdfs-site.xml #hdfs配置的地方,如配置副本数 重要mapred-env.sh|mapred-site.xml.template #配置MR的地方,一般不需要配置yarn-env.sh #yarn环境配置的地方,一般不需要配置yarn-site.xml #yarn相关配置的地方 重要core-site.xml #是对yarn|hdfs|mr .xml 核心的和共有 配置

8.3停止hdfs。
su - hadoop~/app/hadoop-2.6.0-cdh5.7.0/sbin/stop-dfs.sh #停止hdfs,从日志中可看出每个进程由哪台机器进行关闭

8.4修改相应配置文件
exit #退出hadoop用户,使用root用户vim /etc/hosts #编辑hosts文件配置主机映射(如:192.168.153.131 hadoop002),若已经配置过,则跳过,这里一定要注意,第一行和第二行不能删改,采坑重要su - hadoopvim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml #将配置中的<value>hdfs://localhost:9000</value>的localhost用hadoop002替换,更改了nameNode启动机器地址vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/slaves #更改datanode启动机器地址,将localhost使用hadoop002替换,若以后多个dataNode节点,只需用逗号分隔即可。vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hdfs-site.xml #修改secondarynamenode添加如下所示的配置内容,具体配置信息查询官网得知。<property><name>dfs.namenode.secondary.http-address</name><value>hadoop002:50090</value></property><property><name>dfs.namenode.secondary.https-address</name><value>hadoop002:50091</value></property>~/app/hadoop-2.6.0-cdh5.7.0/sbin/start-dfs.sh #此时启动会发现三个进程都是以hadoop002启动的

9、优化-修改hadoop进程pid文件存放位置。
采坑重要,Linux在/tmp目录会定期删除一些文件和文件夹, 如30天周期,故hadoop进程pid文件存放/tmp目录下时,是有被删除风险,故需要重新修改pid文件存放位置
mkdir /data/tmp #创建pid文件存储目录chmod -R 777 /data/tmpvim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hadoop-env.sh #编辑,修改原有的为export HADOOP_PID_DIR=/data/tmp~/app/hadoop-2.6.0-cdh5.7.0/sbin/stop-dfs.sh #~/app/hadoop-2.6.0-cdh5.7.0/sbin/start-dfs.sh #重启hadoop进程

10、部署yarn
yarn进程是用于资源和工作调度管理,需要进行部署,mapreduce是运行的jar包,不需要部署,mapreduce一般是跑在yarn上
10.1修改相应配置文件
编辑mapred-site.xml,设置mr运行的环境为yarnsu - hadoopcp ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml.template ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml #复制一份配置文件vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml #添加如下配置<property><name>mapreduce.framework.name</name><value>yarn</value></property>编辑yarn-site.xml文件vim ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site.xml #添加如下配置<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>

10.2 启动yarn
~/app/hadoop-2.6.0-cdh5.7.0/sbin/start-yarn.sh #启动yarnjps #这时会发现多出两个进程 ResourceManager和NodeManagerResourceManager :资源管理者,老大NodeManager :节点管理者,老二通过http://ip:8088/ 可查看yarn运行界面

11、运行mapreudce进行词频统计
11.1、简介
mapreudce分为map 映射,reduce 规约两种操作,注意不一定是map执行完后才执行reduce,可能map执行一半,reduce就开始运行了,实际计算很复杂。
11.211、进行词频统计
find ./ -name '*example*.jar' #查询hadoop提供的样例jar包,找到我们需要的jarhadoop jar ./app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar #查看有哪些案列,我们需要的wordcount案列进行词频统计#创建两个log文件并上传hdfscd ~/data/vim a.logcat a.logzuozeJgedashuadaishiqi1[hadoop@hadoop002 data]$ cat b.logcat: b.log: No such file or directory[hadoop@hadoop002 data]$ vim b.log[hadoop@hadoop002 data]$ cat b.logruozeruozedashuwskwsk123hdfs dfs -mkdir -p /wordcount/inputdata #创建输入数据文件夹hdfs dfs -mkdir -p /wordcount/inputdatahdfs dfs -put b.log /wordcount/inputdatahadoop jar ~/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /wordcount/inputdata /wordcount/outputdata1 #提交mr作业到yarn,运行job至完成需要等待一会儿hdfs dfs -cat /wordcount/outputdata1/part-r-00000 #查看词频统计结果1 22 13 1Jge 1adai 1dashu 2ruoze 2shiqi 1wsk 2zuoze 1


若有收获,就点个赞吧
0 人点赞
