1.MapReduce简介
大数据最早的分布式计算框架,如今企业开发已不会直接使用java代码写MR代码运行作业,因为只有map、reduce两种函数,代码很复杂很累赘,且是基于磁盘进行计算的,非常慢,主流是spark,但是很有学习借鉴意义。
2.Container简介
1)运行在nm节点上的单独进程,执行任务时才会被分配。2)由一定的内存和数量的vcore组成,是逻辑概念3)一个Container上运行的是某个作业的部分task任务4)一个nm可以运行多个container

3.vcore简介
虚拟的cpu,即逻辑cpu,一般pcore与vcore比列设置为1:2,这涉及到了每个pcore的超线程技术,理论上能够支持双线程。最新的hadoop已经将比列设置为1:1,让计算能够有充分的资源可使用。
4.MR on yarn 架构
4.1架构图
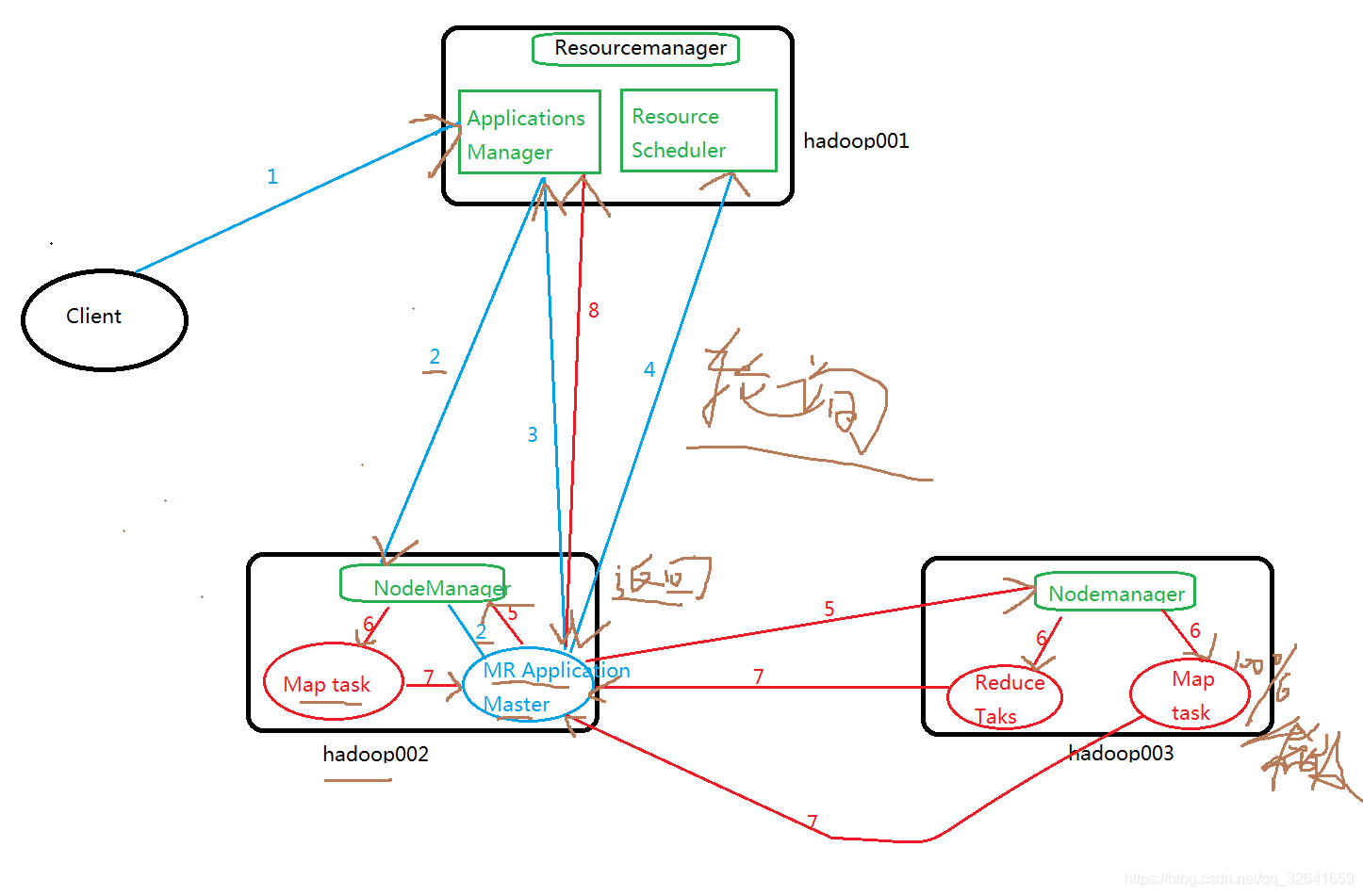
 4.2相关角色介绍
4.2相关角色介绍
ResourceManager 资源作业管理者
Applications Manager 作业管理,是所有作业的老大,web界面信息从这里查询
Resource Scheduler 资源调度
NodeManager 节点者
ApplicationsMaster:某个job的老大,他来申请资源以及管理和监控整个作业生命周期,运行在Container上
Container:运行某个作业的全部或部分task
4.3流程详解
1)用户向yarn rm apps manager提交作业(job),其中包括applicationMaster程序、、启动applicationMaster命令等。
2)RM为该job分配第一个容器,并与对应的NM通信,要求它运行这个容器并在这个容器中去启动该job的MR applicationMaster程序。
3)applicationMaster首先向Applications Manager注册,用户就可以直接在web界面查看job的整个运行状态和日志。
4)applicationMaster向Resource Scheduler 采用轮询的方式通过RPC协议去申请和领取资源列表
5)一旦applicationMaster申请到资源的后,便与对应的NM节点通信,要求启动任务。
6)NM为任务task设置好运行环境(环境变量、jar包等),将任务的启动命令写在一个脚本文件中,并通过这个脚本【启动任务】;
7)各个task通过rpc向applicationMaster汇报自己的状态和进度。以让applicationMaster随时掌握各个任务的运行状态,从而可以在任务运行时重新启动任务。则web界面可以实时查看job的当前的运行状态。
8)job运行完成后,applicationMaster向RM注销并关闭自己。
总结步骤:
第一步:启动applicationMaster
第二步:由applicationMaster创建job,为它申请资源,并监控它的整个运行过程,直到运行完成。
5.MR 与 yarn常用命令
通常我们是在web界面上管理job作业,但是有时如web挂了,也是有必要使用mr以及yarn命令管理任务。
mapred #查看命令帮助mapred job #查看mapred job帮助mapred job -list # 显示正在运行的所有jobmapred job -kill job_1550603730963_0009 #杀死jobmapred job -status job_1550603730963_0009 #查看某个job状态mapred job -logs job_1550603730963_0009 #查看该作业日志yarn #查看命令帮助yarn application #查看job相关命令帮助yarn application --list #查询平台正在运行的作业yarn logs -applicationId job_1550603730963_0009 #查看该作业日志更多命令需要仔细阅读命令帮助。

6.Shuffle剖析
shuffle是数据计算时的某个阶段,中文是洗牌的意思。理解方式:1 介于map和reduce动作之间的动作 2.shuffle就是数据进行网络IO传输阶段 。Shuffle是一个非常耗时的动作,尽量去减少不必要的shuffle操作。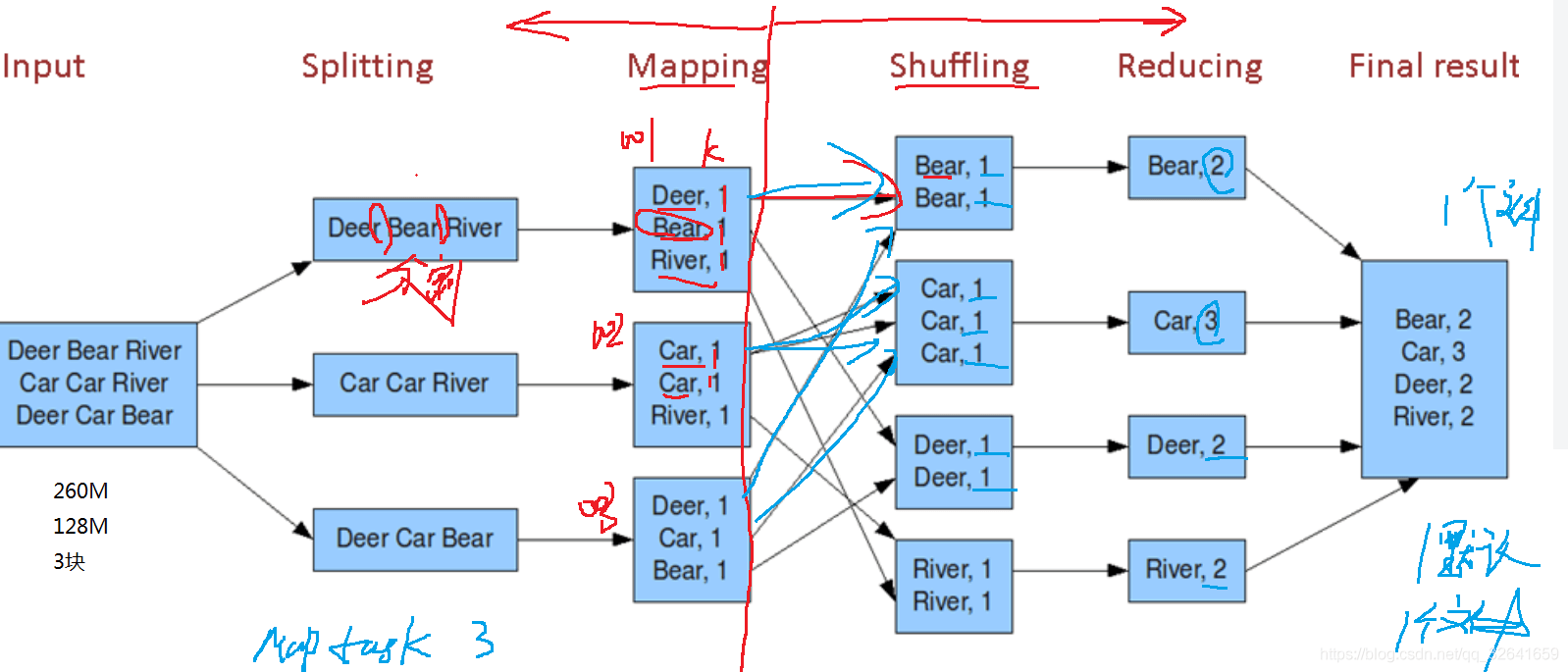

如上图,shuffle处于map和reduce之间,shuffle时几乎所有的数据都进行了IO传输。

若有收获,就点个赞吧
0 人点赞
