摘要:本文详细记载hadoop-2.6.0-cdh5.7.0在生产中HA集群部署流程,可用于学习以及生产环境部署借鉴参考。
@[toc]
1.环境需求以及部署规划
1.1 硬件环境
三台阿里云主机、每台2vcore、4G内存。
1.2 软件环境:
| 组件名称 | 组件版本 |
|---|---|
| Hadoop | Hadoop-2.6.0-cdh5.7.0 |
| Zookeeper | Zookeeper-3.4.5 |
| jdk | Jdk-8u45-linux-x64 |
1.3 进程部署规划图:
| 主机名称 | ZK | NN | ZkFC | JN | DN | RM(ZKFC) | NM |
|---|---|---|---|---|---|---|---|
| Hadoop001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Hadoop002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Hadoop003 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
注意:1.、1表示部署在该主机上部署相应的进程,0表示不部署
2.Hadoop Ha架构剖析
2.1 HDFS HA架构详解
请参考:https://blog.csdn.net/qq_32641659/article/details/88964464
2.2 YARN HA架构详解
请参考:https://blog.csdn.net/qq_32641659/article/details/88965006
3.HA部署流程
3.1 上传相关安装包
安装包百度网盘地址:
安装包百度网盘地址:链接:https://pan.baidu.com/s/1NfOv2ODV9ktKXM8zfaofzQ提取码:mgwr复制这段内容后打开百度网盘手机App,操作更方便哦
添加用户以及上传安装包:
#####三台机器时执行如下命令########useradd hadoopsu - hadoopmkdir app soft lib source dataexityum install -y lrzsz #安装lrzsz软件su - hadoopcd ~/soft/rz #上传安装包,先上传到hadoop001,个人测试xftp传输速度大于rz#scp,将安装包传到另外两台机器,注意使用是内网ipscp -r ~/soft/* root@172.19.121.241:/home/hadoop/softscp -r ~/soft/* root@172.19.121.242:/home/hadoop/soft[hadoop@hadoop001 soft]$ lltotal 490792-rw-r--r-- 1 root root 311585484 Apr 3 15:52 hadoop-2.6.0-cdh5.7.0.tar.gz-rw-r--r-- 1 root root 173271626 Apr 3 15:49 jdk-8u45-linux-x64.gz-rw-r--r-- 1 root root 17699306 Apr 3 15:50 zookeeper-3.4.6.tar.gz
3.2 关闭防火墙
##三台机器都需要执行如下命令#清空防火墙规则[root@hadoop001 ~]# iptables -F[root@hadoop001 ~]# iptables -L#永久关闭防火墙[root@hadoop001 ~]# service iptables stop[root@hadoop001 ~]# chkconfig iptables off[root@hadoop001 ~]# service iptables statusiptables: Firewall is not running.
3.3 配置host文件
三台机器配置相同的host文件,如下(只列举了hadoop001):
#采坑1:第一第二行的内容永远不要自作聪明去改动,不然后面会遇坑的[root@hadoop001 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6172.19.121.243 hadoop001 hadoop001172.19.121.241 hadoop002 hadoop002172.19.121.242 hadoop003 hadoop003[root@hadoop001 ~]# ping hadoop001[root@hadoop001 ~]# ping hadoop002[root@hadoop001 ~]# ping hadoop003
3.4 配置SSH免密码通信
三台机器各自生成秘钥:
[root@hadoop001 ~]# su - hadoop[hadoop@hadoop001 ~]$ rm -rf ./.ssh[hadoop@hadoop001 ~]$ ssh-keygen #连续生产四个回车[hadoop@hadoop001 ~]$ cd ~/.ssh[hadoop@hadoop001 .ssh]$ lltotal 8-rw------- 1 hadoop hadoop 1675 Apr 3 16:26 id_rsa-rw-r--r-- 1 hadoop hadoop 398 Apr 3 16:26 id_rsa.pub
合成公钥(注意命令操作的机器):
[hadoop@hadoop001 .ssh]$ cat id_rsa.pub >>authorized_keys[hadoop@hadoop002 .ssh]$ scp -r ~/.ssh/id_rsa.pub root@172.19.121.243:/home/hadoop/.ssh/id_rsa2[hadoop@hadoop003 .ssh]$ scp -r ~/.ssh/id_rsa.pub root@172.19.121.243:/home/hadoop/.ssh/id_rsa3[hadoop@hadoop001 .ssh]$ lltotal 20-rw-rw-r-- 1 hadoop hadoop 398 Apr 3 16:37 authorized_keys-rw------- 1 hadoop hadoop 1675 Apr 3 16:37 id_rsa-rw-r--r-- 1 root root 398 Apr 3 16:38 id_rsa2-rw-r--r-- 1 root root 398 Apr 3 16:38 id_rsa3-rw-r--r-- 1 hadoop hadoop 398 Apr 3 16:37 id_rsa.pub[hadoop@hadoop001 .ssh]$ cat ./id_rsa2 >> authorized_keys[hadoop@hadoop001 .ssh]$ cat ./id_rsa3 >> authorized_keys[hadoop@hadoop001 .ssh]$ cat authorized_keysssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAwZuESml5aeRFyAmZPhzh0WG3waHqGChV4SHWBkjHrkcisLpqpXXotEn0Ap1yWuPYCUKNLIgyLD8tSubnLyj5nNdOXPYnzSyTw0NVIKzKkhLqrYMnpTrckodGjwkhSlaZbIRngBHGB7cUOW8AaWeA79UzEydr1/8Q/arizt82R/K8+t0SAIsk1MUu7+oUGJAzPXpNU76pq69ARb/hJUs0xRMMjOFetqrp8dh8pHoBjgcgUX+fyc5FB/dqJlaCXNJDmNtWclOo8flprB27qj4+1jfCs78wU6AAfewQqo4jJ/2NoD527Vu/SDGysQdlsKpSYBygLB1+/oR46sH1iUJTew== hadoop@hadoop001ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAykZ7nWRo+dmiMuaTALybK1S7XI/pgZgbpTmQAw3IIC1CwFWVZIRuF8eSCL4wgj16pKbKcfczN/9aYhOq0zsUgaa8LlzI6D2DKU1hzak43dCFcnNM/lBkF3QrkE0m9jfM6wmVozdflvRiM+GygEhydfbWSpJcMmPCmV+scRUFjRuH0AuWlwm7sRBxXbK3w4PpWfMF0ie4ZEbviO4PK+E3BxL4xT93N3fELF0s1ayK0mHOfDGBEkFBRp5vIVU//puFU0pW/2/db/laiA8xO1kHLPaFRwVl/I17yNkGUJjF0goeavtVMkxwckd5FsqFIdVecPZ5ReyObbasjbQlvL4uFQ== hadoop@hadoop002ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAw5v6nMHGJmzVHgC1gg/3QbP8qT2ljoBYcS9WaMdSNUjG/WVfvcRWSA1KlACwjG+8RmlHZkR4OTVAIBlMPMDObhjXK6J4hKGicINNsfB+E0etPczDneFCxZHwf9UQ/7J8g/KoAdmE+ROUWKzdw+q2QOcY5Yhbn7FSzF28CK826HPi5L6WXQlBolvlI4x6hn7vscwqpI7cu2YFLkp2bk5lEoatXShSxHi2MTxoyqrtuSpYZhybuExfDjDOPOXX0zpP/Gj7cUHTRuJrUtqiq+G71L+BhmD5cIsTwguBEXrWF+lsXOXTx2TyBXtc7kbvArE6XKee2sjshE52Kn7ko6ZhtQ== hadoop@hadoop003[hadoop@hadoop001 .ssh]$ rm -rf id_rsa2 id_rsa3[hadoop@hadoop001 .ssh]$ scp -r ~/.ssh/authorized_keys root@172.19.121.241:/home/hadoop/.ssh/[hadoop@hadoop001 .ssh]$ scp -r ~/.ssh/authorized_keys root@172.19.121.242:/home/hadoop/.ssh/#很重要,若authorized_keys属于非root用户必须将权限设置为600[hadoop@hadoop001 ~]$ chmod 600 ./.ssh/authorized_keys
互相ssh免秘钥测试,用户第一次ssh会有确认选项
规则:ssh 远程机器执行date命令,不需要输入密码则,则ssh免密码配置成功[hadoop@hadoop001 ~]$ ssh hadoop001 date[hadoop@hadoop001 ~]$ ssh hadoop002 date[hadoop@hadoop001 ~]$ ssh hadoop003 date[hadoop@hadoop002 ~]$ ssh hadoop001 date[hadoop@hadoop002 ~]$ ssh hadoop002 date[hadoop@hadoop002 ~]$ ssh hadoop003 date[hadoop@hadoop003 ~]$ ssh hadoop001 date[hadoop@hadoop003 ~]$ ssh hadoop002 date[hadoop@hadoop003 ~]$ ssh hadoop003 date
3.5 部署JDK
三台机器同时执行如下命令
#采坑1: 必须为/usr/java/,该目录是cdh默认的jdk目录,若不为该目录,后面一定会采坑。[root@hadoop003 ~]# mkdir /usr/java/[root@hadoop001 ~]# tar -zxvf /home/hadoop/soft/jdk-8u45-linux-x64.gz -C /usr/java/#采坑2:权限必须变更,jdk解压的所属用户很奇怪,后续使用中可能会报类找不到错误[root@hadoop001 ~]# chown -R root:root /usr/java
配置JDK环境变量
[root@hadoop001 ~]# vim /etc/profile #追加如下两行配置export JAVA_HOME=/usr/java/jdk1.8.0_45export PATH=$JAVA_HOME/bin:$PATH[root@hadoop001 ~]# source /etc/profile #更新环境变量文件[root@hadoop001 ~]# java -versionjava version "1.8.0_45"Java(TM) SE Runtime Environment (build 1.8.0_45-b14)Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)[root@hadoop001 ~]# which java/usr/java/jdk1.8.0_45/bin/java
3.6 部署ZK集群
解压ZK安装包
[root@hadoop001 ~]$ su -hadoop[hadoop@hadoop001 ~]$ tar -zxvf ~/soft/zookeeper-3.4.6.tar.gz -C ~/app/[hadoop@hadoop001 ~]$ ln -s ~/app/zookeeper-3.4.6 ~/app/zookeeper
添加环境变量
#编辑hadoop用户环境变量文件添加如下内容[hadoop@hadoop001 bin]$ vim ~/.bash_profileexport ZOOKEEPER_HOME=/home/hadoop/app/zookeeperexport PATH=$ZOOKEEPER_HOME/bin:$PATH[hadoop@hadoop001 bin]$ source ~/.bash_profile[hadoop@hadoop001 bin]$ which zkServer.sh~/app/zookeeper/bin/zkServer.sh
修改zookeeper配置
[hadoop@hadoop001 conf]$ mkdir ~/data/zkdata/data[hadoop@hadoop001 app]$ cd ~/app/zookeeper/conf/[hadoop@hadoop001 conf]$ cp zoo_sample.cfg zoo.cfg#添加或修改如下配置[hadoop@hadoop001 conf]$ vim zoo.cfgdataDir=/home/hadoop/data/zkdata/dataserver.1=hadoop001:2888:3888server.2=hadoop002:2888:3888server.3=hadoop003:2888:3888#在数据目录创建myid文件,并将标识1传入[hadoop@hadoop001 conf]$ cd ~/data/zkdata/data/[hadoop@hadoop001 data]$ echo 1 >myid#将配置文件复制一份到hadoop002、hadoop003[hadoop@hadoop001 data]$ scp ~/app/zookeeper/conf/zoo.cfg hadoop002:~/app/zookeeper/conf/[hadoop@hadoop001 data]$ scp ~/app/zookeeper/conf/zoo.cfg hadoop003:~/app/zookeeper/conf/[hadoop@hadoop001 data]$ scp ~/data/zkdata/data/myid hadoop002:~/data/zkdata/data/[hadoop@hadoop001 data]$ scp ~/data/zkdata/data/myid hadoop003:~/data/zkdata/data/#更改hadoop002、hadoop003的myid文件,将标识改为如下内容[hadoop@hadoop002 ~]$ cat ~/data/zkdata/data/myid2[hadoop@hadoop003 ~]$ cat ~/data/zkdata/data/myid3
启动zk集群,三台集群都需要执行如下命令:
[hadoop@hadoop001 data]$ cd ~/app/zookeeper/bin[hadoop@hadoop001 bin]$ ./zkServer.sh start
查询ZK集群状态:
#查询zk节点状态[hadoop@hadoop003 bin]$ ./zkServer.sh status#查看QuorumPeerMain进程是否启动[hadoop@hadoop002 bin]$ jps -l3026 org.apache.zookeeper.server.quorum.QuorumPeerMain
若发现集群状态异常,异常的报错以及解决方法如下:
#异常信息[hadoop@hadoop003 bin]$ ./zkServer.sh statusJMX enabled by defaultUsing config: /home/hadoop/app/zookeeper/bin/../conf/statusgrep: /home/hadoop/app/zookeeper/bin/../conf/status: No such file or directorymkdir: cannot create directory `': No such file or directoryStarting zookeeper ... ./zkServer.sh: line 113: /zookeeper_server.pid: Permission deniedFAILED TO WRITE PID###查询日志,观察详细的错误信息#寻找日志文件,日志文件名称是通过搜索启动脚本发现的[hadoop@hadoop001 bin]$ find /home/hadoop -name "zookeeper.out"/home/hadoop/app/zookeeper-3.4.6/bin/zookeeper.out[hadoop@hadoop001 bin]$ vim /home/hadoop/app/zookeeper-3.4.6/bin/zookeeper.out2019-04-03 22:23:55,976 [myid:] - INFO [main:QuorumPeerConfig@103] - Reading configuration from: /home/hadoop/app/zookeeper/bin/../conf/status2019-04-03 22:23:55,979 [myid:] - ERROR [main:QuorumPeerMain@85] - Invalid config, exiting abnormallyorg.apache.zookeeper.server.quorum.QuorumPeerConfig$ConfigException: Error processing /home/hadoop/app/zookeeper/bin/../conf/statusat org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:123)at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:101)at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)Caused by: java.lang.IllegalArgumentException: /home/hadoop/app/zookeeper/bin/../conf/status file is missingat org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:107)... 2 moreInvalid config, exiting abnormally#简单分析日志,发现读取的配置文件竟然是/home/hadoop/app/zookeeper/bin/../conf/status文件,很是奇怪(可能是我一开始没有配置环境变量的原因),重启 集群。 发现一切正常。hadoop002 是lead节点,其它为follower节点[hadoop@hadoop002 bin]$ ./zkServer.sh statusJMX enabled by defaultUsing config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfgMode: leader
3.6 部署HADOOP HA集群
解压并添加环境变量,三台机器同时执行
[hadoop@hadoop001 bin]$ tar -zxvf ~/soft/hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app[hadoop@hadoop001 bin]$ ln -s ~/app/hadoop-2.6.0-cdh5.7.0 ~/app/hadoop[hadoop@hadoop001 bin]$ vim ~/.bash_profile[hadoop@hadoop001 bin]$ cat ~/.bash_profile #添加或修改为如下内容PATH=$PATH:$HOME/binexport PATHexport ZOOKEEPER_HOME=/home/hadoop/app/zookeeperexport HADOOP_HOME=/home/hadoop/app/hadoopexport PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH[hadoop@hadoop001 bin]$ source ~/.bash_profile #更新环境变量
创建数据目录,三台机器同时执行
[hadoop@hadoop001 ~]$ mkdir -p ~/app/hadoop-2.6.0-cdh5.7.0/tmp #创建临时目录,由core-site.xml文件配置hadoop.tmp.dir所配置[hadoop@hadoop003 ~]$ mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/name #创建hdfs的namenode数据(fsimage)目录,由hdfs-site.xml的dfs.namenode.name.dir所配置[hadoop@hadoop003 ~]$ mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/data #创建hdfs的datanode数据目录,由hdfs-site.xm所配置[hadoop@hadoop003 ~]$ mkdir -p /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/jn #创建hdfs的journalnode数据目录,由hdfs-site.xm所配置
修改五个配置文件,三台机器同时执行
[hadoop@hadoop003 hadoop]$ cd ~/app/hadoop/etc/hadoop[hadoop@hadoop003 hadoop]$ rm -rf core-site.xml hdfs-site.xml yarn-site.xml slaves #删除已有的配置文件[hadoop@hadoop003 hadoop]$ rz[hadoop@hadoop003 hadoop]$ scp core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves hadoop001:/home/hadoop/app/hadoop/etc/hadoop[hadoop@hadoop003 hadoop]$ scp core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves hadoop002:/home/hadoop/app/hadoop/etc/hadoop[hadoop@hadoop003 hadoop]$ cat slaves #注意 这三行与最后一行并不连在一起,采坑hadoop001hadoop002hadoop003[hadoop@hadoop003 hadoop]$
五个配置文件百度网盘链接如下:
链接:https://pan.baidu.com/s/1lQCWc62nccn61gHEztSbyg提取码:2rgm复制这段内容后打开百度网盘手机App,操作更方便哦
core-site.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!--Yarn 需要使用 fs.defaultFS 指定NameNode URI --><property><name>fs.defaultFS</name><value>hdfs://ruozeclusterg6</value></property><!--==============================Trash机制======================================= --><property><!--多长时间创建CheckPoint NameNode截点上运行的CheckPointer 从Current文件夹创建CheckPoint;默认:0 由fs.trash.interval项指定 --><name>fs.trash.checkpoint.interval</name><value>0</value></property><property><!--多少分钟.Trash下的CheckPoint目录会被删除,该配置服务器设置优先级大于客户端,默认:0 不删除 --><name>fs.trash.interval</name><value>1440</value></property><!--指定hadoop临时目录, hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这>个路径中 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/tmp</value></property><!-- 指定zookeeper地址 --><property><name>ha.zookeeper.quorum</name><value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value></property><!--指定ZooKeeper超时间隔,单位毫秒 --><property><name>ha.zookeeper.session-timeout.ms</name><value>2000</value></property><!--使用hadoop用户以及用户组代理集群上所有的用户用户组,注意必须是进程启动用户 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><!--设置支持的压缩格式,若不支持,若组件不支持任何压缩格式,应当注销本配置 --><!--<property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value></property>--></configuration>
hdfs-site.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!--HDFS超级用户,必须是启动用户 --><property><name>dfs.permissions.superusergroup</name><value>hadoop</value></property><!--开启web hdfs --><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.namenode.name.dir</name><value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/name</value><description> namenode 存放name table(fsimage)本地目录(需要修改)</description></property><property><name>dfs.namenode.edits.dir</name><value>${dfs.namenode.name.dir}</value><description>namenode粗放 transaction file(edits)本地目录(需要修改)</description></property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/data</value><description>datanode存放block本地目录(需要修改)</description></property><property><name>dfs.replication</name><value>3</value></property><!-- 块大小256M (默认128M) --><property><name>dfs.blocksize</name><value>268435456</value></property><!--======================================================================= --><!--HDFS高可用配置 --><!--指定hdfs的nameservice为ruozeclusterg6,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>ruozeclusterg6</value></property><property><!--设置NameNode IDs 此版本最大只支持两个NameNode --><name>dfs.ha.namenodes.ruozeclusterg6</name><value>nn1,nn2</value></property><!-- Hdfs HA: dfs.namenode.rpc-address.[nameservice ID] rpc 通信地址 --><property><name>dfs.namenode.rpc-address.ruozeclusterg6.nn1</name><value>hadoop001:8020</value></property><property><name>dfs.namenode.rpc-address.ruozeclusterg6.nn2</name><value>hadoop002:8020</value></property><!-- Hdfs HA: dfs.namenode.http-address.[nameservice ID] http 通信地址 --><property><name>dfs.namenode.http-address.ruozeclusterg6.nn1</name><value>hadoop001:50070</value></property><property><name>dfs.namenode.http-address.ruozeclusterg6.nn2</name><value>hadoop002:50070</value></property><!--==================Namenode editlog同步 ============================================ --><!--保证数据恢复 --><property><name>dfs.journalnode.http-address</name><value>0.0.0.0:8480</value></property><property><name>dfs.journalnode.rpc-address</name><value>0.0.0.0:8485</value></property><property><!--设置JournalNode服务器地址,QuorumJournalManager 用于存储editlog --><!--格式:qjournal://<host1:port1>;<host2:port2>;<host3:port3>/<journalId> 端口同journalnode.rpc-address --><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/ruozeclusterg6</value></property><property><!--JournalNode存放数据地址 --><name>dfs.journalnode.edits.dir</name><value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/jn</value></property><!--==================DataNode editlog同步 ============================================ --><property><!--DataNode,Client连接Namenode识别选择Active NameNode策略 --><!-- 配置失败自动切换实现方式 --><name>dfs.client.failover.proxy.provider.ruozeclusterg6</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!--==================Namenode fencing:=============================================== --><!--Failover后防止停掉的Namenode启动,造成两个服务 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><property><!--多少milliseconds 认为fencing失败 --><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><!--==================NameNode auto failover base ZKFC and Zookeeper====================== --><!--开启基于Zookeeper --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!--动态许可datanode连接namenode列表 --><property><name>dfs.hosts</name><value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/slaves</value></property></configuration>
mapred-site.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 配置 MapReduce Applications --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- JobHistory Server ============================================================== --><!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 --><property><name>mapreduce.jobhistory.address</name><value>hadoop001:10020</value></property><!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop001:19888</value></property><!-- 配置 Map段输出的压缩,snappy,注意若,为hadoop为编译集成压缩格式,应注销本配置--><!-- <property><name>mapreduce.map.output.compress</name><value>true</value></property><property><name>mapreduce.map.output.compress.codec</name><value>org.apache.hadoop.io.compress.SnappyCodec</value></property>--></configuration>
yarn-site.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nodemanager 配置 ================================================= --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.localizer.address</name><value>0.0.0.0:23344</value><description>Address where the localizer IPC is.</description></property><property><name>yarn.nodemanager.webapp.address</name><value>0.0.0.0:23999</value><description>NM Webapp address.</description></property><!-- HA 配置 =============================================================== --><!-- Resource Manager Configs --><property><name>yarn.resourcemanager.connect.retry-interval.ms</name><value>2000</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.ha.automatic-failover.enabled</name><value>true</value></property><!-- 使嵌入式自动故障转移。HA环境启动,与 ZKRMStateStore 配合 处理fencing --><property><name>yarn.resourcemanager.ha.automatic-failover.embedded</name><value>true</value></property><!-- 集群名称,确保HA选举时对应的集群 --><property><name>yarn.resourcemanager.cluster-id</name><value>yarn-cluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!--这里RM主备结点需要单独指定,(可选)<property><name>yarn.resourcemanager.ha.id</name><value>rm2</value></property>--><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name><value>5000</value></property><!-- ZKRMStateStore 配置 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.resourcemanager.zk-address</name><value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value></property><property><name>yarn.resourcemanager.zk.state-store.address</name><value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value></property><!-- Client访问RM的RPC地址 (applications manager interface) --><property><name>yarn.resourcemanager.address.rm1</name><value>hadoop001:23140</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>hadoop002:23140</value></property><!-- AM访问RM的RPC地址(scheduler interface) --><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>hadoop001:23130</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>hadoop002:23130</value></property><!-- RM admin interface --><property><name>yarn.resourcemanager.admin.address.rm1</name><value>hadoop001:23141</value></property><property><name>yarn.resourcemanager.admin.address.rm2</name><value>hadoop002:23141</value></property><!--NM访问RM的RPC端口 --><property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>hadoop001:23125</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>hadoop002:23125</value></property><!-- RM web application 地址 --><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>hadoop001:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>hadoop002:8088</value></property><property><name>yarn.resourcemanager.webapp.https.address.rm1</name><value>hadoop001:23189</value></property><property><name>yarn.resourcemanager.webapp.https.address.rm2</name><value>hadoop002:23189</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log.server.url</name><value>http://hadoop001:19888/jobhistory/logs</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value><discription>单个任务可申请最少内存,默认1024MB</discription></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value><discription>单个任务可申请最大内存,默认8192MB</discription></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value></property></configuration>
slaves文件如下:
hadoop001hadoop002hadoop003
设置JDK的绝对路径(采坑)。三台都需要设置
[hadoop@hadoop001 hadoop]$ cat hadoop-env.sh |grep JAVA #如下 已设置jdk的绝对路径# The only required environment variable is JAVA_HOME. All others are# set JAVA_HOME in this file, so that it is correctly defined onexport JAVA_HOME=/usr/java/jdk1.8.0_45#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
启动HA集群:
#确保zk集群是启动的[hadoop@hadoop003 hadoop]$ zkServer.sh statusJMX enabled by defaultUsing config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfgMode: leader#启动journalNode守护进程,三台同时执行[hadoop@hadoop002 sbin]$ cd ~/app/hadoop/bin #删除所有的windows命令[hadoop@hadoop002 sbin]$ rm -rf *.cmd[hadoop@hadoop002 sbin]$ cd ~/app/hadoop/sbin[hadoop@hadoop002 sbin]$ rm -rf *.cmd[hadoop@hadoop002 sbin]$ ./hadoop-daemon.sh start journalnode[hadoop@hadoop003 sbin]$ jps1868 JournalNode1725 QuorumPeerMain1919 Jps#格式化namenode,注意只要hadoop001格式化即可,格式化成功标志,日志输出successfully formatted信息如下[hadoop@hadoop001 sbin]$ hadoop namenode -format......: Storage directory /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/name has been successfully formatted.19/04/06 19:50:08 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 019/04/06 19:50:08 INFO util.ExitUtil: Exiting with status 019/04/06 19:50:08 INFO namenode.NameNode: SHUTDOWN_MSG:/************************************************************SHUTDOWN_MSG: Shutting down NameNode at hadoop001/172.19.121.243************************************************************/[hadoop@hadoop001 sbin]$ scp -r ~/app/hadoop/data/ hadoop002:/home/hadoop/app/hadoop/ #将nn的数据发一份到hadoop002#格式化zkfc,只要hadoop001执行即可,成功后会在zk的创建hadoop-ha/ruozeclusterg6,如下信息:[hadoop@hadoop001 sbin]$ hdfs zkfc -formatZK....19/04/06 20:03:02 INFO ha.ActiveStandbyElector: Session connected.19/04/06 20:03:02 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ruozeclusterg6 in ZK.#启动hdfs,只要hadoop001执行即可[hadoop@hadoop001 sbin]$ start-dfs.sh #若出现如下错误,且jps发现datanode进程未启动,原因是slaves文件被污染,删除,重新编辑一份。·····: Name or service not knownstname hadoop003: Name or service not knownstname hadoop001: Name or service not knownstname hadoop002[hadoop@hadoop002 current]$ rm -rf ~/app/hadoop/etc/hadoop/slaves[hadoop@hadoop002 current]$ vim ~/app/hadoop/etc/hadoop/slaves #添加DN节点信息hadoop001had00p002hadoop003·····#重新启动hdfs,会共启动NN、DN、JN、ZKFC四个守护进程,停止hdfs,stop--dfs.sh[hadoop@hadoop001 sbin]$ start-dfs.sh19/04/06 20:51:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableStarting namenodes on [hadoop001 hadoop002]hadoop001: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-namenode-hadoop001.outhadoop002: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-namenode-hadoop002.outhadoop002: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop002.outhadoop003: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop003.outhadoop001: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop001.outStarting journal nodes [hadoop001 hadoop002 hadoop003]hadoop001: starting journalnode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-journalnode-hadoop001.outhadoop003: starting journalnode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-journalnode-hadoop003.outhadoop002: starting journalnode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-journalnode-hadoop002.out19/04/06 20:52:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableStarting ZK Failover Controllers on NN hosts [hadoop001 hadoop002]hadoop002: starting zkfc, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-zkfc-hadoop002.outhadoop001: starting zkfc, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-zkfc-hadoop001.out[hadoop@hadoop001 sbin]$ jps5504 NameNode5797 JournalNode5606 DataNode6054 Jps1625 QuorumPeerMain5983 DFSZKFailoverController#启动yarn,首先在hadoop001执行即可,此时从日志中可以看出只启动了一台RM,#另一个RM需手动前往hadoop002去启动[hadoop@hadoop001 sbin]$ start-yarn.shstarting yarn daemonsstarting resourcemanager, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-hadoop001.outhadoop001: starting nodemanager, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-hadoop001.outhadoop002: starting nodemanager, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-hadoop002.outhadoop003: starting nodemanager, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-hadoop003.out[hadoop@hadoop002 current]$ yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-hadoop002.out#启动jobhistory服务,在hadoop001上执行即可[hadoop@hadoop001 sbin]$ mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/mapred-hadoop-historyserver-hadoop001.out[hadoop@hadoop001 sbin]$ jps5504 NameNode6211 NodeManager6116 ResourceManager5797 JournalNode5606 DataNode1625 QuorumPeerMain7037 JobHistoryServer7118 Jps5983 DFSZKFailoverController
3.7测试集群是否部署成功
通过命令空间操作hdfs文件
[hadoop@hadoop002 current]$ hdfs dfs -ls hdfs://ruozeclusterg6/[hadoop@hadoop002 current]$ hdfs dfs -put ~/app/hadoop/README.txt hdfs://ruozeclusterg6/19/04/06 21:08:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable[hadoop@hadoop002 current]$ hdfs dfs -ls hdfs://ruozeclusterg6/19/04/06 21:08:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableFound 1 items-rw-r--r-- 3 hadoop hadoop 1366 2019-04-06 21:08 hdfs://ruozeclusterg6/README.txt
web界面访问
- 配置阿里云安全组规则,出入方向放行所有端口
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QJiC2HaG-1608564980222)(https://s2.ax1x.com/2019/04/07/Aflfln.md.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5pnacJrp-1608564980224)(https://s2.ax1x.com/2019/04/07/Af1S0K.md.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qWkdZwLb-1608564980226)(https://s2.ax1x.com/2019/04/07/Af1kpd.md.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IEMmPNJB-1608564980227)(https://s2.ax1x.com/2019/04/07/Af1VXt.md.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zigD9yWV-1608564980228)(https://s2.ax1x.com/2019/04/07/Af1m0f.md.png)] - 配置windos的hosts文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k3cpCKxs-1608564980228)(https://s2.ax1x.com/2019/04/07/Af1RAO.md.png)]
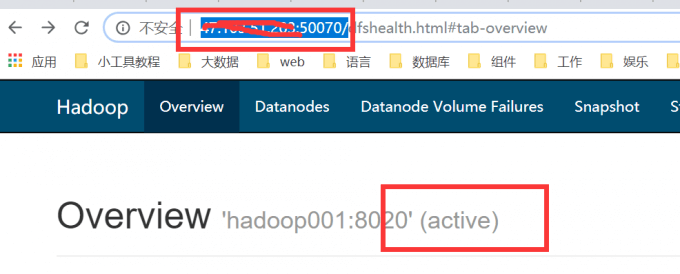
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DbMqaHsC-1608564980229)(https://s2.ax1x.com/2019/04/07/Af1A1A.png)] - web访问hadoop001的hdfs页面,具体谁是active有ZK决定
- web访问hadoop001的hdfs页面,具体谁是standby有ZK决定
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2VbXIEvg-1608564980234)(https://s2.ax1x.com/2019/04/07/Af131s.md.png)] - web访问hadoop001的yarn active界面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KWklNH10-1608564980235)(https://s2.ax1x.com/2019/04/07/Af11pj.md.png)] - web访问hadoop002的yarn standby界面直接访问hadoop002:8088地址会被强制跳转hadoop001的地址。应通过如下地址(ip:8088/cluster/cluster)访问
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jCJ2PJiX-1608564980235)(https://s2.ax1x.com/2019/04/07/Af18cn.md.png)] - web访问jobhistroy页面,我启动在hadoop001,故访问地址为hadoop001,端口通过netstat进程可查询到,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JwPAHGJa-1608564980236)(https://s2.ax1x.com/2019/04/07/Af1GXq.md.png)]
测试MR代码,此时可从yarn以及jobhistory的web界面上看到任务情况
[hadoop@hadoop001 sbin]$ find ~/app/hadoop/* -name '*example*.jar'[hadoop@hadoop001 sbin]$ hadoop jar /home/hadoop/app/hadoop/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 5 10
4.卸载HADOOP HA集群
停止hadoop的守护进程
stop-all.shmr-jobhistory-daemon.sh stop historyserver#执行停止脚本后,查询是否还有hadoop相关进程,若有,直接kill -9[hadoop@hadoop001 sbin]$ ps -ef | grep hadoop
删除zk上所有关于hadoop的信息
[hadoop@hadoop001 sbin]$ zkCli.sh #进入zk客户端,删除所有hadoop的配置[zk: localhost:2181(CONNECTED) 0] ls /[zookeeper, hadoop-ha][zk: localhost:2181(CONNECTED) 1] rmr /hadoop-ha[zk: localhost:2181(CONNECTED) 1] quitQuitting...
清空data数据目录
rm -rf ~/app/hadoop/data/*
扩展1:生产中若遇到两个节点同为stand by状态时(无法HA),通常是ZK夯住了,需检查ZK状态。
扩展2:生产中若某台机器秘钥文件发生变更,不要傻傻的将known_hosts的文件清空,只要找到变更的机器所属的信息,删除即可。清空会影响其他应用登录,正产使用(若known_hosts无改机器登录信息,第一次需要输入yes,写一份信息在known_hosts上),要背锅的。
扩展3:生产中若遇到异常,首先检查错误信息,再检查配置、其次分析运行日志。若是启动或关闭报错,可debug 启动的脚本。sh -x XXX.sh 方式来debug脚本。 注意没有+表示脚本的输出内容,一个+表示当前行执行语法执行结果,两个++表示当前行某部分语法的执行结果。
扩展4:hadoop chechnative 命令可检测hadoop支持的压缩格式,false表示不支持,CDH版本的hadoop不支持压缩,身产中需要编译支持压缩。map阶段通常选择snappy格式压缩,因为snappy压缩速度最快(快速输出,当然压缩比最低),reduce阶段通常选择gzip或bzip2(压缩比最大,占最小磁盘空间,当然压缩解压时间最久)
扩展5 可通过,start-all.sh 或者stop-all.sh,来启动关闭hadoop集群
扩展6 cat * |grep xxx 命令查找当前文件夹下所有的文件内容

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}