 ">
">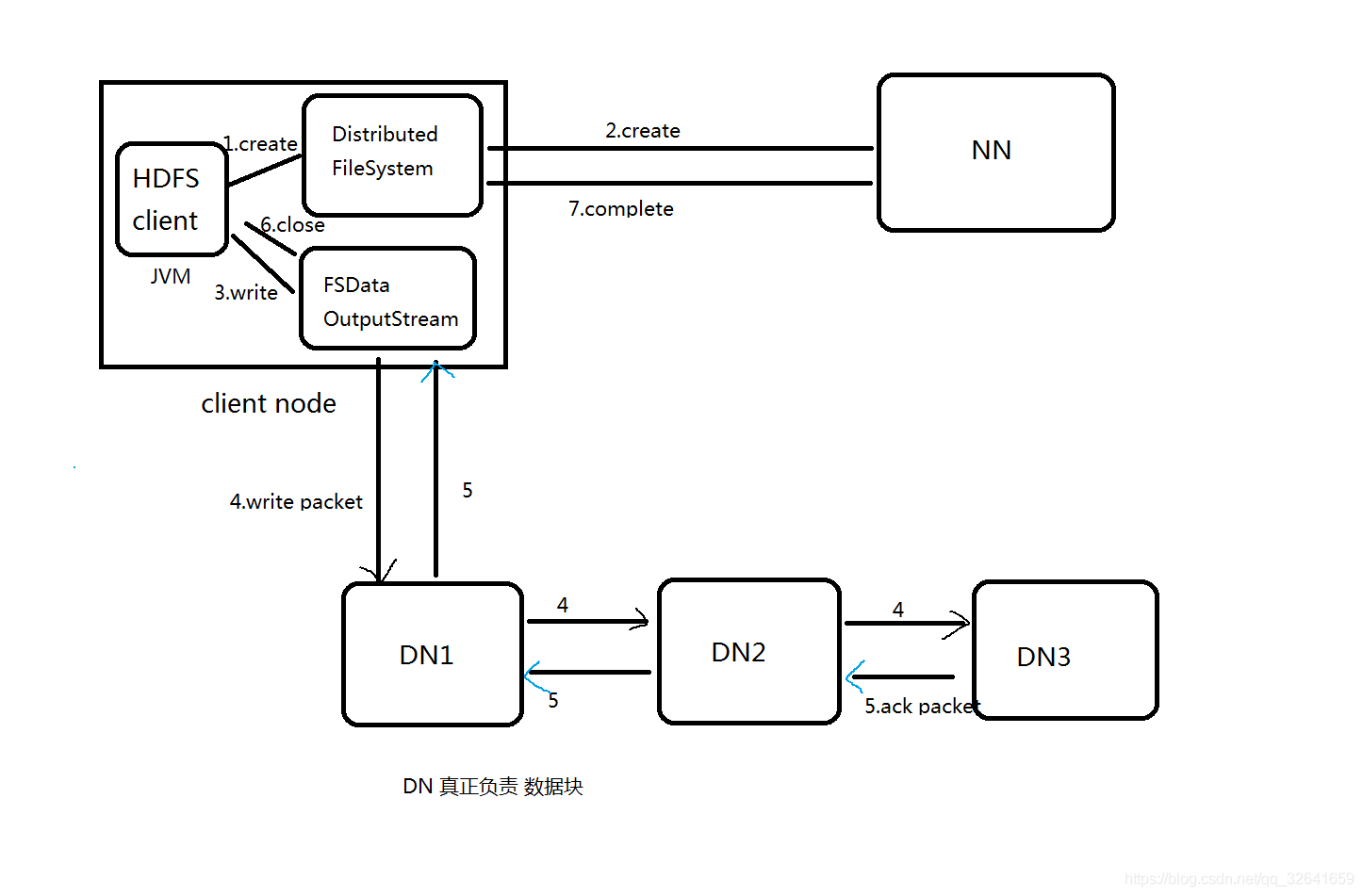
1.hdfs写流程
1.1流程图
1.2流程详解:
1)Client端调用DistributedFileSystem.create(filePath)方法,去与NN进行【RPC】通信,nn 会check该路径的文件是否存在以及有没有权限创建该文件。 假如OK,就创建一个新文件,但是不关联任何的block,nn根据上传的文件大小且块大小且副本数,计算多少块,以及块存放的dn,最终将这些信息返回给客户端,即为【FSDataOutputStream】对象。
2)Client调用FSDataOutputStream.write方法,将第一个块的第一个副本写到第一个DN,写完写第二个副本,写完写第三个副本;当第三个副本写完,返回给ack packet给第二个副本的DN,然后第二个DN返回ack packet给第一个DN;第一个DN返回ack packet给FSDataOutputStream对象,标识第一个块,3副本写完!
4)然后依次写剩余的块!(对操作者来说是透明的)
5)向文件写入数据完成后,Client调用FSDataOutputStream.close()方法。关闭输出流,flush缓冲区的数据包。
6)再调用FistributedFileSystem.complete(),通知NN节点写入成功,并发送blockreport。
注意:存活的DN满足我们的副本数 就能正常的进行文件写入操作
2.hdfs读流程
2.1流程图
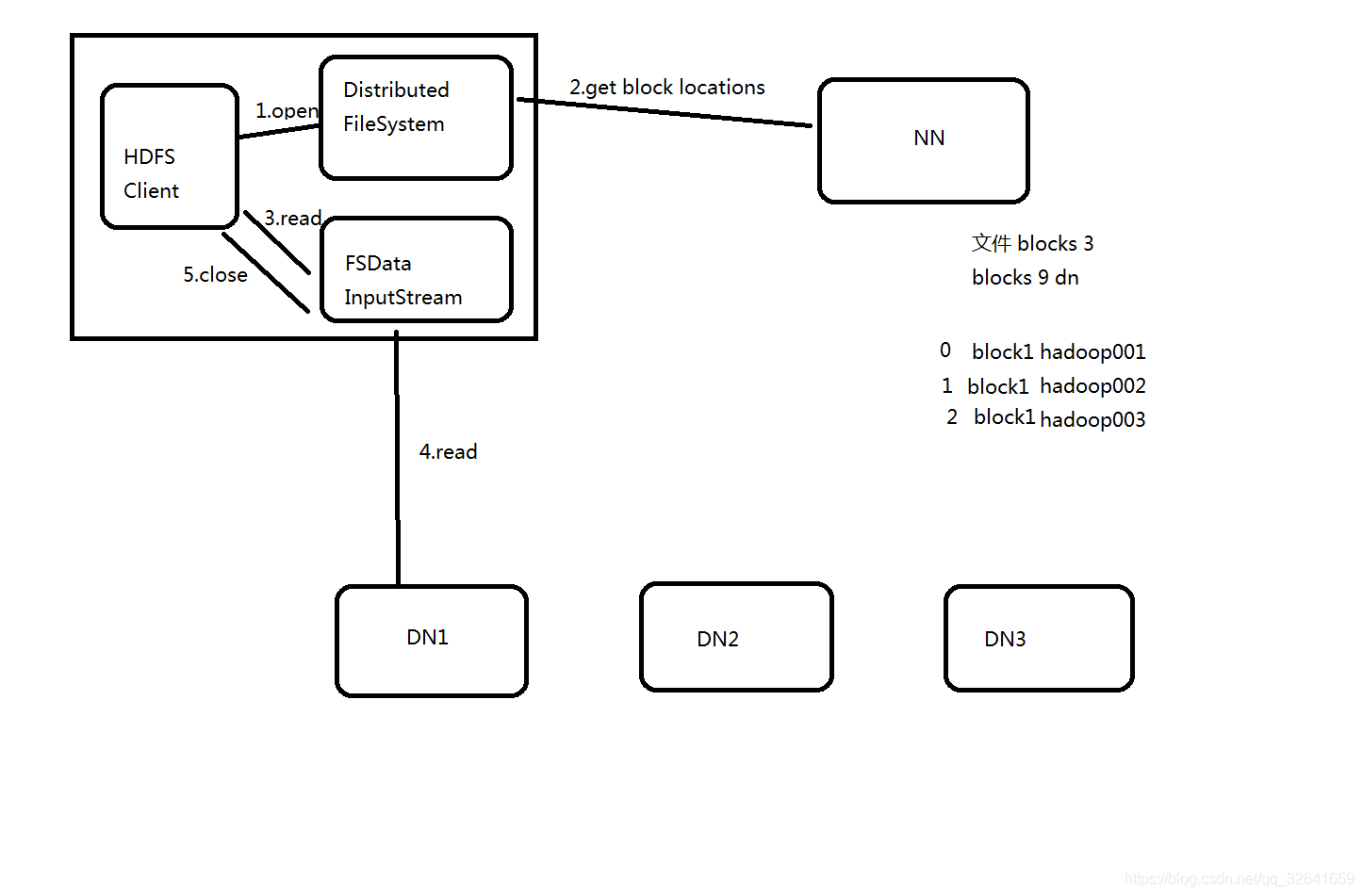

2.2流程详解:
1)Client通过DistributedFileSystem.open(filePath),去与NN进行【RPC】通信,nn会检查该文件是否存在以及是否有权限读取,若ok,返回该文件的部分或全部的block列表,也就是返回FSDataInputStream对象。
2)Client调用【FSDataInputStream】对象的read()方法,a. 去与第一个块的最近副本的DN进行read,读取完后,会check,假如success,会关闭与当前DN通信。假如fail 会记录失败的DN+block信息,下次就不会读取。那么会去该块的第二个副本的DN的地址读取。b.然后去第二个块的最近的DN上读取,会check,success,会关闭与当前DN通信。c.假如当前block列表全部读取完成,文件还没结束,那么FileSystem会从NN获取下一批的block列表。
3)依次读取剩余的块数据
4)最终Client调用FSDataInputStream.close() 关闭输入流
注意:同时死亡的datanode只要不超过副本数,我们就可以进行文件的读取操作
3.block副本放置策略
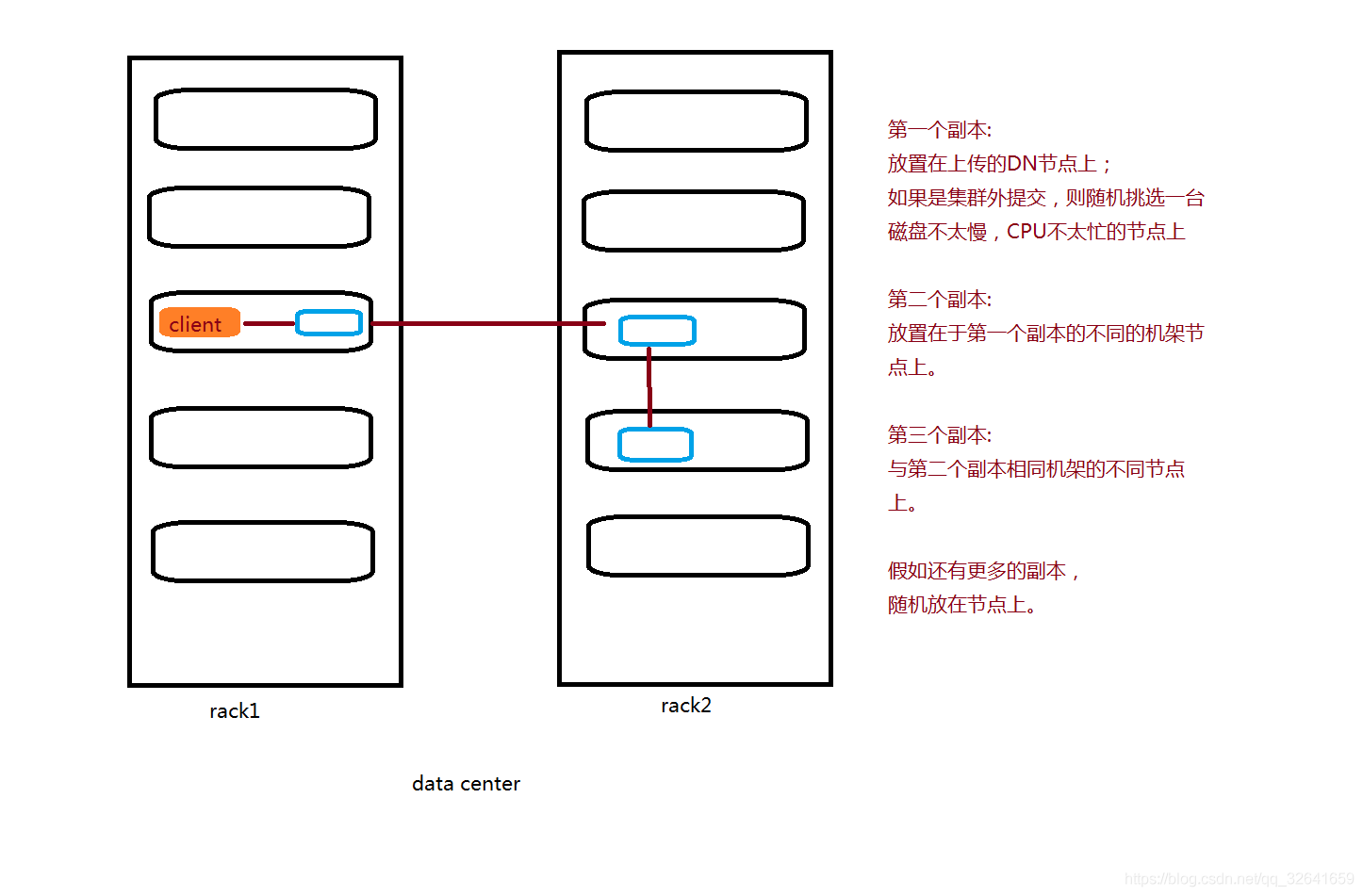

第一放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上,第二个副本放置在不同与第一个副本的机架上的节点,第三个副本是放置在与第二个副本相同机架不同节点上,若还有副本,随机放置。
注意:故生产上尽量将读写的动作 选取DN节点。

若有收获,就点个赞吧
0 人点赞
