1.需求
2.详细设计
进行MR编程,对日志文件数据进行清洗,并将清洗后的数据加载到hive外部表
3.使用idea进行MR编程
这里不进行详细的记录。项目源码链接如下:
链接:https://pan.baidu.com/s/1ABNMJTw7_w0U7duAHk0Bkg提取码:q7uj复制这段内容后打开百度网盘手机App,操作更方便哦

4.本机测试
4.1直接运行main方法,若出现异常:
Exception in thread "main" java.lang.NullPointerExceptionat java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)at org.apache.hadoop.util.Shell.runCommand(Shell.java:505)解决方案:1)、在https://github.com/4ttty/winutils 下载hadoop.dll和winutils.exe 文件。2)、配置hadoop家目录:System.setProperty("hadoop.home.dir","D:\\appanzhuang\\cdh\\hadoop-2.6.0-cdh5.7.0");#注意d盘是我的hadoop实际的解压目录。3)、把hadoop.dll拷贝到C:\Windows\System32下面4)、把winutils.exe文件拷贝到${HADOOP_HOME}/bin目录下

4.2再运行main方法,output目录有输出
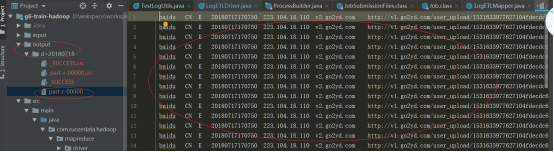

这是我们想要的8个字段,源文件是有72个字段input的文件夹存放的是点击日志,链接如下:链接:https://pan.baidu.com/s/15aHR5xdm_HKD8R6IgJrHJQ提取码:mpkx复制这段内容后打开百度网盘手机App,操作更方便哦

5.服务器测试
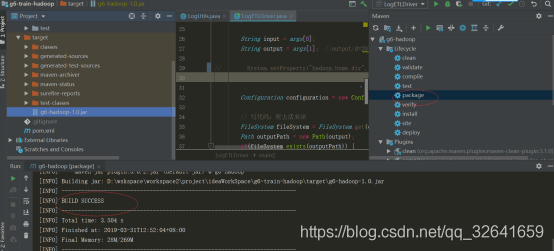
5.1将代码打包并上传服务
将设置hadoop环境变量的哪一行代码注释然后package打包。

5.2 服务器运行测试运行
#将点击日志上传hadoop hdfs上hdfs dfs -mkdir -p /g6/hadoop/accesslog/20180717hdfs dfs -put hadoop-click-log.txt /g6/hadoop/accesslog/20180717#创建结果输出目录hdfs dfs -mkdir -p /g6/hadoop/access/output#运行jar包hadoop jar /home/hadoop/lib/g6-hadoop-1.0.jar \com.ruozedata.hadoop.mapreduce.driver.LogETLDriver \/g6/hadoop/accesslog/20180717 /g6/hadoop/access/output#查看结果hdfs dfs -text /g6/hadoop/access/output/part-r-00000

5.3优化-.以shell脚本方式运行jar包提交命令
vim g6-train-hadoop.sh #新建一个脚本文件,编辑添加如下内容process_date=20190331echo "step1 mr etl"hadoop jar /home/hadoop/lib/g6-hadoop-1.0.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /g6/hadoop/accesslog/20180717 /g6/hadoop/access/output/$process_datechmod u+x g6-train-hadoop.sh #添加可执行的权限. g6-train-hadoop.sh #执行脚本

6.使用hive完成最基本的统计分析
6.1创建一张清洗后的hive表
hive #进入hive命令行show databases;use hive;#创建一张清洗后的表create external table g6_access (cdn string,region string,level string,time string,ip string,domain string,url string,traffic bigint) partitioned by (day string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LOCATION '/g6/hadoop/access/clear' ;

6.2移动数据到hive的外部表对应的目录
hdfs dfs -mkdir -p /g6/hadoop/access/clear/day=20180717hdfs dfs -mv /g6/hadoop/access/output/20190331/part-r-00000 /g6/hadoop/access/clear/day=20180717hdfs dfs -ls /g6/hadoop/access/clear/day=20180717

6.3添加分区信息并查询
alter table g6_access add if not exists partition(day='20180717');select * from g6_access limit 10;

6.4统计分析
select domain,sum(traffic) from g6_access group by domain;
6.5优化以shell脚本方式完成数据清洗以及挂载到hive表
vim g6-train-hadoop.sh #新建一个脚本文件,编辑添加如下内容
#!/bin/bashif [ $# != 1 ] ; thenecho "USAGE: g6-train-hadoop.sh <dateString>"echo " e.g.: g6-train-hadoop.sh 20190402"exit 1;fiprocess_date=$1echo "================step1: mapreduce etl==============="hadoop jar /home/hadoop/lib/g6-hadoop-1.0.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /g6/hadoop/accesslog/20180717 /g6/hadoop/access/output/day=$process_dateecho "================step2: create extral table if not exit================"hive -e "use hive;create external table if not exists g6_access (cdn string,region string,level string,time string,ip string,domain string,url string,traffic bigint) partitioned by (day string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LOCATION '/g6/hadoop/access/clear' ;"echo "================step3: etl data mv to DW================"hdfs dfs -rm -r /g6/hadoop/access/clear/day=$process_datehdfs dfs -mkdir -p /g6/hadoop/access/clear/day=$process_datehdfs dfs -mv /g6/hadoop/access/output/day=$process_date/* /g6/hadoop/access/clear/day=$process_dateecho "================step4: alter partition================"hive -e "use hive;alter table g6_access add if not exists partition(day='${process_date}');"

sh -x g6-train-hadoop.sh 20190405 #以debug方式运行脚本

若有收获,就点个赞吧
0 人点赞
