1.hdfs block数据块大小剖析
1.1block大小配置查询
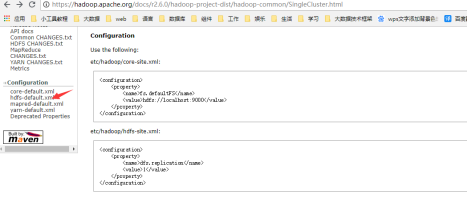


Hadoop2.6.0数据块默认配置是134217728字节,即128M,1.x时默认是64M,生产一般是使用默认值。
1.2 block大小以及副本数配置修改
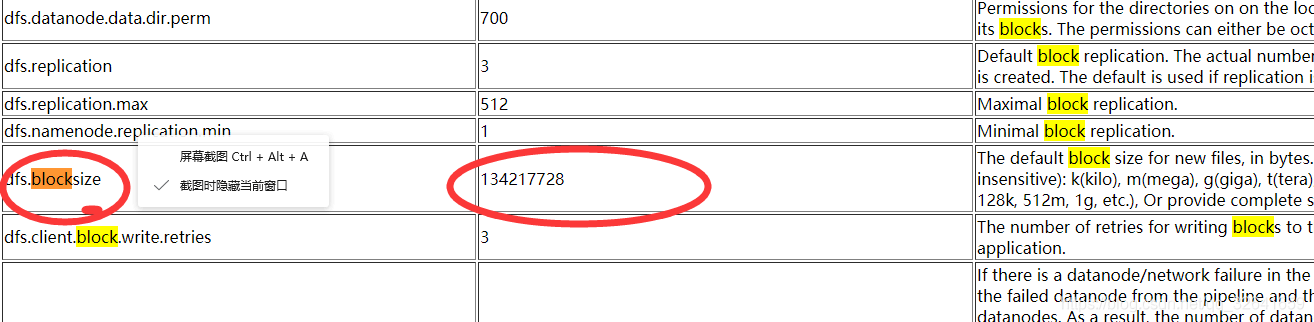
vim HADOOP_BOME /etc/hadoop/hdfs-site.xml #编辑该文件添加或修改如下配置:<property><name>dfs.blocksize</name><value>134217728</value></property><property><name>dfs.replication</name><value>3</value></property>#分别配置了数据块大小以及 副本数。重启hadoop即可使配置生效,生产上建议块为128M,副本数为3
1.3 block剖析以及生产注意事项,重要
1)block是hadoop namenode进程维护数据文件的最小单位,也是物理上真真实实的将文件切割后以块的方式进行存储。2)一个文件至少会占据一个数据块,故hadoop不适合小文件(低于50M)的读写,过多的小文件信息会撑爆nn内存。生产中需将大量的小文件合并为一个个120M<128M左右的文件,充分利用块资源。3)文件实际占用的物理空间为:文件大小*副本数4)面试题:一个文件160m,块大小128m,副本数2。请问实际使用几个块,实际物理存储多少?答案:4个块,实际占用320M物理磁盘

2.hdfs架构设计
2.1官方提供的架构图
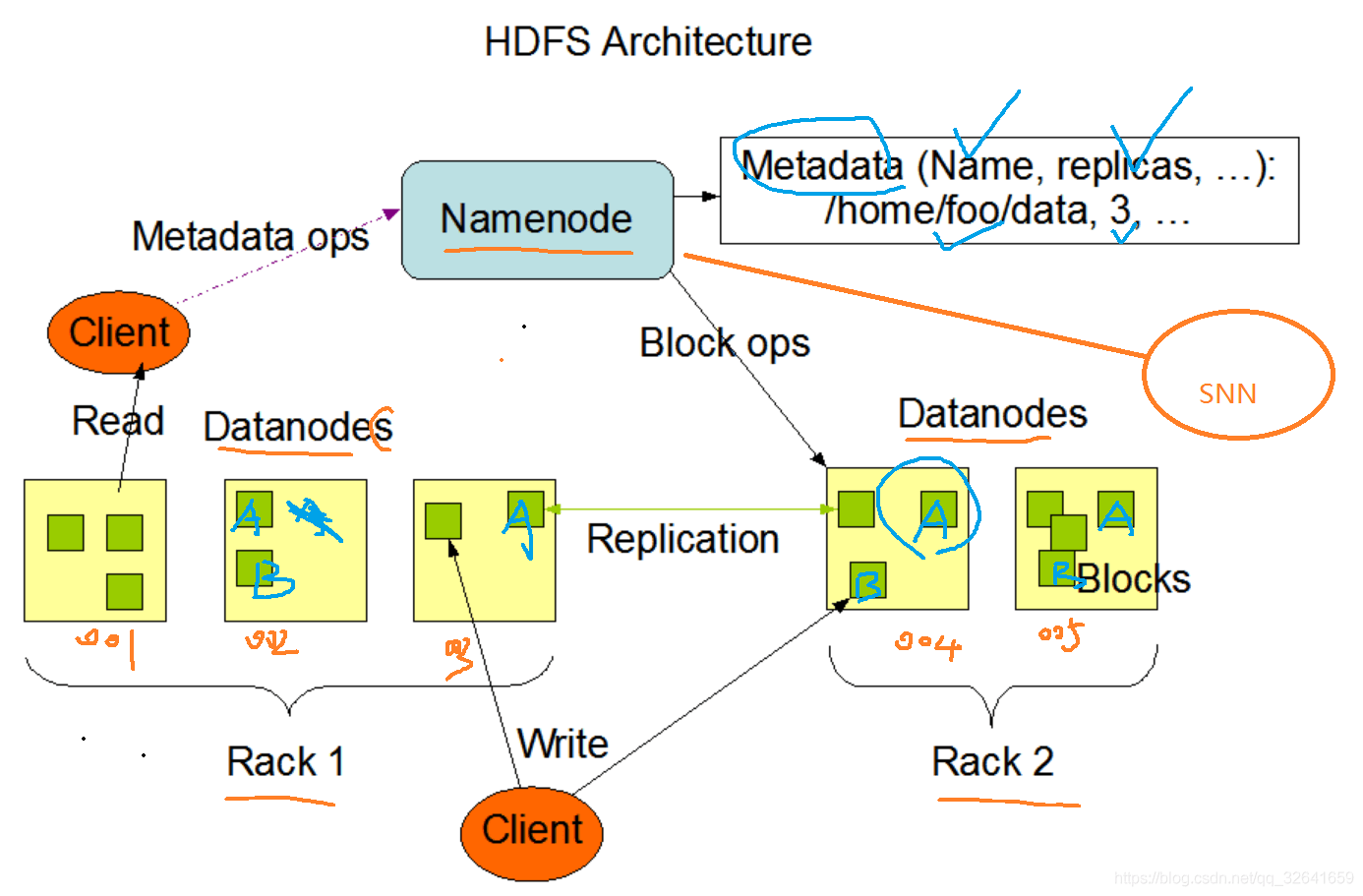

2.2详解:重要
client :客户端,发起读写请求。
namenode :nn,名称节点,老大,只要部署一台即可。存储文件元数据,如下:
a.文件名称b.文件目录结构c.文件属性 创建时间 权限 副本数d.文件对应哪些数据块Blockmap-->数据块对应哪些datanode节点上,nn节点不会持久化存储这种映射关系,如某个块损坏,会自动去复制一份数据在另一dn节点创建一个新块,dn定期发送blockreport 给nn,,以此nn在【内存】中动态维护这种映射关系!nn作用:管理文件系统的命名空间,维护文件系统树,以两种文件永久保存在磁盘上cd /tmp/hadoop-hadoop/dfs/name/current/ #进入dfs目录lledits_inprogress_0000000000000000755 #文件edits:正在编辑的读写记录fsimage_0000000000000000752 #fsimage:镜像文件,有edits+fsimage合成,保存了nn元数据,由snn生成推送给nn,这两种文件极度重要,老二就是通过备份这两种文件来实现备份老大

secondary namenode: snn,第二名称节点,是万年老二,老大挂,它顶上去,生产中使用ha,不启用secondary namenode
namenode。/tmp/hadoop-hadoop/dfs/namesecondary/currentll #作用: 定期备份老大的fsimage+editlog文件并合并为新的fsimage文件推送给nn节点,简称为检查点 :checkpoint参数 :dfs.namenode.checkpoint.period 3600s #默认是1小时触发一次检查点动作(备份),故当nn挂了后,即使snn顶上,也可能会丢失59分钟的数据信息,snn只能回复上一个检查点前的数据,冷备份。2.x使用ha做实时热备份

datanode :dn,数据节点 ,读写文件的数据块
1)存储数据块和数据块的校验(检测是否有数据块损坏)2)和与nn通信:a.每隔3秒发送一个心跳b.每6小时发送一次当前节点的blockreport

rack:机架,是物理硬件,类似于一个大柜子,里面一般放置了10台物理机,一个机架用的是一个电源。GPU机器可能只放置5台,GPU比较吃电。
3. snn备份nn流程详解
3.1流程图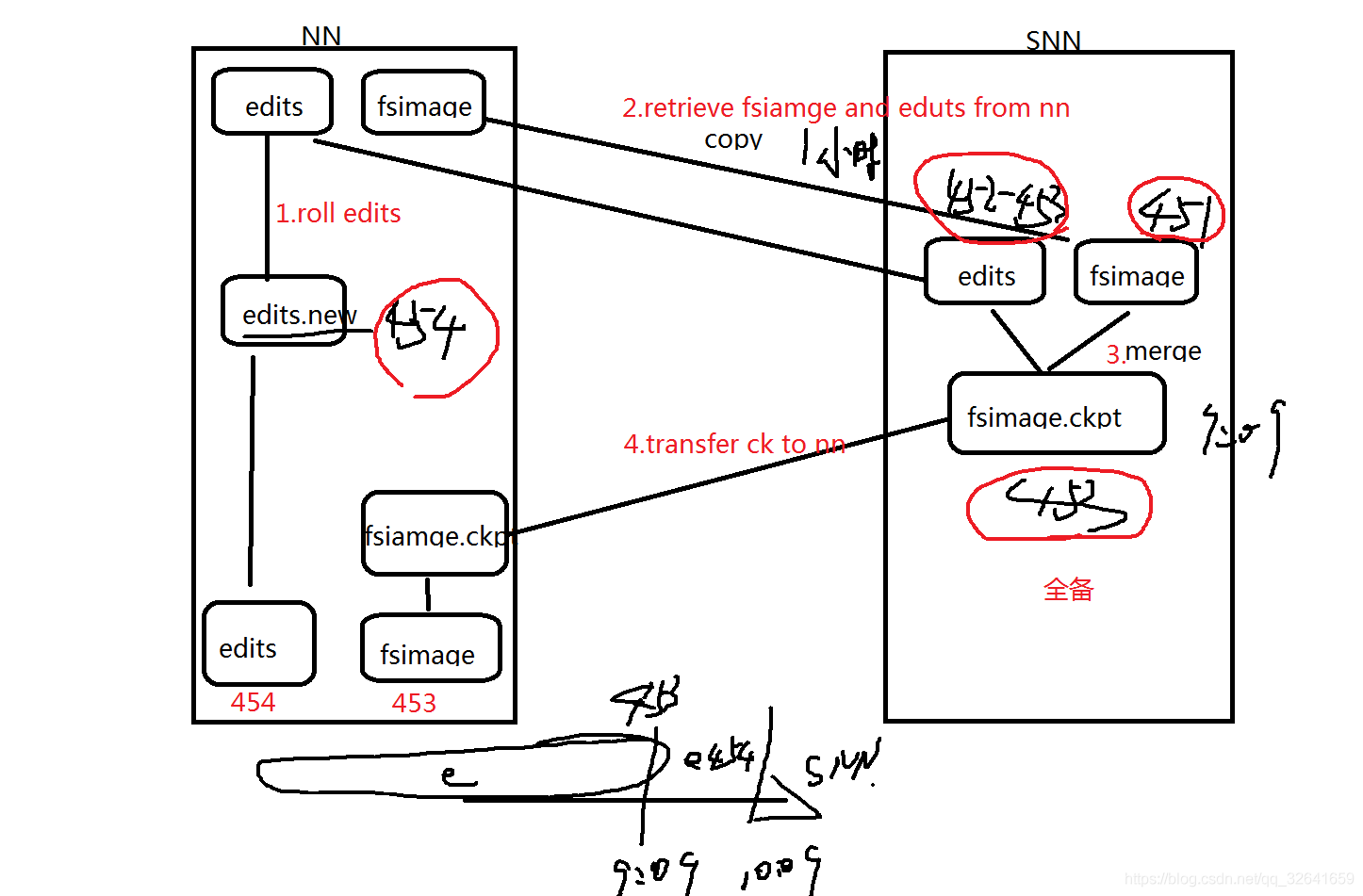

3.2步骤解析:
第一步:namenode实时的在写 edits_inprogress文件,隔一段时间产生一个新的edit文件。第二步:snn每隔一段时间去copy备份namenode的新edit文件。第三步:默认配置,每隔1小时,snn 将copy过来的所有新edit文件和fsimge文件合并生成一个新的fsimage文件,每次新的fsimage为全量操作记录第四步:snn将生成的fsimage文件推送给nn,第三步和第四步统称 checkpoint

4.元素据存储机制
1、内存中有一份完整的元数据(内存meta data)
2、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
3、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)。
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中

若有收获,就点个赞吧
0 人点赞
