@[TOC]
1.生产常用的文件格式
查询hive的官网可知,hive的文件格式有如下
- SEQUENCEFILE:生产中绝对不会用,k-v格式,比源文本格式占用磁盘更多
- TEXTFILE:生产中用的多,行式存储
- RCFILE:生产中用的少,行列混合存储,OCR是他得升级版
- ORC:生产中最常用,列式存储,hive存储常用此格式,生成的其文件可以带metastore信息
- PARQUET:生产中最常用,列式存储,impala3.x之前不支持orc,主用PARQUET
- AVRO:生产中几乎不用,不用考虑,一般用于数据传输,支持数据类型丰富,生成的其文件可以带metastore信息
- JSONFILE:生产中几乎不用,不用考虑
- INPUTFORMAT:生产中几乎不用,不用考虑
hive默认的文件格式是TextFile,可通过set hive.default.fileformat 进行配置
2.行式与列式存储对比
大数据99%以上的场景都是使用的是列式存储数据
2.1行式与列式存储数据物理底层存储区别
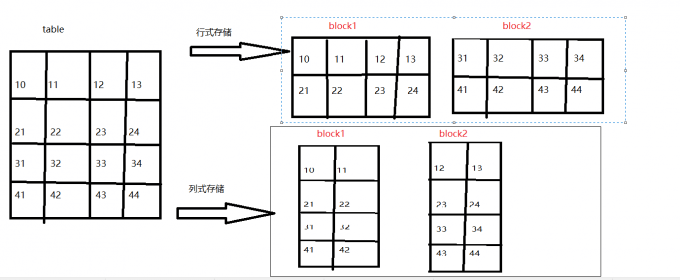
如上图:
行式存储的一行数据一定是在同一个block块中,任何的select 底层都是全字段查询。
列式存储的一行数据不同列可以在不同的block块中。
2.2优缺点
列式存储:
- 优点:当查询部分字段时,极大减小列查询数据的范围,显著提高查询效率
- 缺点:当查询全部字段时,数据需要重组,比直接读取一行慢
行式存储:
- 优点:全字段查询速度快
- 缺点:当查询部分字段时,底层依旧读取所有字段数据,造成资源浪费。生产中很少遇到全字段查询
3.hive文件格式配置实现以及对比
page_views表textfile格式大小为18.1M,相关测试数据信息请参考hadoop之文件压缩格式对比分析以及配置压缩格式
#先关闭压缩SET hive.exec.compress.output=false;
3.1使用SEQUENCEFILE文件格式
#创建SEQUENCEFILE数据存储格式表create table page_views_seqstored as SEQUENCEFILEas select * from page_views;#查看hdfs数据[hadoop@hadoop001 ~]$ hdfs dfs -du -s -h /user/hive/warehouse/wsktest.db/page_views_seq/*19.6 M 19.6 M /user/hive/warehouse/wsktest.db/page_views_seq/000000_0
SEQUENCEFILE格式数据反而变大了,生产肯定不可取的
3.2使用RCFILE格式
#创建RCFILE数据存储格式表create table page_views_rcstored as RCFILEas select * from page_views;#查看hdfs数据[hadoop@hadoop001 ~]$ hdfs dfs -du -s -h /user/hive/warehouse/wsktest.db/page_views_rc/*17.9 M 17.9 M /user/hive/warehouse/wsktest.db/page_views_rc/000000_0
相较于普通文件,无读写以及存储优势,rc格式数据只节约了10%左右的空间存储,生产测试中读写性能也没有多大的提升,
3.3使用ORC文件格式
#创建ORC文件格式表,默认是使用zlib压缩,支持zlib和snappycreate table page_views_orcstored as ORCas select * from page_views;#查看hdfs数据[hadoop@hadoop001 ~]$ hdfs dfs -du -s -h /user/hive/warehouse/wsktest.db/page_views_orc/*2.8 M 2.8 M /user/hive/warehouse/wsktest.db/page_views_orc/000000_0#创建ORC文件格式表,不使用压缩create table page_views_orc_nonestored as ORC tblproperties ("orc.compress"="NONE")as select * from page_views;#查看hdfs数据[hadoop@hadoop001 ~]$ hdfs dfs -du -s -h /user/hive/warehouse/wsktest.db/page_views_orc_none/*7.7 M 7.7 M /user/hive/warehouse/wsktest.db/page_views_orc_none/000000_0
orc格式文件大小是原文本1/3左右,默认使用压缩则只有原文本的1/6左右,由此可见生产上对orc格式的青睐。
3.4使用PARQUET文件格式
#创建PARQUET文件格式表set parquet.compression=gzip; #设置parquet文件的压缩格式,我这里设不设置,文件大小都一致create table page_views_parstored as PARQUETas select * from page_views;#查看hdfs数据[hadoop@hadoop001 ~]$ hdfs dfs -du -s -h /user/hive/warehouse/wsktest.db/page_views_par/*3.9 M 3.9 M /user/hive/warehouse/wsktest.db/page_views_par/000000_0
parquet格式文件大小是源文件的1/5左右。生产上也是好的选择
3.5读取数据量对比
直接执行 select 查询,观察日志 尾部HDFS Read: 190XXX ,就可知道读取数据量了
总结:相同数据量的数据,列式存储(ORC、PARQUET)占的磁盘空间远远低于行式存储(如textfile),当查询部分字段是,列式存储的数据只需加载对应的列数据即可。 存少读少,极大磁盘使用以及IO,相对减少资源(内存,cpu)不必要的浪费,故列式存储在大数据领域完爆行式存储。

若有收获,就点个赞吧
0 人点赞
