缓冲区:Buffer,本质上是一个可以读写数据的内存块,可以理解成一个内置数组的容器对象,该对象提供了一组方法,能够更加轻易的使用内存块。
1、java 给每个非布尔原始数据类型提供了一个缓冲区类: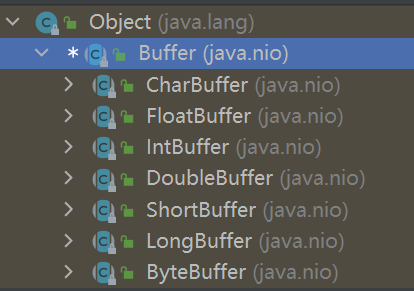
2、缓冲区与通道 Channel :通道是 IO 传输发生时通过的入口,而缓冲区是这些数据的来源或者目标。
- 缓冲区 —> 通道 —> 目的地
- 来源 —> 通道 —> 缓冲区
缓冲区基础
缓冲区是包含在一个对象内的基本数据元素数组。相比较于普通数组,Buffer 类将数据内容和信息包含在一个单一的对象中,且提供了一系列的处理数据缓冲区的 API。
缓冲区的属性
所有的缓冲区都具有 4 个属性来提供关于其所包含的数据元素的信息,分别是:
- 容量:capacity,缓冲区能够容纳的数据元素的最大数量,在创建时设定,不可更改
- 上界:limit,缓冲区第一个不能读或写的元素,或者说,缓冲区现存元素的计数
- 位置:position,下一个要被读或者写的元素的索引,位置会被相应的 get() 和 put() 函数自动更新
- 标记:mark,一个备忘位置,需要注意的是,mark 在未设定前是未定义的(undefined)
- 调用 mark() 函数来设定 mark = position
- 调用 reset() 函数设定 position = mark
属性间的关系:0 <= mark <= position <= limit <= capacity
缓冲区 API
1、创建缓冲区
java 中有 7 种主要类型的缓冲区,但它们都是抽象类,不能够直接实例化,但是提供了静态工厂方法来创建相应类的新实例。
创建新的缓冲区提供了两种方式,分配或者包装。
- 分配操作:allocate() 或 allocateDirect() 函数,创建一个缓冲区对象并分配一个私有的空间来存储容量大小的数据元素
- 包装操作:wrap() 函数,则是使用提供的数组作为存储空间而不是分配空间来创建一个缓冲区对象
注意事项:
- wrap(byte[] bytes , int offset, int length):该函数不是指创建只占用了一个数组子集的缓冲区。该缓冲区可以存取该数组的全部范围,offset 和 length 参数只是设置了初始状态
- 通过 wrap() 函数生成的缓冲区,数据元素会存在于数组中,对数组和缓冲区的修改会互相影响 ```java / 直接创建缓冲区 / // 非直接缓冲区 ByteBuffer buffer = ByteBuffer.allocate(1024); // 直接缓冲区 ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
/ 包装现有数组 / byte[] bytes = new byte[1024]; ByteBuffer buffer = ByteBuffer.wrap(bytes);
2、Buffer 类提供的方法:- int capacity():返回此缓冲区的容量- int position():返回此缓冲区的位置- Buffer position(int newPosition):设置此缓冲区的位置- int limit():返回此缓冲区的限制- Buffer limit(int newLimit):设置此缓冲区的限制- Buffer mark():在此缓冲区的位置设置标记- Buffer reset():在此缓冲区的位置重置为以前的标记的位置- Buffer clear():清楚此缓冲区,即将各个标志恢复初始状态,但数据并没有被擦除- Buffer flip():反转此缓冲区- Buffer rewind():重绕此缓冲区- int remaining():返回当前位置与限制元素之间的元素数- boolean hasRemaining():当前位置和限制位置之间是否有元素- boolean isReadOnly():当前缓冲区是否为只读缓冲区jdk 1.6之后引入的API:- boolean hasArray():告知此缓冲区底层是否有可访问的底层数组实现- Object array():返回此缓冲区的底层实现数组- int arrayOffset():返回此缓冲区的底层实现数组中第一个缓冲区元素的偏移量- Boolean isDirect():是否为直接缓冲区3、缓冲区中的元素的存取:缓冲区中元素的存取与其特定的实现有关,这里以 ByteBuffer 为例<br />存放元素:- 相对位置:ByteBuffer put(byte b)- 绝对位置:ByteBuffer put(int index , byte b)获取元素:- 相对位置:byte get()- 绝对位置:byte get(int index)注意事项:- 相对位置的读取和存放元素,位置在返回时会前进一- 相对位置的 put() 运算位置超出上界时,抛出 BufferOverflowException- 相对位置的 get() 运算位置不小于上界时,抛出 BufferUnderflowException- 绝对位置不会影响缓冲区的位置属性,但提供的索引 index<0 或 index>=limit 时,抛出 IndexOutOfBoundsException 异常- 一般而言,绝对位置提供了在不丢失位置的情况下对已经填充的缓冲区进行修改的能力4、缓冲区的正常使用步骤:1. 往缓冲区中填充元素1. 使用 flip() 函数翻转缓冲区:将缓冲区从写模式切换到读模式1. 读取缓冲区中的元素1. 清空缓冲区:clear() 或者 compact()> 从写模式切换到读模式:> - flip():将缓冲区从写模式切换到读模式,等效于 byteBuffer.limit(byteBuffer.position()).position(0)>从读模式切换到写模式:> - clear():将缓冲区重置为空状态,不改变缓冲区中的任何数据元素,而是仅仅将 limit 设置为 capacity,并将位置设为 0> - compact():丢弃已经释放的数据,保留未释放的数据,并将未释放的数据移到缓冲区的前面,limit 重置为 capacity,position 设置为剩余元素的数量```java// 1.创建BufferByteBuffer byteBuffer = ByteBuffer.allocate(1024);// 2.往Buffer填充元素for (int i = 0; i < 100; i++) {// 这里需要put的为byte元素,且只放入了100个byteBuffer.put((byte) 'c');}System.out.println(byteBuffer.limit()); // 1024System.out.println(byteBuffer.position()); // 100// 3.切换到读模式// byteBuffer.flip() 等效于 byteBuffer.limit(byteBuffer.position()).position(0)byteBuffer.flip();System.out.println(byteBuffer.limit()); // limit为缓冲区内的数据量 100System.out.println(byteBuffer.position()); // postion为0// 4.读取数据for (int i = 0; i < 50; i++) {System.out.println((char) byteBuffer.get());}// 5.切换为写模式// clear() 函数:将缓冲区重置为初始状态,等同于byteBuffer.limit(byteBuffer.capacity()).position(0)// compact() 函数:将未读元素移至第一个元素的索引为0,然后重新写入元素byteBuffer.compact();System.out.println(byteBuffer.limit()); // limit重置为capacity,即1024System.out.println(byteBuffer.position()); // 元素剩余50个元素,被移到缓冲区的0-49的位置,所以position为50
5、标记:是缓冲区能够记住一个位置并在之后将其返回
- 缓冲区的标记在 mark() 函数被调用之前是未定义的,调用时标记被设为当前位置的值
- reset() 函数将位置设置为当前的标记值,如果标记值未定义,调用 reset() 将导致 InvalidMarkException 异常
- 注意:
- 一些缓冲区函数会抛弃已经设定的标记,如 rewind()、clear()、flip()
- 如果新设定的值比当前的标记小,调用 limit() 或 position() 带有索引参数的版本会抛弃标记
6、两个缓冲区相等,指 equals() 方法返回 true,的充要条件:
- 两个对象类型相同。包含不同数据类型的 buffer 永远不会相等,而且 buffer 绝不会等于非 buffer 对象
- 两个对象都剩余同样数量的元素。Buffer 的容量不需要相同,而且缓冲区中剩余数据的索引也不必相同。但每个缓冲区中剩余元素的数量(从位置到上界)必须相同
- 在每个缓冲区中应被 get() 函数返回的剩余数据元素序列必须一致
如果不满足以上任意条件,就会返回 false
ByteBuffer buffer0 = ByteBuffer.allocate(10);ByteBuffer buffer1 = ByteBuffer.allocate(10);buffer0.put((byte) '0').put((byte) '1');for (int i = 0; i < 3; i++) {buffer0.put((byte) '2');buffer1.put((byte) '2');}buffer0.flip().position(2);buffer1.flip();System.out.println(buffer0.equals(buffer1)); // 返回true,满足上述的三个条件
compareTo() 方法:比较针对与和每个缓冲区剩余数据进行
- 如果一个缓冲区在不相等元素被发现前已经耗尽,较短的缓冲区被认为小于较长的缓冲区
- buffer1.compareTo(buffer2),当 buffer1 小于、等于或大于 buffer2 时,分别返回一个负整数、0、正整数
7、缓冲区数据的批量移动:以 ByteBuffer 为例
- 从缓冲区将数据传输到数组:
- ByteBuffer get(byte[] dst):将一个缓冲区释放到给定的数组
- ByteBuffer get(byte[] dst , int offset , int length):offset 和 length 参数来指定目标数组的子区间
- 注意:批量传输的大小总是固定的,省略了长度意味着整个数组会被填满,当缓冲区元素不够填满数组时,会抛出异常,因此在小型缓冲区中传入一个大型数组时,需要明确地指定缓冲区中剩余的数据长度,即在调用 get() 之前必须查询缓冲区中的元素数量
- 从数组将数据移动到缓冲区:
- ByteBuffer put(byte[] src):等效于 put(src , 0 , src.length)
- ByteBuffer put(byte[] src , int offset , int length)
- 注意:如果缓冲区有足够的空间接受数组中的数据,那么数据将会被复制到从当前位置开始的缓冲区,并且缓冲区位置会被提前所增加的元素的数量,然后 position 会增加响相应的值。如果缓冲区中没有足够的空间,那么不会有数据被传递,同时抛出一个 BufferOverflowException 异常。

若有收获,就点个赞吧
0 人点赞
