原文链接:http://www.imooc.com/article/293314
在软件开发过程中,习惯将软件横向拆分成几个层:
- 表现层 controller
- 业务逻辑层 service
- 数据访问层 dao
- 数据源
软件分层设计的优点:
- 解耦
- 简化问题
- 降低系统维护成本
- 逻辑复用与代码复用
阿里Java开发手册中的应用分层建议: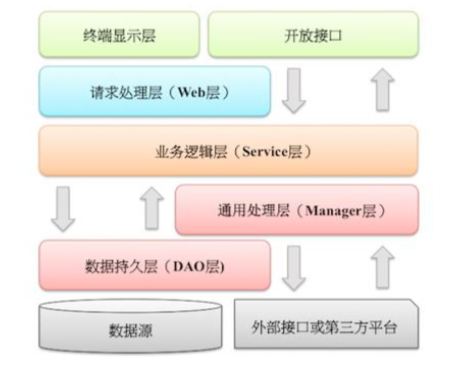
- 开放接口层:
- 可直接封装Service方法暴露成RPC接口
- 通过Web封装成http接口
- 进行网关安全控制/流量控制等
- 终端显示层:各个端的模板渲染并执行显示的层
- Web层:主要是对访问请求进行转换、各类基本参数校验、或者不复用的业务简单处理等
- Service层:相对集体的业务逻辑处理层
- Manager层:通用业务逻辑服务层
- 对第三方平台封装的层,预处理返回结果及转化异常信息
- 对service通用能力的下沉,如缓存方案、中间件处理等
- 与dao层交互,对多个dao的组合复用
- dao层:数据访问层
常用的领域模型(来自阿里开发手册):
- DO(Data Object):此对象与数据库表结构一一对应,通过DAO层想上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service或Manager向外传输的对象。
- BO(Business Object):业务对象,由Service层输出的封装业务逻辑的对象。
- AO(Application Object):应用对象,在Web层与Service层之间抽象的复用对象模型,极为贴近展示层,复用度不高。
- VO(View Object):显示层对象,通常是Web向模版渲染引擎层传输的对象。
- Query:数据查询对象,各层接收上层的查询请求。注意超过2个参数的查询封装,禁止使用Map类来传输
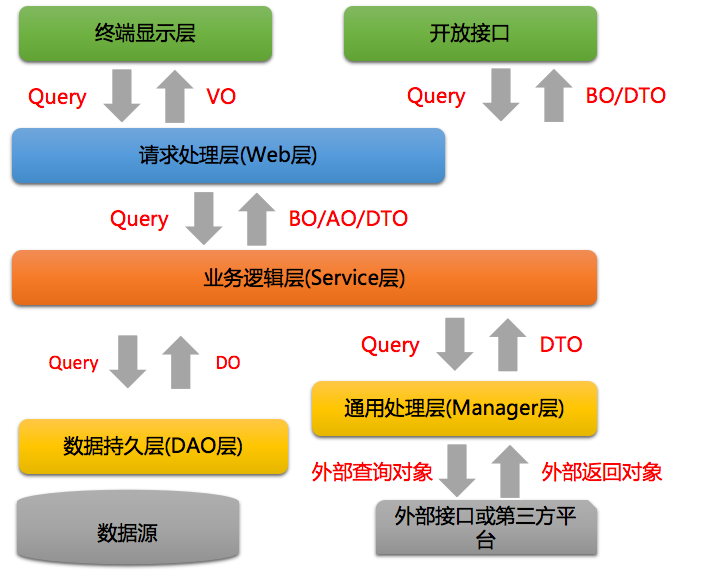
领域模型转换:
1、set/get 方法:对于复杂的转换或者有特殊要求的转换可以使用set和get方法
2、FastJson的序列化和反序列化:
// JSON.toJSONString将对象序列化成字符串,JSON.parseObject将字符串反序列化为OderVO对象orderVO = JSON.parseObject(JSON.toJSONString(orderDTO), OrderVO.class);
3、Apache工具包BeanUtils工具类:
- 属性名需要一致
浅拷贝
BeanUtils.copyProperties(orderVO, orderDTO);
4、Spring封装的BeanUtils工具类:
属性名和属性类型必须一致
- 可以忽略部分属性
// 对象属性转换,忽略orderedProducts字段BeanUtils.copyProperties(orderDTO, orderVO, "orderedProducts");
apache的BeanUtils和spring的BeanUtils中拷贝方法的原理都是先用jdk中 java.beans.Introspector类的getBeanInfo()方法获取对象的属性信息及属性get/set方法,接着使用反射(Method的invoke(Object obj, Object… args))方法进行赋值。

实现统一异常处理功能:实现一个异常处理的类,并用@ControllerAdvice修饰
集成CaffeineCache缓存功能:
- @Cacheable:缓存数据,一般用在查询方法上,将查询到的数据进行缓存
- @CachePut:更新方法上,将数据从缓存中进行更新
- @CacheEvict:删除缓存
- 在pom.xml中引入相关jar包
- CacheManager Bean
- 使用注解,标识哪些方法需要缓存
集成Guava令牌桶实现全局限流功能
- 在pom.xml中引入Guava工具包的支持
- 定义一个拦截器,实现令牌的发放和获取
- 将拦截器配置到web系统中
使用TraceId实现日志跟踪:
- 建立一个过滤器,在过滤器中给线程设置TraceId
- 将日志配置文件进行修改,把TraceId打印到日志中
文件上传下载:
- 文件上传的Controller,负责处理文件上传
- 文件上传的服务接口,通过接口的形式来定义出文件上传的功能
- 实现文件上传的业务逻辑
- 文件下载,采用静态路径映射的方式实现
数据导出:easyexcel
- 依赖导入
- UserController新增数据导出的方法
- 实现数据导出的功能
- 定义导出实体
- 分批加载数据,分批使用EasyExcel导出
- 将导出的文件上传
导出功能异步化:
- 先创建线程池
- 将导出方法使用@Aync注解标记为异步执行


若有收获,就点个赞吧
0 人点赞
