前言
每次开发新页面的时候,都免不了要去设计一个新的 URL,也就是路由。其实路由在设计的时候不仅仅是一个由几个简单词汇和斜杠分隔符组成的链接,偶尔也可以去考虑有没有更“优雅”的设计方式和技巧。而在这背后,路由和组件之间的协作关系是怎样的呢?以 React 中的 Router 使用方法为例,整理了一些知识点小记~
React-Router
基本用法
通常使用 React-Router (https://reactrouter.com/native/guides/quick-start) 来实现 React 单页应用的路由控制,它通过管理 URL,实现组件的切换,进而呈现页面的切换效果。
其最基本用法如下:
import { Router, Route } from 'react-router';render((<Router><Route path="/" component={App}/></Router>), document.getElementById('app'));
亦或是嵌套路由:
在 React-Router V4 版本之前可以直接嵌套,方法如下:
<Router><Route path="/" render={() => <div>外层</div>}><Route path="/in" render={() => <div>内层</div>} /></Route></Router>
上面代码中,理论上,用户访问 /in 时,会先加载 <div>外层</div>,然后在它的内部再加载 <div>内层</div>。
然而实际运行上述代码却发现它只渲染出了根目录中的内容。后续对比 React-Router 版本发现,是因为在 V4 版本中变更了其渲染逻辑,原因据说是为了践行 React 的组件化理念,不能让 Route 标签看起来只是一个标签(奇怪的知识又增加了)。
现在较新的版本中,可以使用 Render 方法实现嵌套。
<Routepath="/"render={() => (<div><Routepath="/"render={() => <div>外层</div>}/><Routepath="/in"render={() => <div>内层</div>}/><Routepath="/others"render={() => <div>其他</div>}/></div>)}/>
此时访问 /in 时,会将“外层”和“内层”一起展示出来,类似地,访问 /others 时,会将“外层”和“其他”一起展示出来。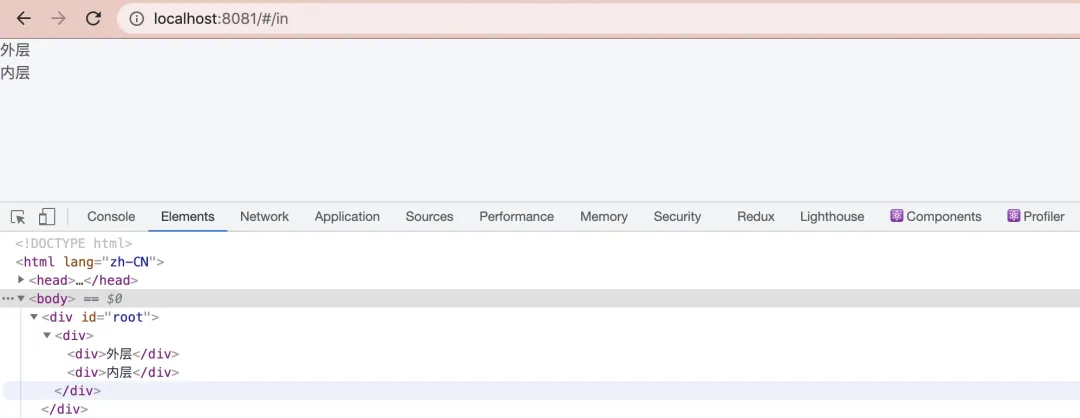
路由传参小 Tips
在实际开发中,往往在页面切换时需要传递一些参数,有些参数适合放在 Redux 中作为全局数据,或者通过上下文传递,比如业务的一些共享数据,但有些参数则适合放在 URL 中传递,比如页面类型或详情页中单据的唯一标识 id。在处理 URL 时,除了问号带参数的方式,React-Router 能做什么呢?在这其中,Route 组件的 path 属性便可用于指定路由的匹配规则。
场景 1
描述:就想让普普通通的 URL 带个平平无奇的参数
那么,接下来可以这样干:
Case A:路由参数
path="/book/:id"
可以用冒号 + 参数名字的方式,将想要传递的参数添加到 URL 上,此时,当参数名字(本 Case 中是 id)对应的值改变时,将被认为是不同 URL。
Case B:查询参数
path="/book"
如果想要在页面跳转的时候问号带参数,那么 path 可以直接设计成既定的样子,参数由跳转方拼接。在跳转时,有两种形式带上参数。其一是在 Link 组件的 to 参数中通过配置字符串并用问号带参数,其二是 to 参数可以接受一个对象,其中可以在 search 字段中配置想要传递的参数。
<Link to="/book?id=111" />// 或者<Link to={{pathname: '/book',search: '?id=111',}}/>
此时,假设当前页面 URL 中的 id 由 111 修改为 222 时,该路由对应的组件(在上述例子中就是 React-Route 配置时 path=”/book” 对应的页面/组件 )会更新,即执行 componentDidUpdate 方法,但不会被卸载,也就是说,不会执行 componentDidMount 方法。
Case C:查询参数隐身式带法
path="/book"
path 依旧设计成既定的样子,而在跳转时,可以通过 Link 中的 state 将参数传递给对应路由的页面。
<Link to={{pathname: '/book',state: { id: 111 }}}/>
但一定要注意的是,尽管这种方式下查询参数不会明文传递了,但此时页面刷新会导致参数丢失(存储在 state 中的通病),So,灰常不推荐~~(其实不想明文可以进行加密处理,但一般情况下敏感信息是不建议放在 URL 中传递的~)
场景 2
描述:编辑/详情页,想要共用一个页面,URL 由不同的参数区分,此时希望,参数必须为 edit、detail、add 中的 1 个,不然需要跳转到 404 Not Found 页面。
path='/book/:pageType(edit|detail|add)'
如果不加括号中的内容 (edit|detail|add),当传入错误的参数(比如用户误操作、随便拼接 URL 的情况),则页面不会被 404 拦截,而是继续走下去开始渲染页面或调用接口,但此时很有可能导致接口传参错误或页面出错。
场景 3
描述:新增页和编辑页那么像,新增页也想和编辑/详情共用一个页面。但是新增页不需要 id,编辑/详情页需要 id,使用同一个页面怎么办?
path='/book/:pageType(edit|detail|add)/:id?'
可以用 ? 来解决,它意味着 id 不是一个必要参数,可传可不传。
场景 4
描述:id 只能是数字,不想要字符串怎么办?
path='/book/:id(\\\d+)'
此时 id 不是数字时,会跳转 404,被认为 URL 对应的页面找不到。
底层依赖
有了这么多场景,那 Router 是怎样实现的呢?其实它底层是依赖了 path-to-regexp (https://github.com/pillarjs/path-to-regexp/tree/v1.7.0) 方法。
var pathToRegexp = require('path-to-regexp')// pathToRegexp(path, keys, options)// 示例var keys = []var re = pathToRegexp('/foo/:bar', keys)// re = /^\/foo\/([^\/]+?)\/?$/i// keys = [{ name: 'bar', prefix: '/', delimiter: '/', optional: false, repeat: false, pattern: '[^\\/]+?' }]
delimiter:重复参数的定界符,默认是 ‘/‘,可配置
一些其他常用的路由正则通配符:
- ? 可选参数
- 匹配 0 次或多次
- 匹配 1 次或多次
如果忘记写参数名字,而只写了路由规则,比如下述代码中 /:foo 后面的参数:
var re = pathToRegexp('/:foo/(.*)', keys)// 匹配除“\n”之外的任何字符// keys = [{ name: 'foo', ... }, { name: 0, ...}]re.exec('/test/route')//=> ['/test/route', 'test', 'route']
它也会被正确解析,只不过在方法处理的内部,未命名的参数名会被替换成数组下标。
取路由参数
path 带的参数,可以通过 this.props.match 获取
例如:
// url 为 /book/:pageType(edit|detail|add)const { match } = this.props;const { pageType } = match.params;
由于有 #,# 之后的所有内容都会被认为是 hash 的一部分,window.location.search 是取不到问号带的参数的。
比如:http://aaa.bbb.com/book-center/#/book/list?id=123
那么在 React-Router 中,问号带的参数,可以通过 this.props.location (官方推荐)获取。个人理解是因为 React-Router 做了处理,通过路由和 hash 值(window.location.hash)做了解析的封装。
例如:
// url 为 /book?pageType=editconst { location } = this.props;const searchParams = location.search; // ?pageType=edit
实际打印 props 参数发现,this.props.history.location 也可以取到问号参数,但不建议使用,因为 React 的生命周期(componentWillReceiveProps、componentDidUpdate)可能使它变得不可靠。(原因可参考:https://blog.csdn.net/zrq1210/article/details/108403772)
在早期的 React-Router 2.0 版本是可以用 location.query.pageType 来获取参数的,但是 V4.0 去掉了(有人认为查询参数不是 URL 的一部分,有人认为现在有很多第三方库,交给开发者自己去解析会更好,有个对此讨论的 Issue,有兴趣的可以自行获取 😊 https://github.com/ReactTraining/react-router/issues/4410)
针对上一节中场景 1 的 Case C,查询参数隐身式带法时(从 state 里带过去的),在 this.props.location.state 里可以取到(不推荐,刷新会没~)
Switch
<div><Routepath="/router/:type"render={() => <div>影像</div>}/><Routepath="/router/book"render={() => <div>图书</div>}/></div>
如果 <Route /> 是平铺的(用 div 包裹是因为 Router 下只能有一个元素),输入 /router/book 则影像和图书都会被渲染出来,如果想要只精确渲染其中一个,则需要 Switch
<Switch><Routepath="/router/:type"render={() => <div>影像</div>}/><Routepath="/router/book"render={() => <div>图书</div>}/></Switch>
Switch 的意思便是精准的根据不同的 path 渲染不同 Route 下的组件。但是,加了 Switch 之后路由匹配规则是从上到下执行,一旦发现匹配,就不再匹配其余的规则了。因此在使用的时候一定要“百般小心”。
上面代码中,用户访问 /router/book 时,不会触发第二个路由规则(不会展示“图书”),因为它会匹配 /router/:type 这个规则。因此,带参数的路径一般要写在路由规则的底部。
路由的基本原理
路由做的事情:管控 URL 变化,改变浏览器中的地址。
Router 做的事情:URL 改变时,触发渲染,渲染对应的组件。
URL 有两种,一种不带 #,一种带 #,分别对应 Browse 模式和 Hash 模式。
一般单页应用中,改变 URL,但是不重新加载页面的方式有两类:
Case 1(会触发路由监听事件):点击 前进、后退,或者调用的 history.back( )、history.forward( )
Case 2(不会触发路由监听事件):组件中调用 history.push( ) 和 history.replace( )
针对上述两种 Case,以及这两种 Case 分别对应的两种模式,作出如下总结。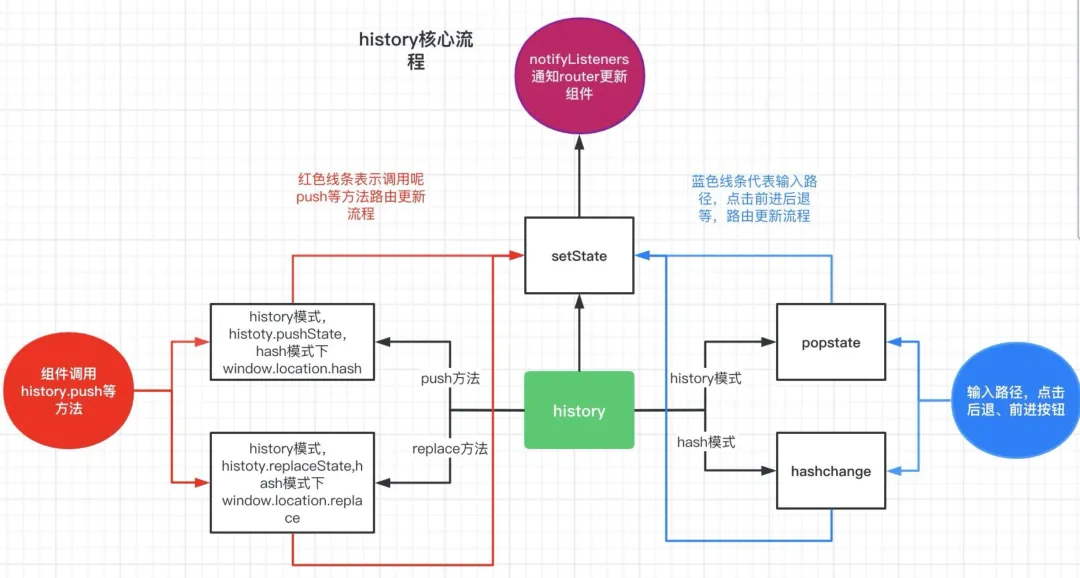
Browser 模式
Case 1:
URL 改变,触发路由的监听事件 popstate,then,监听事件的回调函数 handlePopState 在回调中触发 history 的 setState 方法,产生新的 location 对象。state 改变,通知 Router 组件更新 location 并通过 context 上下文传递,匹配出符合的 Route 组件,最后由 <Route /> 组件取出对应内容,传递给渲染页面,渲染更新。
/* 简化版的 handlePopState (监听事件的回调) */const handlePopState = (event)=>{/* 获取当前location对象 */const location = getDOMLocation(event.state)const action = 'POP'/* transitionManager 处理路由转换 */transitionManager.confirmTransitionTo(location, action, getUserConfirmation, (ok) => {if (ok) {setState({ action, location })} else {revertPop(location)}})}
Case 2:
以 history.push 为例,首先依据要跳转的 path 创建一个新的 location 对象,然后通过 window.history.pushState (H5 提供的 API )方法改变浏览器当前路由(即当前的 url),最后通过 setState 方法通知 Router,触发组件更新。
const push = (path, state) => {const action = 'PUSH'/* 创建location对象 */const location = createLocation(path, state, createKey(), history.location)/* 确定是否能进行路由转换 */transitionManager.confirmTransitionTo(location, action, getUserConfirmation, (ok) => {... // 此处省略部分代码const href = createHref(location)const { key, state } = locationif (canUseHistory) {/* 改变 url */globalHistory.pushState({ key, state }, null, href)if (forceRefresh) {window.location.href = href} else {/* 改变 react-router location对象, 创建更新环境 */setState({ action, location })}} else {window.location.href = href}})}
Hash 模式
Case 1:
增加监听,当 URL 的 Hash 发生变化时,触发 hashChange 注册的回调,回调中去进行相类似的操作,进而展示不同的内容。
window.addEventListener('hashchange',function(e){/* 监听改变 */})
Case 2:
history.push 底层调用 window.location.hash 来改变路由。history.replace 底层是调用 window.location.replace 改变路由。然后 setState 通知改变。
从一些参考资料中显示,出于兼容性的考虑(H5 的方法 IE10 以下不兼容),路由系统内部将 Hash 模式作为创建 History 对象的默认方法。
Dva/Router
在实际项目中发现,Link,Route 都是从 dva/router 中引进来的,那么,Dva 在这之中做了什么呢?
答案:貌似没有做特殊处理,Dva 在 React-Router 上做了上层封装,会默认输出 React-Router (https://github.com/ReactTraining/react-router) 接口。
对 Router 做过的一些处理
Case 1:
项目代码的 src 目录下,不管有多少文件夹,路由一般会放在同一个 router.js 文件中维护,但这样会导致页面太多时,文件内容会越来越长,不便于查找和修改。
因此可以做一些小改造,在 src 下的每个文件夹中,创建自己的路由配置文件,以便管理各自的路由。但这种情况下 React-Router 是不能识别的,于是写了一个 Plugin 放在 Webpack 中,目的是将各个文件夹下的路由汇总,并生成 router-config.js 文件。之后,将该文件中的内容解析成组件需要的相关内容。
Case 2:
路由的 Hash 模式虽然兼容性好,但是也存在一些问题:
- 对于 SEO、前端埋点不太友好,不容易区分路径
- 原有页面有锚点时,使用 Hash 模式会出现冲突
因此公司内部做了一次 Hash 路由转 Browser 路由的改造。
如原有链接为:http://aaa.bbb.com/book-center/#/book/list?id=123
改造方案为:
通过新增以下配置代码去掉 #
import createHistory from 'history/createBrowserHistroy';const app = dva({history: createHistory({basename: '/book-center',}),onError,});
同时,为了避免用户访问旧页面出现 404 的情况,前端需要在 Redirect 中配置重定向以及在 Nginx 中配置旧的 Hash 页面转发。
Case 3:
在实际项目中,其实也会去考虑用户未授权时路由跳转、页面 404 时路由跳转等不同情况,以下 Case 和代码仅供参考~
<Switch>{getRoutes(match.path, routerData).map(item =>(// 用户未授权处理,AuthorizedRoute 为项目中自己实现的处理组件<AuthorizedRoute{...item}redirectPath="/exception/403"/>))}// 默认跳转页面<Redirect from="/" exact to="/list" />// 页面 404 处理<Route render={props => <NotFound {...props} />} /></Switch>

若有收获,就点个赞吧
0 人点赞
