前言
- 此笔记的内容来源主要为 【圣思园-深入理解 netty-张龙】视频课程,中间针对某些知识点会参考其他博文来补充自己的理解,代码样例及说明可访问 我的 github;
- 源教学视频地址,共 92 个学时,我在学的过程中跳过了 P23-P31 有关 gRPC 的内容;
刚学 java 不久,初次分享笔记,很多地方还很粗糙,某些笔记可能还有错,请多指正,一起好好学习~
Java NIO 与 零拷贝
I/O 流的概念
Java 程序通过流来完成输入/输出,流是生产或消费信息的抽象,流通过 Java 的输入/输出系统与物理设备链接,尽管与它们链接的物理设备不尽相同,所有流的行为却具有同样的方式,这样,相同的输入/输出类和方法适用于所有类型的外部设备,这意味着一个输入流能够抽象多种不同类型的输入:从磁盘文件,从键盘或从网络套接字,同样,一个输出流可以输出到控制台,磁盘文件或相连的网络,流是处理输入/输出的一个洁净的方法,例如它不需要代码理解键盘和网络的不同,Java 中流的实现是在 java.io 包定义的类层次结构内部的;
- 输入/输出时,数据在通信通道中流动,所谓“数据流(stream)”指的是所有数据通信通道之中,数据的起点和终点,信息的通道就是一个数据流,只要是 数据从一个地方“流”到另外一个地方,这种数据流动的通道都可以称为数据流;
- 输入/输出是相对于程序来说的,程序在使用数据时所扮演的角色有两个:一个是源,一个是目的,若程序是数据流的源,即数据的提供者,这个数据流对程序来说就是一个“输出数据流”(数据从程序流出),若程序是数据流的终点,这个数据流对程序而言就是一个“输入数据流”(数据从程序外流向程序);
- 在 java.io 包中提供了 60 多个类(流),从功能上分为两大类:输入流和输出流,从流结构上可分为字节流(以字节为处理单位或称面向字节)和字符流(以字符为处理单位或称面向字符),字节流的输入流和输出流基础是 InputStream 和 OutputStream 这两个抽象类,字节流的输入输出操作由这两个类的子类实现,字符流是 Java1.1 版后新增加的以字符为单位进行输入输出处理的流,字符流输入输出的基础是抽象类 Reader 和 Writer;
- 在最底层,所有的输入/输出都是字节形式的,基于字符的流只为处理字符提供方便有效的方法;
- 读/写数据的逻辑:1)open a stream; 2)while more information; 3)read/write imformation; 4)close the stream;
- 流的分类:节点流和过滤流
- InputStream 和 OuputStream 的方法
-
Java NIO
java.io 中最为核心的一个概念是流(Stream),面向流的编程,一个流不能同时具备输入流和输出流两种属性;
- java.nio 中有3个核心概念:Selector、Channel 和 Buffer,在 java.nio 中是面向块(block)或是缓冲区(buffer)编程的,在实现上实际就是个数组,数据的读写都是通过 buffer 来实现的;
- 除了数据之外, buffer 还提供了对于数据的结构化访问方式,并且可以追踪到系统的读写过程;
- Java 中的 7 种原生数据类型都有各自对应的 Buffer 类型,如 IntBuffer、LongBuffer、ByteBuffer 及 CharBuffer 等,但没有 BooleanBuffer;
- Channel 指的是可以向其写入数据或是从中读取数据的对象,它类似于 java.io 中的 Stream;
- 所有数据的读写都是通过 Buffer 来进行的,永远不会出现直接向 Channel 写入数据或读取数据的情况;
- 与 Stream 不同的是,Channel 是双向的,一个流只可能是 InputStream 或 OutputSream,Channel 打开后则可以进行读取、写入或是读写,由于 Channel 是双向的,因为它能更好的反映出底层操作系统的真实情况,在 Linue 系统中,底层操作系统的通道就是双向的;
- DirectByteBuffer 如何实现零拷贝的
- DirectByteBuffer 是存储在 java 堆上的一个标准的 java 对象,持有一个对堆外内存的引用地址 address,以实现内存的直接访问【直接缓冲区】,而 HeapByteBuffer 通过将堆内内存拷贝到操作系统中的 native 内存实现与外围 io 设备的访问【间接缓冲区】,这样做的主要是因为 java 的垃圾回收机制,会破坏堆内内存地址序列,相较 HeapByteBuffer,DirectByteBuffer 通过一个引用地址实现了零拷贝;
- 相关内容可参考博文 Java NIO DirectByteBuffer 的使用与研究
P77 中复习 NIO 时推荐的知乎一篇大神的回答 Java NIO中,关于DirectBuffer,HeapBuffer的疑问?
传统 IO 有四次上下文切换(read-用户-内核,read-内核-用户,write-用户-内核,write-内核-用户)和四次(磁盘->内核 buffer, 内核 buffer->用户 buffer,用户 buffer->内核 socket, 内核 socket->协议引擎),其中用户和内核之间的两次拷贝是不必要的(内核 buffer->用户 buffer,用户 buffer->内核 socket);
- 用户空间仅作为临时存放数据的载体
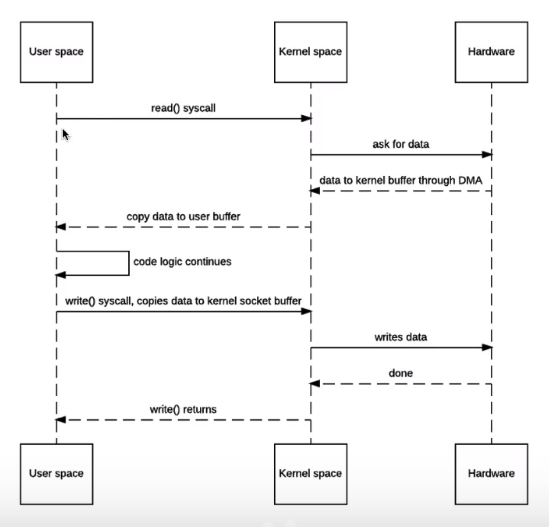
NIO 零拷贝
- 零拷贝是完全依赖于底层操作系统的(linux、unix);
- 零拷贝是指相比传统 io 不再有用户空间和内核空间的中间两次拷贝(内核 buffer->用户 buffer,用户 buffer->内核 socket) ,但内核空间存在【内核 buffer->内核 socket】 的拷贝;
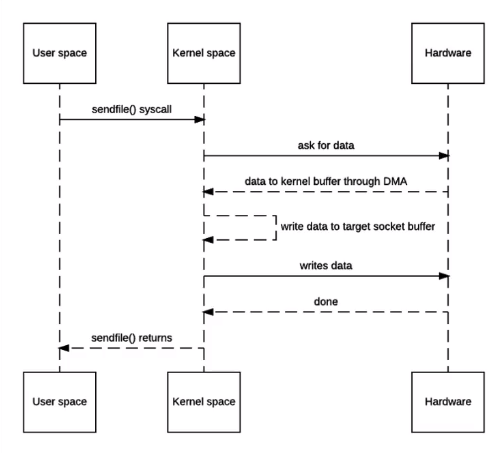
- 进一步的利用 DMA 的 scatter/gather 来省去【内核 buffer->内核 socket】 的拷贝,在这种操作下,io 的读写在用户空间就成了“黑盒”,为了让用户能够参与,引入了 MappedByteBuffer 来对内存地址进行映射;
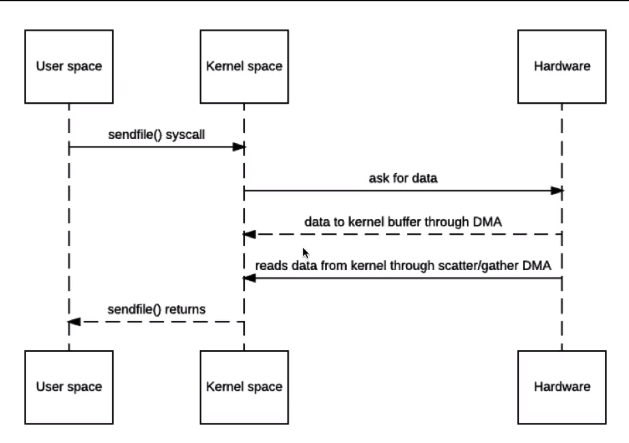
- 具体的零拷贝过程如下图所示:将磁盘上的文件拷贝到内核空间的 kernal buffer 中,然后把 kernal buffer 的文件描述符拷贝到内核空间的 socket buffer 中,protocol engine(协议引擎)将两个 buffer 的内容 gather 到一起,将文件直接从 kernal buffer 拷贝到服务端,其中文件描述符包含两个信息:1) kernal buffer 在内存中的位置,2)kernal buffer 的长度;
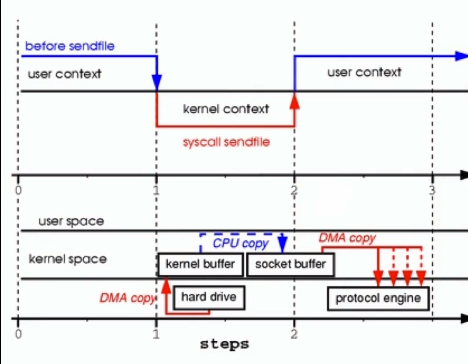
Netty 原理分析
Reactor 模式
有关 NIO 和 Reactor 两篇经典论文:
- Scalable IO in Java
Reactor - An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events
Reactor 模式的角色构成(Reactor 模式一共有5种角色构成)
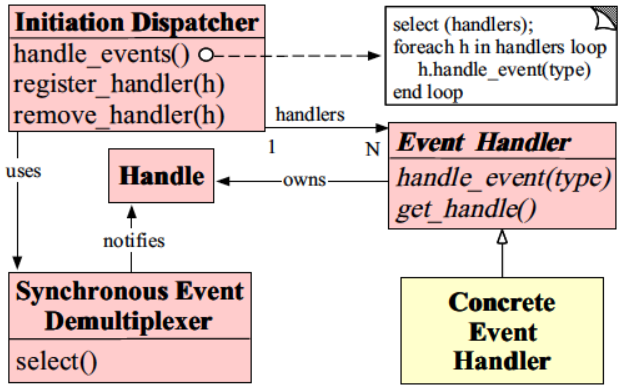
- Handle(句柄或是描述符):本质上表示一种资源,是由操作系统提供的;该资源用于表示一个个的事件,比如说文件描述符,事件既可以来自于外部,也可以来自于内部;外部事件比如说客户端的连接请求,客户端发送过来数据等;内部事件比如说操作系统产生的定时器事件等,它本质上就是一个文件描述符,Handle 是事件产生的发源地;
- Synchronous Event Demultiplexer(同步事件分离器):它本质上是一个系统调用,用于等待事件的发生(事件可能是一个,也可能是多个),调用方法在调用它的时候会被阻塞,一直阻塞到同步事件分离器上有事件产生为止,对于 Linux 来说,同步事件分离器指的就是常用的 I/O 多路复用机制,比如说 select、poll、epoll 等,在 Java NIO 领域中,同步事件分离器对应的组件就是 Selector,对应的阻塞方法就是 select 方法;
- Event Handler(事件处理器):本身由多个回调方法构成,这些回调方法构成了与应用相关的对于某个事件的反馈机制,Netty 相比于 Java NIO 来说,在事件处理器这个角色上进行了一个升级,它为我们开发者提供了大量的回调方法,供我们在特定事件产生时实现相应的回调方法进行业务逻辑的处理;
- Concrete Event Handler(具体事件处理器):是事件处理器的实现,它本身实现了事件处理器所提供的各个回调方法,从而实现了特定于业务的逻辑,它本身就是我们所编写的一个个的处理器的实现;
- Initiation Dispatcher(初始分发器):实际上就是 Reactor 角色,它本身定义了一些规范,这些规范用于控制事件的调度方式,同时又提供了应用进行事件处理器的注册、删除等设施,它本身是整个事件处理器的核心所在,Initiation Dispatcher 会通过同步事件分离器来等待事件的发生,一旦事件发生,Initiation Dispatcher 会先分离出每一个事件,然后调用事件处理器,最后调用相关的回调方法来处理这些事件;
完整的事件处理流程
当应用向 Initiation Dispatcher 注册具体的事件处理器时,应用会标识出该事件处理器希望 Initiation Dispatcher 在某个事件发生时向其通知的事件,该事件与 Handler 关联;
- Initiation Dispatcher 会要求每个事件处理器向其传递内部的 Handler,该 Handler 向操作系统标识了事件处理器;
- 当所有的事件处理器注册完毕后,应用会调用 handle_events 方法来启动 Initiation Dispatcher 的事件循环,这时 Initiation Dispatcher 会将每个注册的事件管理器的 Handle 合并起来,并使用同步事件分离器 Synchronous Event Demultiplexer 来等待这些事件的发生,比如说,TCP 协议层会使用 select 同步事件分离器来等待客户端发送的数据到达连接的 socket handle 上;
- 当与某个事件源对应的 Handle 变为 ready 状态时(如 TCP socket 变为等待读状态时),同步事件分离器就会通知 Initiation Dispatcher;
- Initiation Dispatcher 会触发事件处理器的回调方法,从而响应这个处于 ready 状态的 Handle,当事件发生时,Initiation Dispatcher 会将被事件源激活的 Handle 作为 【key】来寻找并分发恰当的事件处理器回调方法;
- Initiation Dispatcher 会回调事件处理器的 handle_events 方法来执行特定于应用的功能(开发者自己所编写的功能),从而响应这个事件,所发生的事件类型可以作为该方法参数并被该方法内部使用来执行额外的特定于服务的分离与分发;
小结
- 过程:首先在 Initiation Dispatcher 初始化之后,Dispatcher 会对多个 Event Handler 进行注册,每个 Handler 注册的同时需指定感兴趣的事件(类似于 NIO 中的 selectionKey),当 Event Handler 注册到 Initiation Dispatcher 之后,Initiation Dispatcher 会开启事件循环(死循环,同 Netty 的 EventLoopGroup),在事件循环中通过 Synchronous Event Demultiplexer 来等待事件的发生(连接事件、数据传输事件等),当感兴趣的事件在与 Event Handler 关联的 Handler 上产生时(Handler 属于 Event Handler), Synchronous Event Demultiplexer 会获取到感兴趣的事件的集合并返回给 Initiation Dispatcher,Initiation Dispatcher 通过 select(Handlers)找到与事件相关的处理器集合,遍历事件处理器,并根据事件类型通知具体事件处理器的 handle_event(type) 方法进行业务逻辑的处理;
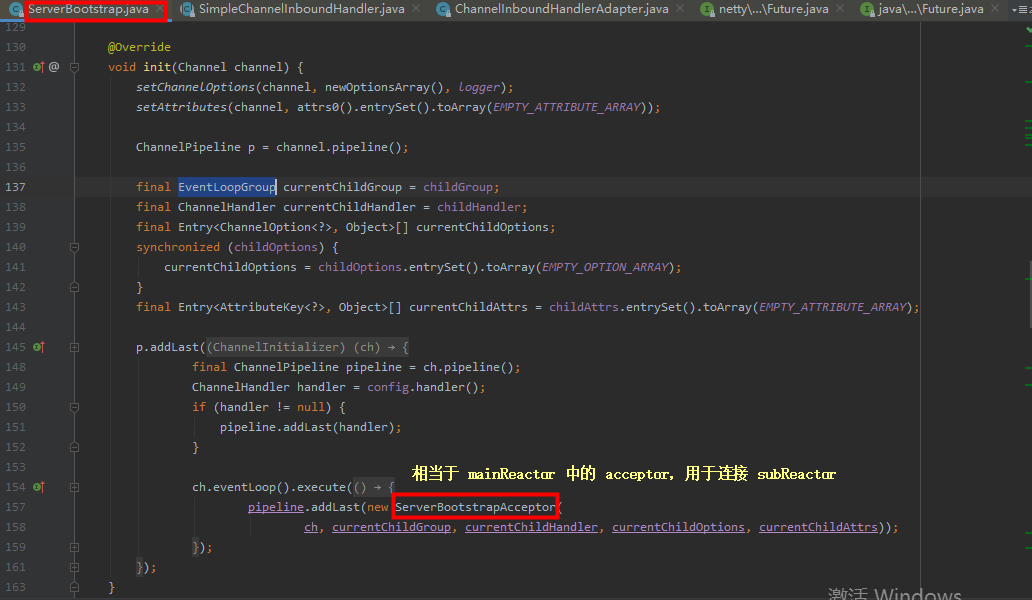
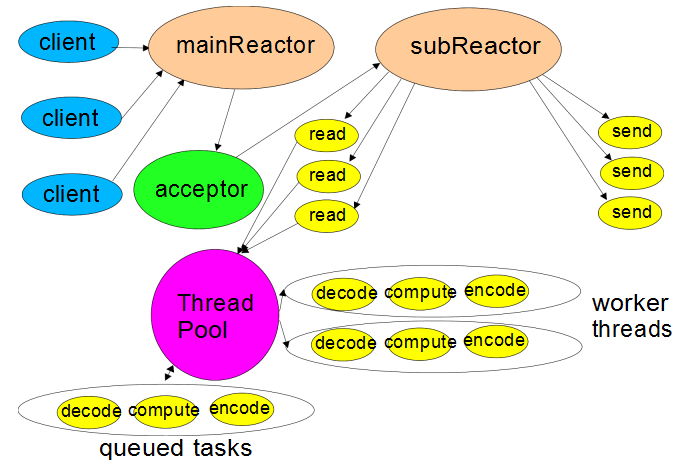
mainReactor 和 subReactor 分别对应 netty 中的 bossGroup(ParentGroup) 和 workerGroup (childGroup);
- acceptor 负责将 mainReactor 和 subReactor 连接起来,在 netty 中会在 socketChanne 的 pipline 上添加 serverBootstrapAcceptor 这样一个 Handler(ServerBootstrapAcceptor 是 ServerBootstrap 的一个静态内部类),在 serverBootstrapAcceptor 中通过 channelRead 方法来完成从 parent 到 child 的转换;
 Channel 相关
Channel 相关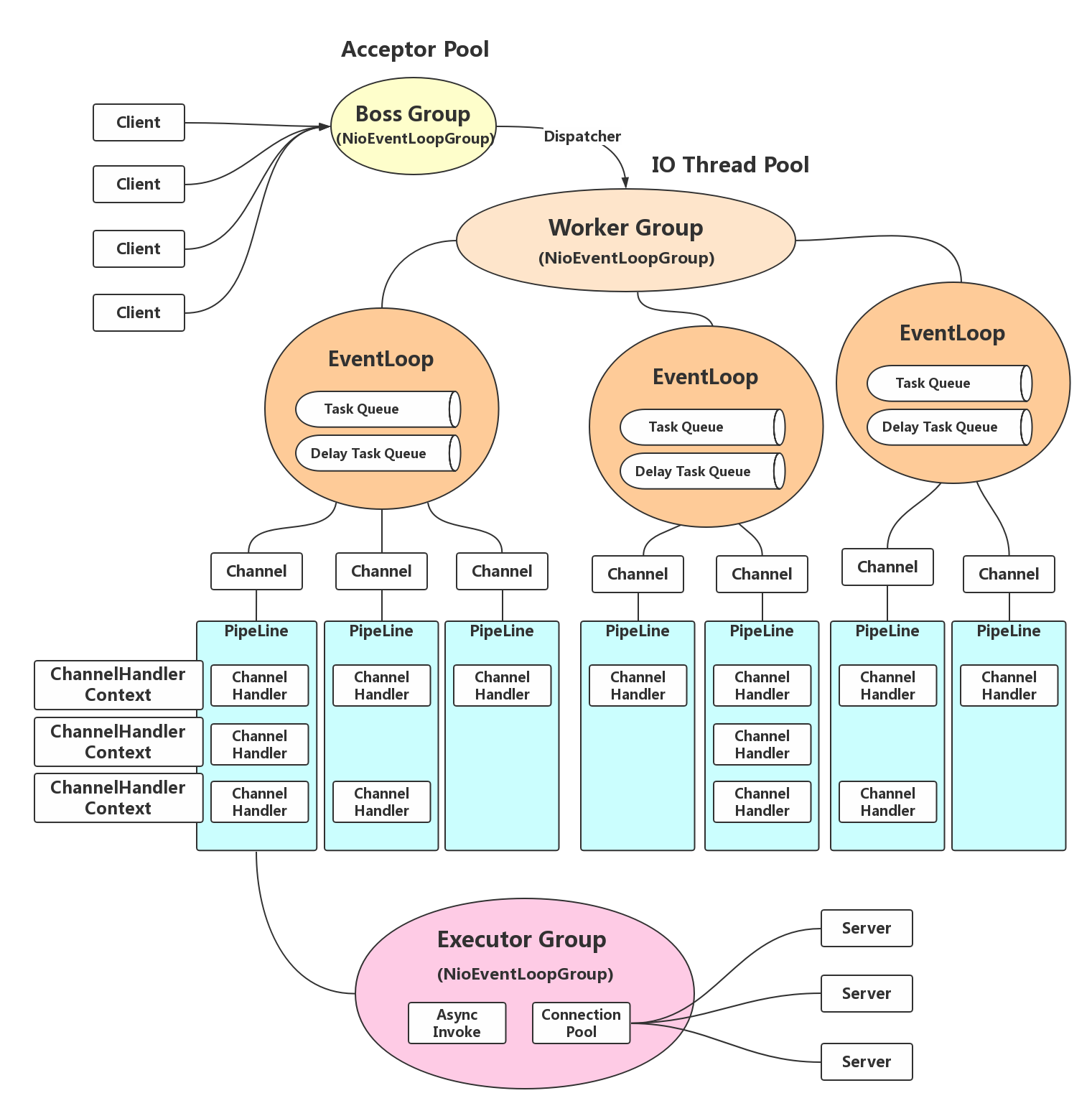
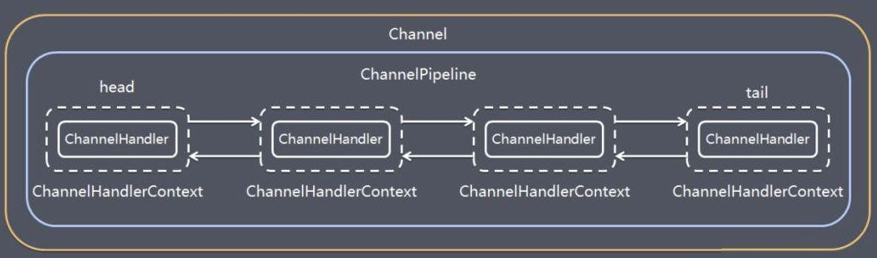
Channelpipline
总结在前面- ChannelPipeline 本身是一个容器,里边存放着一个一个的 ChannelHandlerContext 对象,而 Context 对象中维护着与之对应的 ChannelHandler 对象;
- 每个 Channel 都会绑定一个 ChannelPipeline,ChannelPipeline 中也会持有 Channel 的引用;
- ChannelPipeline 持有 ChannelHandlerContext 的双向循环链路,保留 ChannelHandlerContext 的头尾节点指针;
- 每个 ChannelHandlerContext 会对应一个 ChannelHandler,相当于 ChannelPipeline 持有 ChannelHandler的链路,表面是由 ChannelPipline 对 Handler 直接操作;
- ChannelHandlerContext 同时也会持有 ChannelPipeline 引用,也就相当于持有 Channel 引用;
- ChannelHandler 链路会根据 Handler 的类型,分为 InBound 和 OutBound 两条链路;
- ChannelHandlerContext 与 ChannelHandler 之间的关联绑定关系是永远不会发生改变的,因此对其进行缓存是没有问题的;
- 对于与 Channel 的同名方法来说,ChannelHandlerContext 将会产生更短的事件流,所以我们应该在可能的情况下利用这个特性来提升应用性能;
Channel 与 ChannelPipline 的关系
Each channel has its own pipeline and it is created automatically when a new channel is created.
- 数量关系:channelpipline 与 channel 为一对一的关系;
- 创建顺序:为 channel 由 channelFactory 反射创建时,在 channel 的构造器中通过 newChannelPipeline() 方法自动创建 defaultChannelPipline,ChannelPipeline 中也会持有 Channel 的引用;
- 创建时机:
- 准备工作
- 1.1 自定义的 netty 服务端相关代码,主要是传入 channel 的实例类型
serverBootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).
handler(new LoggingHandler(LogLevel._INFO_)).childHandler(new TestServerIniatializer());
- 1.2 AbstractBootstrap.java ,创建 ReflectiveChannelFactory 并传入 channel的实例类型
public B channel(Class<? extends C> channelClass) {
return channelFactory(new ReflectiveChannelFactory<C>(ObjectUtil._checkNotNull_(channelClass, "channelClass")));
} 2.创建过程
- 2.1 自定义的 netty 服务端相关代码
ChannelFuture channelFuture = serverBootstrap.bind(new InetSocketAddress(8899)).sync();
- 2.2 AbstractBootstrap.java,只列出关键代码
- dobind()
private ChannelFuture doBind(final SocketAddress localAddress) {
**final ChannelFuture regFuture = initAndRegister(); ** final Channel channel = regFuture.channel(); ........}
- initAndRegister(),通过 ReflectiveChannelFactory 反射创建出 channel 实例
final ChannelFuture initAndRegister() {
**channel** = **channelFactory.newChannel(); ** init(channel); //此处涉及到 ChannelOption 及 AttributeKey}
- 2.3 在创建 channel 实例的过程中,也创建出 channelPipline,详见 AbstractChannel.java
protected AbstractChannel(Channel parent, ChannelId id) {
this.parent = parent; this.id = id; unsafe = newUnsafe();pipeline = newChannelPipeline(); }
ChannelPipeline 与 ChannelHandlerContext
使用场景:虽然在实际使用时 ChannelPipline 添加的是 ChannelHandler,表面上对 Handler 的操作,但中间其实是由 ChannelHandlerContext 在中间发挥着桥梁和纽带的作用;
public class TestServerIniatializer extends ChannelInitializer
{ @Overrideprotected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline(); pipeline.addLast(new TestServerHandler()); }}
ChannelPipeline 会维护一个 ChannelHandlerContext 的双向链表,详见 DefaultChannelPipeline.java;
public class DefaultChannelPipeline implements ChannelPipeline{ final AbstractChannelHandlerContext head; final AbstractChannelHandlerContext tail; // 1. filterName 方法中会判断传入的 handler 是否有自定义的 name,否则通过 generateName 方法生成 public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx; newCtx = newContext(group, filterName(name, handler), handler); //netty帮我们创建context对象 addLast0(newCtx); //向pipline中的双向链表中插入 context 对象 EventExecutor executor = newCtx.executor();callHandlerAdded0(newCtx); //真正实现 pipeline.addLast(new Handler())
}private void addLast0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext prev = tail.prev; newCtx.prev = prev;newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx; }}private void callHandlerAdded0(final AbstractChannelHandlerContext ctx) { ctx.callHandlerAdded(); } final void callHandlerAdded() throws Exception {if (setAddComplete()) {
handler().handlerAdded(this); }}
ChannelHandlerContext 的作用
- 使一个 ChannelHandler 能够与 ChannelPipline 或其他的 ChannelHandler 交互;
- 动态地修改所对应的 ChannelPipline 对象;
ChannelHandlerContext 与 Channel 调用同名方法的作用域差异
ChannelHandlerContext 中维护着 handler 字段,即每一个 context 对应着一个 ChannelHandler,反之则否;
private AbstractChannelHandlerContext newContext(EventExecutorGroup group, String name, ChannelHandler handler) { return new DefaultChannelHandlerContext(this, childExecutor(group), name, handler); } final class DefaultChannelHandlerContext extends AbstractChannelHandlerContext {
private final ChannelHandler handler;DefaultChannelHandlerContext(DefaultChannelPipeline pipeline,
EventExecutor executor, String name, ChannelHandler handler) { super(pipeline, executor, name, handler.getClass()); this.handler = handler; }ChannelHandler 与 ChannelHandlerContext 所对应 ChannelPipline 的关系
- ChannelHandler instance can be added to more than one ChannelPipeline. It means a single ChannelHandler instance can have more than one ChannelHandlerContext and therefore the single instance can be invoked with different ChannelHandlerContexts if it is added to one or more ChannelPipelines more than once.
- 一个 ChannelHandler 实例不仅可多次加入同一个 ChannelPipeline,还能加入不同 ChannelPipeline;
- 侧面说明了 pipeline.addLast(new ProtobufDecoder(MyDataInfo.MyMessage.getDefaultInstance())); 方法为什么需要对 Handler 进行命名;
- ChannelHandler 的功能: A list of ChannelHandlers which handles or intercepts inbound events and outbound operations of a Channel.
- An inbound handler usually handles the inbound data generated by the I/O thread,An outbound event is handled by the outbound handler;
- 与 tomcat 的 Filter、Interceptor 区别:过滤器和拦截器既会处理请求也能处理响应,而 netty 将入栈和出栈的处理器细分,分为 inboundHandler 和 outboundHandler,在自定义 handler 时必须实现这两者中的一个,之后依据 instanceOf 也能作区分;
- 一般不建议一个 handler 既实现 inboundHandler 接口,又实现 outboundHandler 接口,如果实现存在此功能需要,应该定义两个 handler 分别去实现这两个接口;
- inboundHandler 与 outboundHandler 的执行顺序,详见 博文
- inbound 事件在 pipeline 中传输方向是 head->tail,即从头到尾,而且会忽略 outbound 事件;
- outbound 事件在 pipeline 传输方向相反,会从 tail->head,即从尾到头,也会忽略 inbound 事件;
- AbstractChannelHandlerContext 上下文是共享的;
- 反向遍历开始的位置为正向遍历中找到的最后一个 inboundHandler;
/** 此图来自 ChannelPipline.java 的 javaDoc 文档
- I/O Request
- via {@link Channel} or
- {@link ChannelHandlerContext}
- |
- +—————————————————————————-+———————-+
- | ChannelPipeline | |
- | |/ |
- | +——————————-+ +—————-+—————+ |
- | | Inbound Handler N | | Outbound Handler 1 | |
- | +—————+—————+ +—————-+—————+ |
- | /|\ | |
- | | |/ |
| +—————+—————+ +—————-+—————+ |
| | Inbound Handler N-1 | | Outbound Handler 2 | |
| +—————+—————+ +—————-+—————+ |
| /|\ . |
| . . |
| ChannelHandlerContext.fireIN_EVT() ChannelHandlerContext.OUT_EVT()|
| [ method call] [method call] |
| . . |
| . |/ |
| +—————+—————+ +—————-+—————+ |
| | Inbound Handler 2 | | Outbound Handler M-1 | |
| +—————+—————+ +—————-+—————+ |
| /|\ | |
| | |/ |
| +—————+—————+ +—————-+—————+ |
| | Inbound Handler 1 | | Outbound Handler M | |
| +—————+—————+ +—————-+—————+ |
| /|\ | |
+———————-+—————————————————-+———————-+
| |/
+———————-+—————————————————-+———————-+
| | | |
| [ Socket.read() ] [ Socket.write() ] |
| |
| Netty Internal I/O Threads (Transport Implementation) |
+—————————————————————————————————-+
*/
补充 1:ChannelInitializer 与 ChannelInboundHandler 的关系
- A special ChannelInboundHandler which offers an easy way to initialize a Channel once it was registered to its EventLoop.
- ChannelInitializer 的作用仅仅是为一次性配置 channel 的 pipline 提供一个便捷的封装过的入口,并不能实际发挥 handler 的功能,在 pipline 中处理 event,会在 initChannel() 方法之后被移除;
serverBootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).
** handler**(new LoggingHandler(LogLevel._INFO_)).**childHandler**(new TestServerIniatializer());
补充 2:ChannelInboundHandlerAdapter 与 SimpleChannelInboundHandler 的关系
- 一般来说,用 Netty 接收或发送数据都会继承这两个类,而 SimpleChannelInboundHandler 又继承于 ChannelInboundHandlerAdapter,两者最主要的区别是 SimpleChannelInboundHandler 在接收到数据之后,会主动的 release 掉这个数据所占用的 bytebuf 资源;
- 在实际使用时要注意:如果继承 SimpleChannelInboundHandler 这个类,可能会出现从客户端发过来的 msg 还没 write(异步操作),就已经被自动地 release 掉;
// SimpleChannelInboundHandler.java @Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
boolean release = true; try { if (acceptInboundMessage(msg)) { @SuppressWarnings("unchecked") I imsg = (I) msg; channelRead0(ctx, imsg); //会调用自己实现的ChannelRead0} else {
release = false; ctx.fireChannelRead(msg); }
} finally { if (autoRelease && release) { **ReferenceCountUtil.****_release_****(msg)**; //引用计数回收}
}}
总结:Netty 处理器的重要概念
- Netty 处理器可分为两类:入站处理器和出站处理器;
- 入站处理器的顶层是 ChannelInboundHandler,出站处理器的顶层是 ChannelOutboundHandler;
- 数据处理时常用的各种编解码本质上都是处理器;
- 编解码器:无论我们向网络中写入的数据是什么类型(int、char、String、二进制等),数据在网络中传递时,其都是以字节流的形式呈现的;
AttributeKey allow you to store and access stateful information that is related with a handler and its
context.
- channelOption 和 attributeKey 的区别:channelOption 维护着 TCP/IP 底层的设定,而 attributeKey 是在程序运行过程中往里注入一些业务逻辑相关的 key-value 对象;
ChannelHandlerContext.attr(..) == Channel.attr(..)
- 在 netty 4.1 之后,context 与 channel 对象不再独立维护各自的 attributeMap,而是共享一个作用域为 channel 的 attributeMap,这样的优势有二:一是节省内存空间,二是便于context 与 context 或 context 与 channel 之间的 attr 获取;
- 我自己理解这个改进的实现,本身还是利用了 channel、channelpipline、channelHandlercontext 之间在设计理论上天生的强关联性;
Future、ChannelFuture 与 ChannelPromise
具体内容详见此 博文JDK 原生 Future 与 Netty 封装的 Future
jdk 底层已经有对 Future 的实现,用来执行异步操作并且提供相应对结果操作的方法,但其 get 方法还是一种阻塞的方式,需要调用者去主动获取;
在 Netty 内部实现了自己的 Future,并且继承了 jdk 中的 Future 接口,提供了一些额外的方法来针对在 netty中相关的异步 I/O 操作来进行处理;
public interface Future
extends java.util.concurrent.Future Netty 封装的 Future 相比 java.util.concurrent 原生的 Future 有什么好处
- 利用观察者模式(监听机制)来解决原生 Future 处理异步任务时需要主动地通过 get 阻塞式的方式获取结果,转换成异步任务处理之后 (down) 会自动触发对应 listener 的 operation,这样会更加优雅地在合理的时间来处理我们的逻辑代码;
- jdk 中 Future申明的 isDone方法,只能知道 I/O 是否结束,有可能是成功完成、被取消、异常中断,Netty 将 future 的 isDown 判断进一步细分为 isSuccess 判断出操作是否正真地成功完成;
Netty 的 ChannelFuture
public interface ChannelFuture extends Future
ChannelFuture 表示在 Channel 中异步 I/O 操作的结果;
相比 Future,ChannelFuture 添加了channel 方法来获取所对应的 Channel;
/** * Returns a channel where the I/O operation associated with this future takes place. */ Channel channel();由于 ChannelFuture 继承 Future 接口,所以可通过 ChannelFutureListener 以回调的方式来获取执行结果,避免手工检查阻塞的操作,需要注意的是 ChannelFutureListener 的 operationComplete 方法是由 I/O 线程执行的,因此不要在这里执行耗时操作,而是通过另外的线程或线程池来执行;
- 在 Netty 中所有的 I/O 操作都是异步的,I/O 的调用会直接返回,可以通过 ChannelFuture 来获取 I/O 操作的结果状态,对于多种状态的表示如下:
- 注意:failure 和 cancellation 都表示操作完成,但是对应的状态不同的,与 Future 类似,可以通过添加ChannelFutureListener 监听器,当I/O操作完成的时候来通知调用;
- +—————————————-+
- | Completed successfully |
- +—————————————-+
- +——> isDone() = true |
- +—————————————+ | | isSuccess() = true |
- | Uncompleted | | +===========================+
- +—————————————+ | | Completed with failure |
- | isDone() = false | | +—————————————-+
- | isSuccess() = false |——+——> isDone() = true |
- | isCancelled() = false | | | cause() = non-null |
- | cause() = null | | +===========================+
- +—————————————+ | | Completed by cancellation |
- | +—————————————-+
- +——> isDone() = true |
- | isCancelled() = true |
- +—————————————-+
- 注意:failure 和 cancellation 都表示操作完成,但是对应的状态不同的,与 Future 类似,可以通过添加ChannelFutureListener 监听器,当I/O操作完成的时候来通知调用;
Netty 的 ChannelPromise
- ChannelFuture 虽然通过 Listener 机制触发回调方法,但是不可以设置这次操作的结果,所以进一步提供了 ChannelPromise,依据 tryXX 和 setXX 方法来设置我们操作是成功还是失败;
ChannelPromise 是一种可写的特殊 ChannelFuture,定义了可以标识 Future 成功或者失败的方法,并且每一个 Future 只能够被标识一次,如果成功将会去通知之前所定义的 listeners;
public interface ChannelPromise extends ChannelFuture, Promise
对于 Promise public interface Promise extends Future 在 Netty 中,无论是服务端还是客户端,在 Channel 注册时都会为其绑定一个 ChannelPromise,默认实现是DefaultChannelPromise;
- DefaultChannelPromise 仅仅是将 Channel 封装了,而且基本上所有方法的实现都依赖父类 DefaultPromise,
即 DefaultPromise 中的实现是整个 ChannelFuture 和 ChannelPromise 的核心所在,具体介绍可参考此博文;
Channel 的线程安全性
- 一个 EventLoopGroup 当中会包含一个或多个 EventLoop;
- 一个 EventLoop 在它的整个生命周期当中都只会与唯一一个 Thread 进行绑定;
- 所有由 EventLoop 所处理的各种 I/O 事件都将在它所关联的那个 Thread 上进行处理;
- 一个 Channel 在它的整个生命周期中只会注册在一个 EventLoop 上;
- 一个 EventLoop 在运行过程当中,会被分配给一个或者多个 Channel;
Netty 消除 Channel 所有同步操作的设计
- 当执行 Channel 上的任何一个操作时,Netty 会判断当前正在所执行或调用的操作所对应的线程是否为 Channel 所对应的 EventLoop 里所包含的线程,如果是的话直接由 EventLoop 里的线程执行,如果否的话则将当前业务逻辑以任务的形式提交给 EventLoop,最终由 EventLoop 里的线程执行;
- 所有属于同一个 Channel 的操作任务,它们的提交顺序和执行顺序都是一样的;
重要结论
- 在 Netty 中,Channel 的实现一定是线程安全的,基于此,我们可以存储一个 Channel 的引用,并且在需要向远程端点发送数据时,通过这个引用来调用 Channel 相应的方法,即便当时有很多线程都在使用这个 Channel 也不会出现多线程问题,而且消息一定会按顺序发送出去;
- 在业务开发中,不要将长时间执行的耗时任务放入到 EventLoop 的执行队列中,因为它将会一直阻塞该线程所对应的所有 Channel 上的其它执行任务,如果我们需要进行进行阻塞调用或是耗时的操作(实际开发中很常见),那么就需要使用一个专门的 EventExecutor*(业务线程池);
1)heap buffer(堆缓冲区)
- 这是最常用的类型,Bytebuf 将数据存储到 JVM 的堆空间中,且将实际数据存放到 byte array 中来实现;
- 优点:由于数据存储在 JVM 的堆中,因此可快速创建与释放,且它提供了直接访问内部字节数组的方法;
- 缺点:每次读写数据时,都需要将数据复制到直接缓冲区中再进行网络传输;
- 2)direct buffer(直接缓冲区)
- 在堆之外直接分配内存空间,直接缓冲区并不会占用堆的容量空间,因为它是由操作系统在本地内存进行的数据分配;
- 优点:在使用 socket 进行数据传递时,性能非常好,因为数据直接位于操作系统的本地内存中,所以不需要从 JVM 将数据复制到直接缓冲区中,性能很好;
- 缺点:因为 Direct buffer 是直接在操作系统内存中的,所以内存空间的分配与释放要比堆空间更加复杂,而且速度要慢一些,Netty 通过提供内存池来解决这个问题;
- 直接缓冲区并不支持通过字节数组的方法来访问数据;
- 3)composite bytebuf(复合缓冲区)
- 重点:对于后端的业务消息的编解码来说,推荐使用 HeapByteBuf,对于 I/O 通信线程在读写缓冲区时,推荐使用 DirectByteBuf;
JDK 的 ByteBuf 与 Netty 的 ByteBuf 之间的差异对比
- Netty 的 ByteBuf 采用了读写分离的策略(readIndex 与 writeIndex),一个初始化(里面尚未有任何数据)的ByteBuf 的 readIndex 与 writeIndex 值都为 0;
- 当读索引与写索引处于同一个位置时,如果我们继续读取,那么就会抛出 IndexOutOfBoundsException;
- 对于 ByteBuf 的任何读写操作都会分别单独维护读索引和写索引,maxCapacity 最大容量默认的限制就是 Integer.MAX_VALUE;
- JDK 的 ByteBuf 的缺点
- fianl byte[] hb:这是 JDK 的 ByteBuffer 对象中用于存储数据的对象声明,可以看到,其字节数组是被声明为 final 的,也就是长度是固定不变的,一旦分配好不能动态扩容与收缩,而且当待存储的数据字节很大时就很有可能出现 IndexOutOfBoundsException,如果要预防这个异常,那就需要在存储之前完全确定好待存储字节大小,如果 ByteBuffer 的空间不足,我们只有一种解决方案:创建一个全新的 ByetBuffer 对象,然后再将之前的 ByteBuffer 中的数据复制过去,这一切操作都需要由开发者自己来手动完成;
- ByteBuffer 只使用一个 position 指针来标识位置信息,在进行读写切换时就需要调用 flip 或 rewind 方法,使用起来很不方便;
- Netty 的 ByteBuf 的优点
- 存储字节的数组是动态的,其最大值默认为 Integer.MAX_VALUE,这里的动态性是体现在 write 方法中的,write 方法在执行时会判断 buffer 容量,如果不足则自动扩容;
- ByteBuf 的读写索引是完全分开的,使用起来就很方便;
ByteBuf 与 ReferenceCountedObject
- 参考 Netty 官方文档 https://netty.io/wiki/reference-counted-objects.html,译文
其他
AtomicIntegerFiledUpdater 要点总结
- 参考 Netty 官方文档 https://netty.io/wiki/reference-counted-objects.html,译文
更新器更新的必须是 int 类型变量,不能是其包装类型;
- 如果要更新的变量是包装类型,那么可以使用 AtomicReferenceFiledUpdater 来进行更新;
- 更新器更新的必须是 volatile 类型变量,确保线程之间共享变量时的立即可见性;
- 变量不能是 static 的,必须要是实例变量,因为 Unsafe.objectFieldOffset() 方法不支持静态变量(CAS 操作本质上是通过对象实例的偏移量来直接进行赋值);
更新器只能修改它可见范围内的变量,因为更新器是通过反射来得到这个变量,如果变量不可见就会报错;
Netty 介绍
Netty是一个异步事件驱动的网络应用框架,用于快速开发可维护的高性能服务器和客户端,封装了 jdk 原生的 NIO;
- Netty 的优势
- 服务端和客户端的统一 API;
- 不仅支持 NIO,也向下适应,提供了 OIO,即阻塞式 IO;
- 使用 netty 能做什么
- http 服务器,如 tomcat 可以处理请求和响应,netty 并没有实现 servlet 标准,这个 servlet 规范定义了请求是什么样子,我们如何去获取请求中的参数,netty 更底层,吞吐量比 tomcat 要高,适合高并发场景,但开发效率较低,而且相较 springmvc,netty 需手动实现请求路由这一功能;
- socket 开发,netty 可以接触到更底层的协议;
- 支持长连接的开发,websocket 是 html5 中的一个组成部分,相较 http1.0 可以维持较长时间的连接,而且可以实现浏览器和服务端的一个全双工的通讯,即服务端可以向客户端推送消息,此外,也不要求必须传输 header 信息,可以只传输必要的数据信息;
- 开发共通的步骤
- 定义 bossGroup 和 workerGroup,一个负责处理连接请求,一个负责数据传输;
- 定义一个启动类 serverBootstrap,将定义的两个 group 填入,并通过 childHandler 将自定义的 ServerInitializer() 方法填入;
- 在 ServerInitializer 中通过 pipline 添加 netty 已有或自定义的 handler;
- 在自定义的 handler 中覆写已有的 handler 方法;
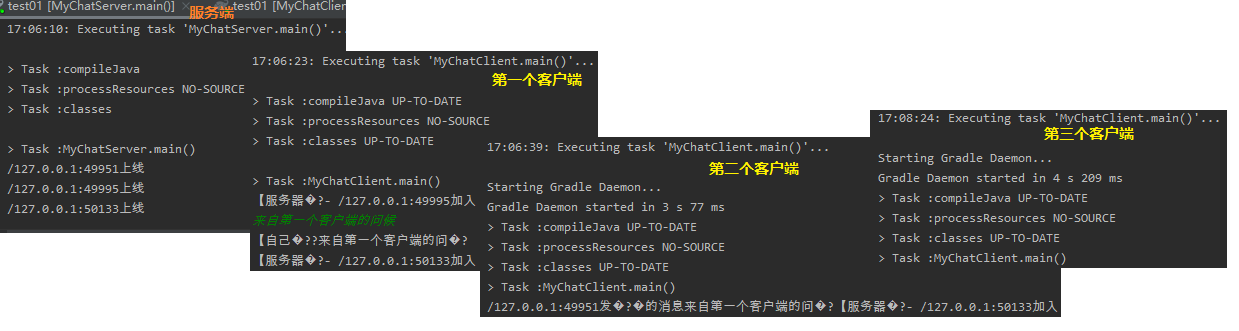
- Netty Socket 编程-多客户端的连接与通信
- 长连接 + 心跳包
- webSocket
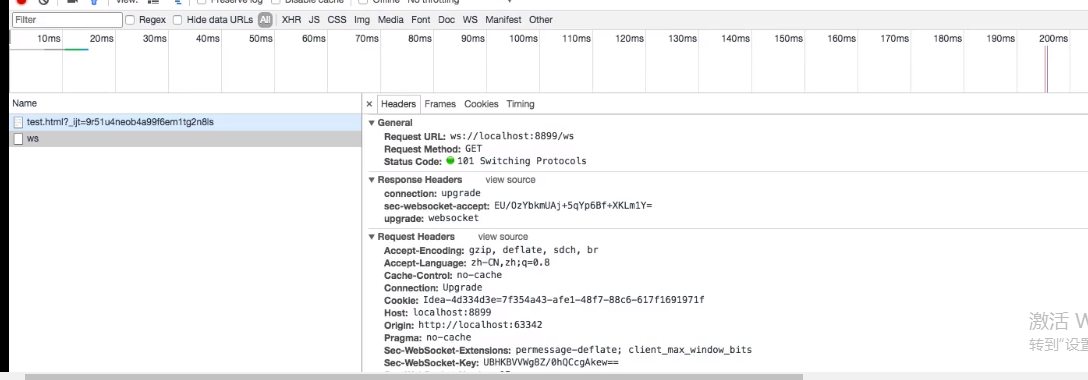
- webSocket 可以建立真正意义上的长连接,且通信双方是一种对等关系(全双工);
- webSocket 协议是基于 http 协议的,在首次建立连接的时候通过 http 协议在 header 中注入 webSocket 信息,在服务端接收到后会将 http 升级为 webSocket,之后只需要传输数据既可;
- webSocket 虽然是 HTML 的一部分,但是也支持f非浏览器的场合;
- RMI 与 RPC 的区别
- RMI : remote method invocation,只针对 java
- client:stub server:skeleton ; 序列化与反序列化(编码与解码)
- RPC:remote procedure call 远程过程调用,很多 RPC 框架都是跨语言的;
- 定义一个接口说明文件:描述了对象(结构体)、对象成员、接口方法等一系列信息;
- 通过 RPC 框架所提供的编译器,将接口说明文件编译成具体语言文件;
- 在客户端和服务器端分别引入 RPC 编译器所生成的文件,即可像调用本地方法一样调用远程方法;
- RMI : remote method invocation,只针对 java
protocol buffers
- protobuf集成netty实现多协议消息传递 https://blog.csdn.net/weixin_38950807/article/details/90414340
Thrift 相比 protobuf,不仅可以定义数据结构,而且也能定义客户端和服务端的传输机制,当然传输也可通过 netty 实现;
- Thrift 最初由 Facebook 研发,主要用于各个服务之间的 RPC 通信,支持跨语言,如 C++、Java、Python、PHP、Ruby、Erlang、Perl、Haskell、C#、Cocoa、JavaScript、Node.js、Smalltalk、OCaml 等;
- Thrift 是一个典型的 CS (客户端/服务端)结构,客户端和服务端可以使用不同的语言开发,既然客户端和服务端能使用不同的语言开发,那么一定就要有一种中间语言来关联客户端和服务端的语言,这种语言就是 IDL(Interface Description Language);
- Thrift 元素
- 数据类型
- Thrift 不支持无符号类型,因为很多编程语言不存在无符号类型,比如 Java;
byte:有符号字节; i16:16位有符号整数; i32:32位有符号整数; i64:64位有符号整数; double:64位浮点数; string:字符串;
- Thrift 容器类型:集合中的元素可以是除了 service 之外的任何类型,包括 exception;
- list:一系列由 T 类型的数据组成的有序列表,元素可以重复;
- set:一系列由 T 类型的数据组成的无序集合,元素不可重复;
- map:一个字典结构,key 为 K 类型,value 为 V 类型,相当于 Java 中的 HashMap;
- 数据类型
- Thrift 工作原理
- 如何实现多语言之间的通信
- 数据传输使用 socket(多种语言均支持),数据再以特定的格式(string 等)发送,接收方语言进行解析;
- 定义 thrift 的文件,由 thrift 文件(IDL)生成双方语言的接口、model,在生成的 model 以及接口中会有解码编码的代码;
- 如何实现多语言之间的通信
- Thrift IDL 文件 ```java //1. Thrift 的命名空间相当于 Java 中的 package 的意思,主要目的是组织代码; namespace java com.cyt.thrift.demo【格式:namespace 语言名 路径】
//2. Struct 结构体:就像C语言一样支持 struct 类型,目的就是将一些数据聚合在一起,方便传输管理 struct Account{ 1: required string password, //密码 2: optional i64 createTime, //创建时间 3: i64 lastLoginTime, //最后登录时间 4: i32 loginCount, //登陆次数 5: bool enabled=true, }
//3. Thrift 支持自定义异常(exception),规则与 struct 一样 exception RequestException{ 1:i32 code; 2:string reason; }
//4. Thrift 定义服务相当于 Java 中创建 Interface 一样,创建的 service 经过代码生成命令之后就会生成客户端和服务端的框架代码 service HelloWorldService{ //service 中定义的函数相当于 java interface 中定义的方法 string doAction(1:string name,2:i32 age); }
//5. Thrift 支持类似 C++ 一样的 typedef 定义,如: typedef i32 int; //6. Thrift 支持常量定义,使用 const 关键字,如: const i32 MAX_RETRIES_TIME = 10; //7. Thrift 支持文件包含,相当于 C/C++ 中的 include,Java 中的 import,如: include “global.thrift”; //8. Thrift 注释方式不仅支持 shell 风格,而且也支持 C/C++ 风格,如 #, //, /**/; ```
- Thrift 生成代码
- 在定义好 thrift 文件之后,需要用此文件来生成我们所需要的目标语言的源码;
- 首先需要定义 thrift 接口描述文件
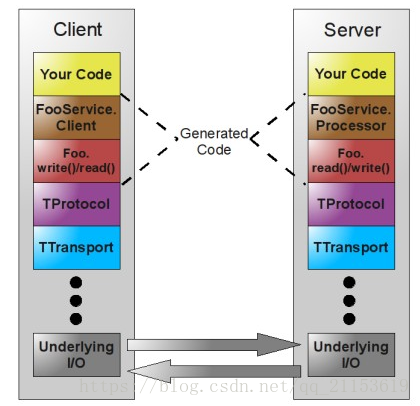

图中,TProtocol(协议层),定义数据传输格式,例如:
- TBinaryProtocol:二进制格式;
- TCompactProtocol:压缩格式;
- TJSONProtocol:JSON格式;
- TSimpleJSONProtocol:提供JSON只写协议, 生成的文件很容易通过脚本语言解析;
- TDebugProtocol:使用易懂的可读的文本格式,以便于debug
TTransport(传输层),定义数据传输方式,可以为TCP/IP传输,内存共享或者文件共享等)被用作运行时库。
- TSocket:阻塞式socker;
- TFramedTransport:以frame为单位进行传输,非阻塞式服务中使用;
- TFileTransport:以文件形式进行传输;
- TMemoryTransport:将内存用于I/O,java实现时内部实际使用了简单的ByteArrayOutputStream;
TZlibTransport:使用zlib进行压缩, 与其他传输方式联合使用,当前无java实现;
Thrift支持的服务模型TSimpleServer:简单的单线程服务模型,常用于测试;
- TThreadPoolServer:多线程服务模型,使用标准的阻塞式IO;
- TNonblockingServer:多线程服务模型,使用非阻塞式IO(需使用TFramedTransport数据传输方式);
- THsHaServer:引入了线程池去处理,其模型把读写任务放到线程池去处理:Half-sync/Half-async(半同步半异步)的处理模式,Half-sync是在处理IO事件上(accept/read/write io),Half-async用于handler对rpc的同步处理;
Netty 架构实现
Netty 模块分析
Netty HTTP Tunnel
Netty 对 Socket 的实现
Netty 压缩与解压缩
Netty 对于 RPC 的支援
- WebSocket 实现与原理分析
- WebSocket 连接建立方式与生命周期分解
- WebSocket 服务端与客户端开发
- RPC 框架分析
- Google Protobuf 使用方式分析
Apache Thrift 使用方式与文件编写方式分析
Netty 大文件传送支持
可扩展的事件模型
Netty 统一通信 API
零拷贝在 Netty 中的实现与支持
TCP 粘包与拆包分析
NIO 模型在 Netty 中的实现
Netty 编解码开发技术
Netty 重要类与接口源代码剖析
Channel 分析
序列化讲解
框架的作用
对不友好的原生的底层再封装,使重点放在业务逻辑
支撑自动化的批量处理
参考
jvm内存与操作系统内存之间的关系 https://blog.csdn.net/Jbinbin/article/details/85004909
2.Java 内存模型和 JVM 内存结构真不是一回事 https://www.cnblogs.com/wskwbog/p/11349042.html
3.【os】操作系统的内存管理简介 https://www.bilibili.com/video/BV1u7411z7Sv?from=search&seid=5698852903576881295
4. 线程/协程/异步的编程模型 https://www.bilibili.com/video/BV1S4411Z7M2
5. 【并发】IO多路复用select/poll/epoll介绍 https://www.bilibili.com/video/BV1qJ411w7du
6. 【java】jvm内存模型全面解析 https://www.bilibili.com/video/BV12t411u726
7. 【java】垃圾收集器|g1收集器 https://www.bilibili.com/video/BV13J411g7A1
8. 深入浅出MappedByteBuffer https://blog.csdn.net/qq_41969879/article/details/81629469
9. JavaNIO-MappedByteBuffer https://www.jianshu.com/p/220ccfc91e95深入分析 Java 中的中文编码问题 https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/index.html
- java中的字符编码方式 https://www.cnblogs.com/liujinhong/p/5995946.html
- NIO之Buffer的clear()、rewind()、flip()方法的区别
- DMA 原理及基本概念
- 策略模式与命令模式区别 https://blog.csdn.net/jiafu1115/article/details/6980423、https://www.cnblogs.com/ChinaHook/p/7475777.html

若有收获,就点个赞吧
0 人点赞
