写于:2020.05.12
一. 研究背景
- 课题来源
- 大背景:国家全面推进电子政务信息系统一体化建设,天津网信办着力建设电子政务项目全流程管理信息系统;
- 问题:传统政务中,前置审批采用专家评议法,由于专家个人经验和偏向存在较强主观性,所以导致评审结果具有较大不一致性,竞标考量过于主观也导致政府信息化专项资金的投入缺乏科学管控;
- 应用目标:在【资金预算评价模块】中提供一个智能化的成本预算系统来辅助专家决策;
- 研究意义
- 应用:服务信息化系统建设,避免专家评审不一致、规范投入资金规模,打造公平竞标环境;
- 理论:软件成本的早期成本估算难题
- 软件产品具有类属差异性、逻辑性、智力性等显著特点;
- 软件系统开发过程具有不确定性和知识密集等特性;
- 研究对象:申报书 + 资金预算表 + 评审意见;
- 可行性分析
- 【 数据可得 】电子政务管理平台的数据具有透明性与共享性;
- 【 方法有依 】软件工程_软件成本估算研究;
- 【 方法边界 】专注电子政务应用软件,使软件成本估算具有较好的同类属性;
【 方法可解 】现阶段开发技术框架已非常成熟,可一定程度忽略技术细节,简化估算过程并使一些成本因子可控;
二. 研究方法
两个概念:
优:直接;缺:主观、无法量化;使用:一般与其它方法结合使用;
1.2 算法模型法:由成本因子组合构造的函数表达式
- 优:客观、高效、可重复,参数易于修改和优化; 缺:适应性差、抗干扰差、冷启动、参数不易量化、仅能预测单一成本值; 使用:适用于特定领域模型定制,一般用于软件开发后期的成本预测;
1.3 回归分析法:大规模数据驱动,模型多次迭代训练
- 优:计算简单,可选择模型较多,可用于软件开发各阶段;缺:依赖大样本空间,易受极端值影响,可解释性差; 使用:可用于软件开发的不同阶段,对数据集的质量和数量要求较高;
1.4 类比估算法:基于历史相似案例进行综合评估;
- 优:专家和算法模型的有效替代,易于理解,可靠性强,不限制样本规模,适用于软件开发早期成本估算;
缺:领域局限,要求类比的软件具有同类属性;使用:可用于软件开发的不同阶段,适用于小数据集;
2. 方法选择
2.1 数据限制
- 可获得的有效申报书样本量较少,数据集特性:包含软件开发早期的成本特性信息(文本、不完整、不规范、不准确性);
2.2 类比估算的两种方法
- 阈值法
- 基于范式或实例库(CBR):将成本特征抽象为实例,实例检索过程计算相似度,依阈值进行筛选;
- 基于相似工程:将成本特征定义为相似元,在加权条件下,综合各个相似元的相关系数来计算软件系统相似度,进而依阈值筛选;
聚类法:聚类法将成本特征抽象为实例,通过对实例对象聚类,实现相似样本筛选,进而进行成本预测,其中在构造成本聚类模型的过程中可内化软件开发早期信息不完整且模糊的特性,使结果更具可信度;
三. 研究过程
完整的方法过程如下图所示:
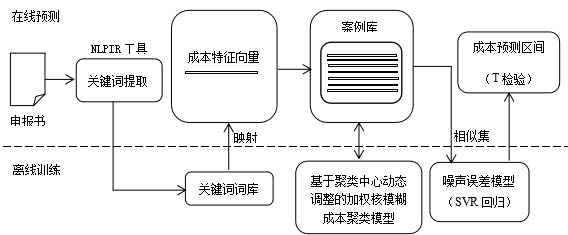
1. 数据预处理
1.1 理论研究
- 研究难点:
- 特征局限:大多软件成本预测的研究依托公有数据集,这些数据集一般为已完成的软件项目,而申报书的文本内容主要描述软件开发早期的功能需求,传统成本预测方法中一些特征因子只能在软件开发后期获得【规模、复杂度】;
- 传统成本特征度量方法不适用于申报书:功能点法(IFPUG) + 需求复杂度量(模糊综合评价法)
- 映射关系:确定一个有效的映射函数,将申报书中的文本功能特征转化为成本特征向量;
- 技术及创新点:
- 文本关键词提取及去重技术
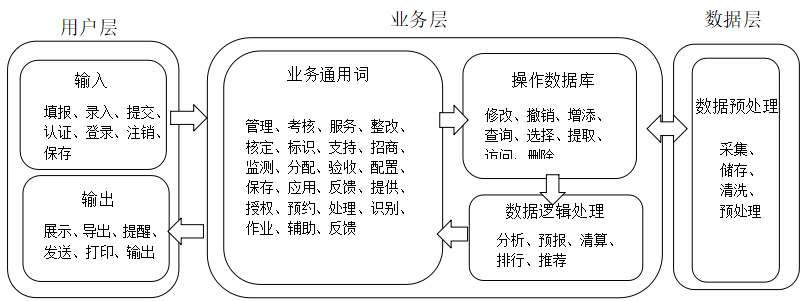
- 多域特征映射:通过构建功能结构模型来实现从设计域到成本域的软件成本特征映射
- 优势:打破了传统的数值度量法,将复杂性隐藏于层次结构之间,并以向量形式表示软件规模;
1.2 实验
- 基于中科院的 NLPIR 工具包进行文本关键词提取,进一步构建正交的功能关键词词库;
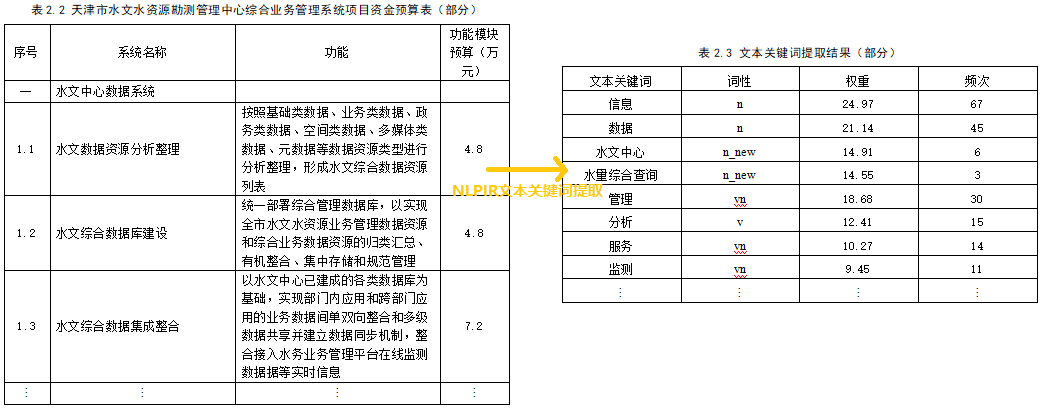
- 将功能关键词进行软件层次架构划分,构建功能结构模型,最终可将申报书的功能文本转化为53维的成本特征向量;
-
2. 初步预测
2.1 理论研究
方法选择:依据属性的特性选择聚类方法
- 软件成本特征本身具有高维属性,而从申报书中提取并映射的成本特征具有不完整性、模糊性、低维性、不同属性对预测准确度的影响不同,综合以上选择加权核模糊C均值法来构建相似成本聚类模型;
- 问题:模糊聚类的目标函数为典型的非凸函数,不可避免地存在多个局部极值点,从而陷入局部优化而得不到最优模糊划分,有必要在迭代更新聚类中心的过程中应采用有效的全局寻优算法作一定调整;
- 创新点:利用和声搜索算法从全局角度调整加权核模糊聚类的聚类中心
- 为引入模糊成本聚类模型,提出三个适应性的改进点(公式详见论文 式3.36-3.39):
- 一是动态构建和声库,通过迭代完成和声库的扩充,减少初始和声库的计算量及空间多样扰动问题;
- 二是并行解空间调整和声库取值概率HMCR和微调概率PAR,解空间扩大的同时提高局部搜索能力,如
- 三是在和声更新机制中引入遗传交叉变异思想和混沌理论来调整学习方向。
- 优势:不会改变原模糊聚类算法的目标函数,且将混沌理论和遗传交叉变异思想引入和声的更新过程,与加权核模糊聚类模型具有的天然不确定性相适应;
- 为引入模糊成本聚类模型,提出三个适应性的改进点(公式详见论文 式3.36-3.39):
2.2 对比实验
- 数据及预处理
- 3 个公有数据集:COCOMO81、Desharnais、RepoReapers,筛选出属于软件产品本身的且可在软件开发早期获取的属性序列;
- 结果
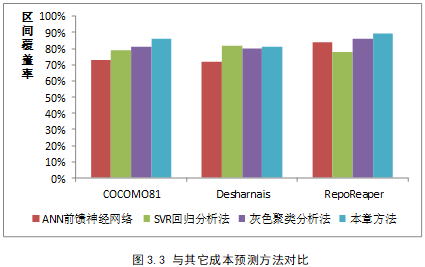
- 验证所提出的改进和声搜索算法能有效作用于加权核模糊C均值模型,具有可行性;
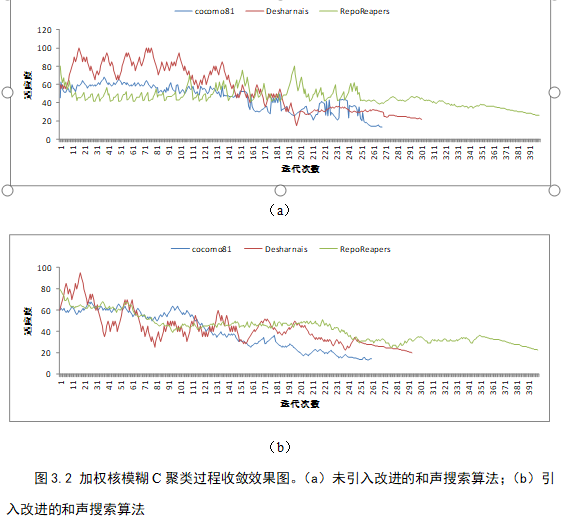
- 对比其它成本预测方法,验证本文方法在预测准确度上具有有效性
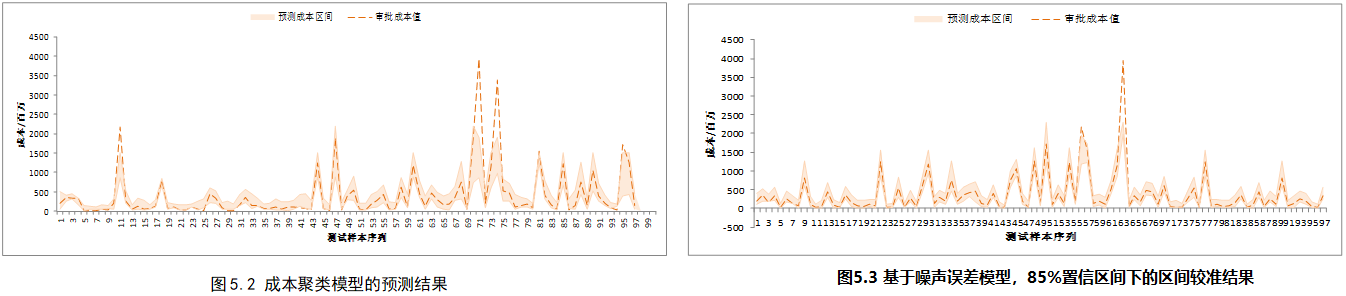
3. 结果较准
3.1 理论研究
- 方法选择:
- 比例系数法:针对上下限分别设定两个比例系数,分别建立回归模型对两个比例系数进行收敛;
- 误差模型法:基于多模型预测结果,综合系统和噪声误差来构建噪声方差模型,并利用系统误差的概率分布特性以获取不同置信区间下的区间预测结果;
- 传统方法中,会利用 Bootstrap 这种自动化的重抽样手段构建多个模型来获取多个拟合结果,以此分析多个预测结果的系统和噪声误差,并在此基础上训练一个回归模型对噪声方差进行预测;
- 创新点
- 构建成本区间误差模型:将间接区间预测方法结合应用于成本区间较准,模糊聚类模型的输出本身就是多个相似的预测结果值,可以依据此特性直接使用误差模型法,相比传统方法会极大地降低计算量;
3.2 对比实验
- 数据及预处理
- 数据来源为 COCOMO81、Desharnais、RepoReapers 三个数据集通过模糊聚类模型所预测的相似成本序列,
- 结果
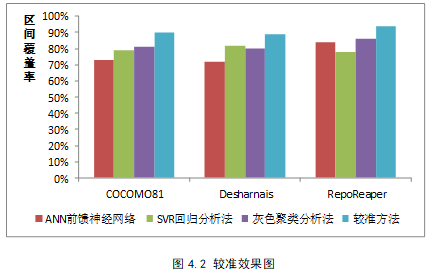
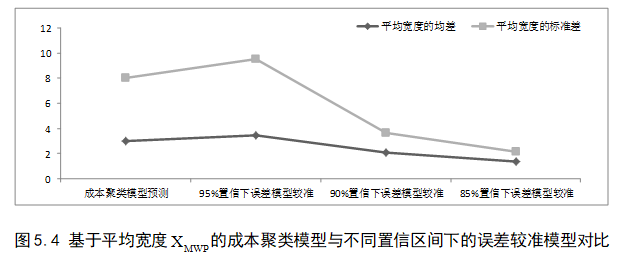
- 对比模糊成本聚类模型初步估计的成本区间,验证噪声误差模型能够对初步预测结果进行较准,具有可行性
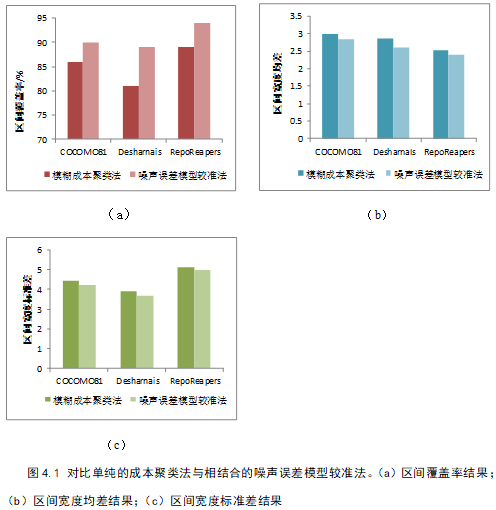
- 对比模糊成本聚类模型初步估计的成本区间,验证噪声误差模型能够对初步预测结果进行较准,具有可行性
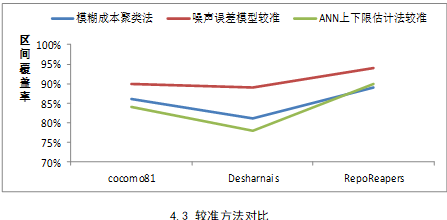
- 对比其它区间较准方法,验证本章方法在预测准确度上具有效性
四. 研究成果与展望
- 方法有效性
2. 方法准确性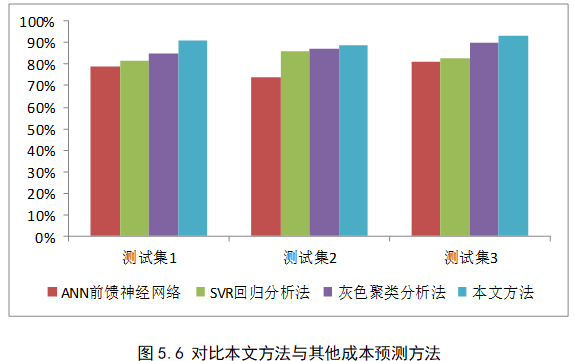
3. 工作总结
- 本文主要有三个创新点:
- 提出功能结构模型,实现从申报书提取的文本功能信息到软件成本特征向量的映射;
- 构建适应于软件开发早期的成本聚类模型,且引入遗传交叉变异和混沌思想来改进和声搜索算法以从全局角度优化聚类结果;
- 在模糊聚类基础上,进一步利用噪声误差模型进行成本区间的再较准;
- 展望

若有收获,就点个赞吧
0 人点赞
