rabbitmq使用场景:
1、异步:
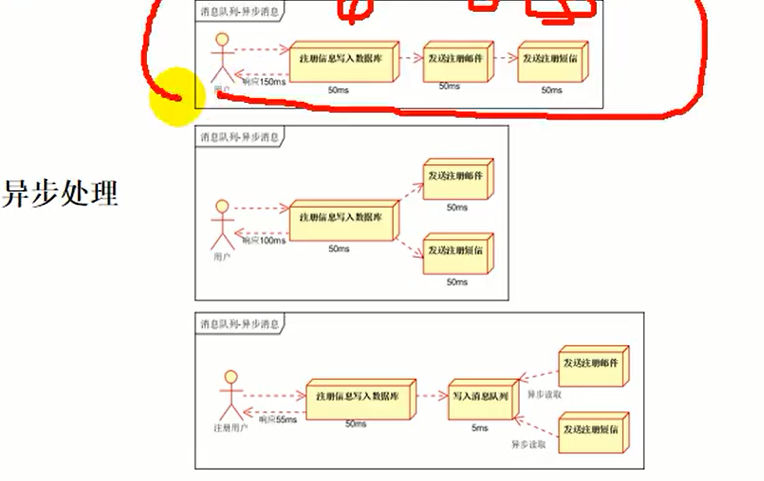
普通业务以用户注册为列:用户通过浏览器提交了账号和密码,注册了信息,分为三步:1、将注册信息写入数据库,花费50ms;2、发送邮件告诉用户发送成功,花费50ms;给用户发送通知短信,提示注册成功,花费50ms.
1步骤->2步骤->3步骤,是一种同步模式,用户注册完成并响应,需要花费150ms。但是发现没有必要,发送短信和发送邮件是可以整一个异步模式:1、用户把注册信息写入数据库,花费50ms;通过线程去分别执行这两个异步操作(一个发送短信和一个发送邮件),现在只需要等最长时间的完成就可以了,假设一个是50ms,一个是60ms,
则1步骤->(2步骤和3步骤)总共花费110ms时间,缩短了用户处理时间.但是在后台异步发送短信以及发送邮件的时候,让他们慢慢发,成功不成功也不需要知道,只要做了这件事就可以了。
第三种,注册信息写入数据库成功,然后将注册成功的消息写入消息队列,保存在消息服务器中,然后直接给我们的用户返回。给消息中间件写入只需要极短的耗时,数据库要插入数据,要持久化耗时比较久,可能需要50ms,写入消息队列,类似于写入到redis中,假设花费了5ms,超级快。用户收到这个响应需要55ms就收到了,但是用户能不能收到短信和邮件呢,也是可以的。消息存到消息队列里,别的服务就可以从队列里面拿到消息,拿到一号用户注册成功了,在后台该发短信发短信,该去发邮件发邮件,我们不关心她什么时候发邮件,发短信,只要他干了这个事情就可以了,但是用户会立即返回数据,响应成功
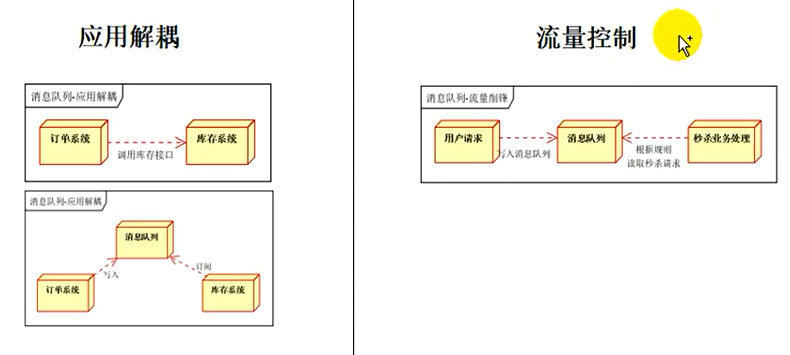
2、应用解耦:
以下订单为例,订单支付完成以后,库存要进行出库操作。以前呢下订单操作完成以后要调用库存系统减库存,下订单方法,api传了三个参数,调库存传了五个参数。下订单完成后,调用减库存,如果库存系统不升级,则api一直不变都是五个参数,但是库存系统需要升级,减库存api发生变化,订单系统就要修改源代码,重新部署,会非常麻烦;所以引入消息队列,订单系统下号订单,给消息队列里面写入消息,哪个用户下了哪个订单购买了哪个商品。我们不关心库存系统的接口是什么,只需要把订单成功的消息写入队列即可。库存系统会实时的订阅消息队列,并处理消息。只要有消息,我们的库存系统就会收到我们刚才写的消息,然后分析这个消息都有哪些内容:**哪个用户下了哪个订单购买了哪个商品,然后操作减库存即可。下完订单以后无需关心库存系统要调用什么接口,只需要写消息就可以了,所以就实现了应用解耦**,以后无论什么系统,想要知道订单成功以后要做什么,都只需要订阅消息队列里面订单成功的消息,不关心别的系统的接口是如何实现的,因为我们无需调用。
3、流量控制
特别是对于一些秒杀业务来说,瞬时的流量会非常大,比如百万个请求进来都要秒杀这个商品。这个商品去真正去执行业务,就算前端服务器可以接受百万个请求要执行业务代码,秒杀完,要下订单,执行一整套流程,后台会非常慢,会一直阻塞,最终会导致我们的资源耗尽,机器宕机,此时我们可以怎么做呢?
将大并发的用户请求全部进来,以后别的不说,先存储到消息队列里面,就不用管这个请求该怎么做了,返回秒杀成功了,或者其他。后台的下订单,减库存,等这些业务处理,不着急立即调用。只要存储到消息队列里面,这些业务去订阅消息队列里面进来的这些秒杀请求,挨个进行处理,下订单,减库存等,即使我们的后台只能每秒处理一个,100万个请求我们花费100万秒就可以了,所以可以达到流量控制,我们把所有的流量存储到队列中,后台根据他们的能力进行消费和处理,**永远都不会导致我们的机器资源耗尽,宕机。称为流量削峰。**
rabbitmq的工作模式
1、简单队列模式:只包含一个生产者以及一个消费者
2、工作队列模式:多个消费者绑定到同一个队列上,一条消息只能被一个消费者进行消费。
3、发布-订阅模式:生产者将消息发送到交换器,然后交换器绑定到多个队列,监听该队列的所有消费者消费消息。
4、路由模式:生产者将消息发送到direct交换器,它会把消息路由到那些binding key与routing key完全匹配的Queue中,这样就能实现消费者有选择性地去消费消息。
5、主题(Topic)模式:类似于正则表达式匹配的一种模式。主要使用#、*进行匹配
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
ActiveMQ:是老牌的消息中间件,使用较多的是一些传统企业,用ActiveMQ做异步调用和系统解耦。没法确认ActiveMQ可以支撑互联网公司的高并发、高负载以及高吞吐的复杂场景。
RabbitMQ:好处在于可以支撑高并发、高吞吐、性能很高,有非常完善便捷的后台管理界面,还支持集群化、高可用部署架构、消息高可靠支持;国内各大互联网公司落地RabbitMQ比较多;开源社区很活跃,但是有一点缺陷,就是他自身是基于erlang语言开发的,较为难以分析源码,较难进行深层次的源码定制和改造。
RocketMQ:阿里开源的,经过阿里的生产环境的超高并发、高吞吐的考验,性能卓越,同时还支持分布式事务等特殊场景。基于Java语言开发的,适合深入阅读源码,有需要可以站在源码层面解决线上生产问题,包括源码的二次开发和改造。
Kafka:优势在于专为超高吞吐量的实时日志采集、实时数据同步、实时数据计算等场景来设计。因此Kafka在大数据领域中配合实时计算技术(比如Flink)使用的较多。但是在传统的MQ中间件使用场景中较少采用。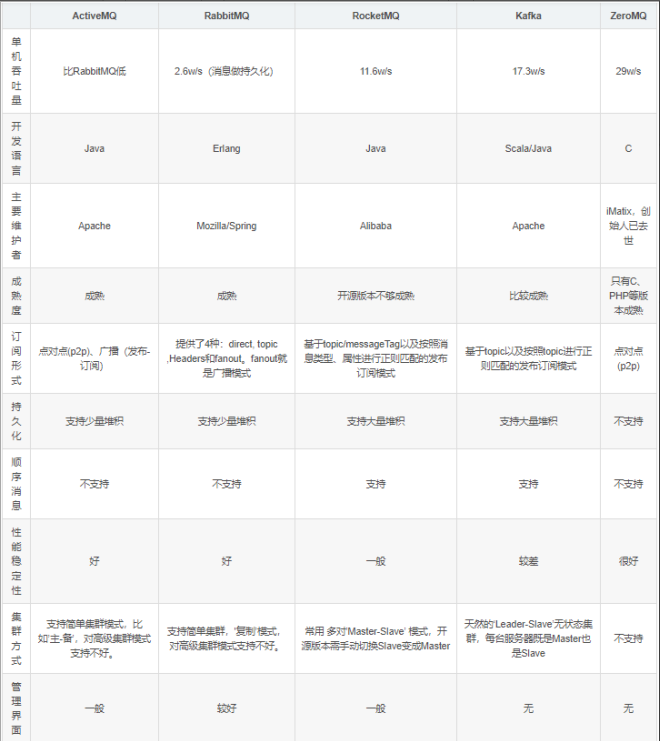
对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝对不会黄。
如何保证RabbitMQ消息的可靠传输?
消息不可靠的情况可能是消息丢失
丢失又分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息;
生产者丢失消息
confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;<br />如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
消息队列丢数据
消息持久化。这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。<br />如何持久化?<br />1. 将queue的持久化标识durable设置为true,则代表是一个持久的队列<br />2. 发送消息的时候将deliveryMode=2
消费者丢失消息
消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可!
如何保证高可用的?RabbitMQ 的集群
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式
普通集群模式
在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
镜像集群模式
这种模式,才是所谓的 RabbitMQ 的高可用模式。。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。好处是,RabbitMQ 节点挂了以后其他节点还有数据,坏处是性能开销很大
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
消息积压处理办法:临时紧急扩容:这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
MQ中消息失效:假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
设计MQ思路
mq 得支持可伸缩性,快速扩容,就可以增加吞吐量和容量。设计个分布式的系统,参照一下 kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了。
mq 的数据要不要落地磁盘,落磁盘才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
mq 的可用性,kafka 的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务。
能不能支持数据 0 丢失啊?可以的,参考我们之前说的那个 kafka 数据零丢失方案。

DOCKER 安装RabbitMQ
docker run -d —name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
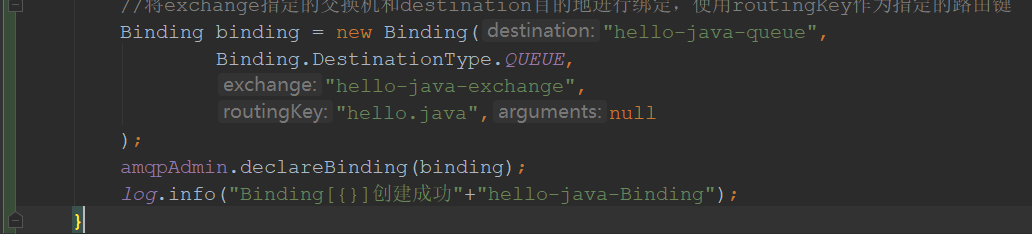
1)创建交换器、队列,将交换器和队列进行绑定
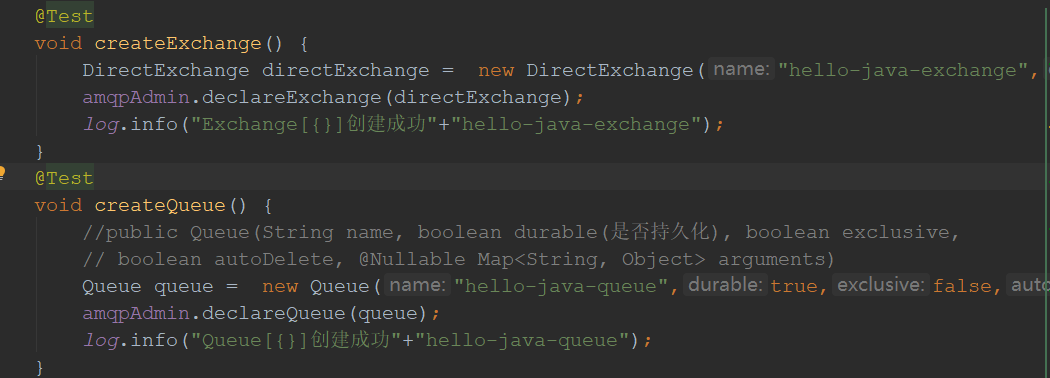
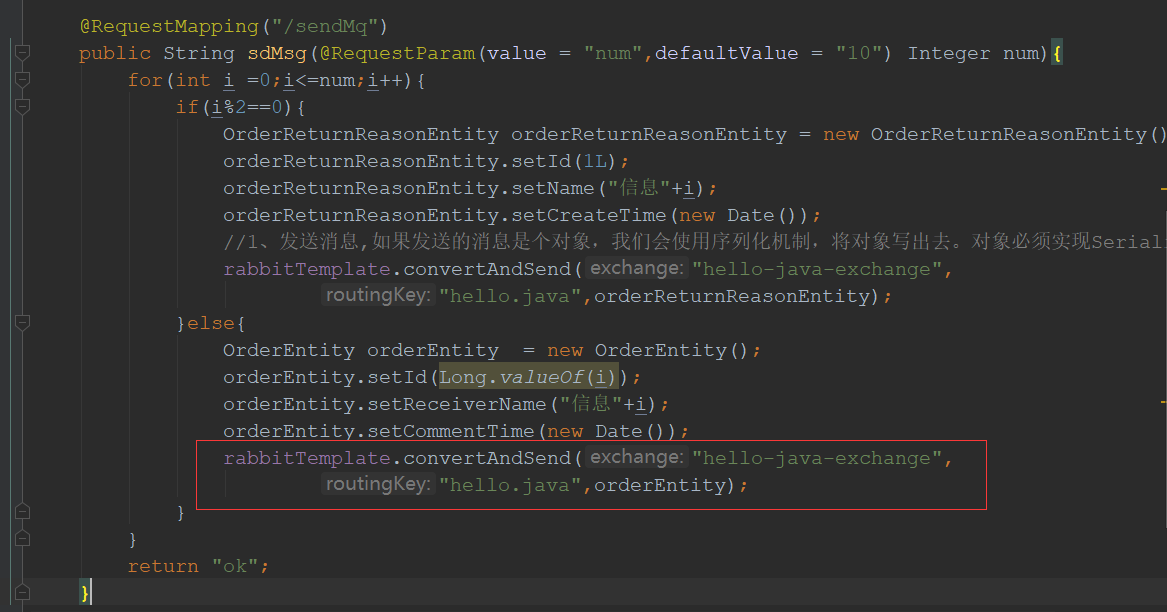
2)rabbitmq发送消息
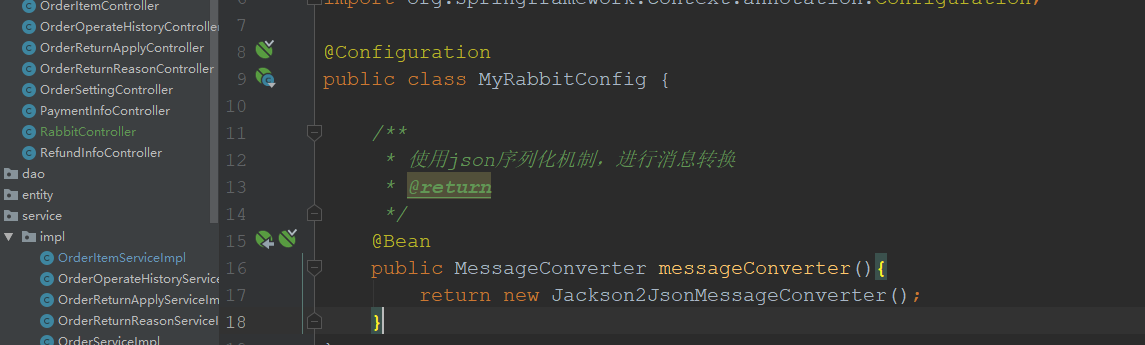
3)rabbitmq接收消息
1.pom.xml添加rabbitmq的相关maven依赖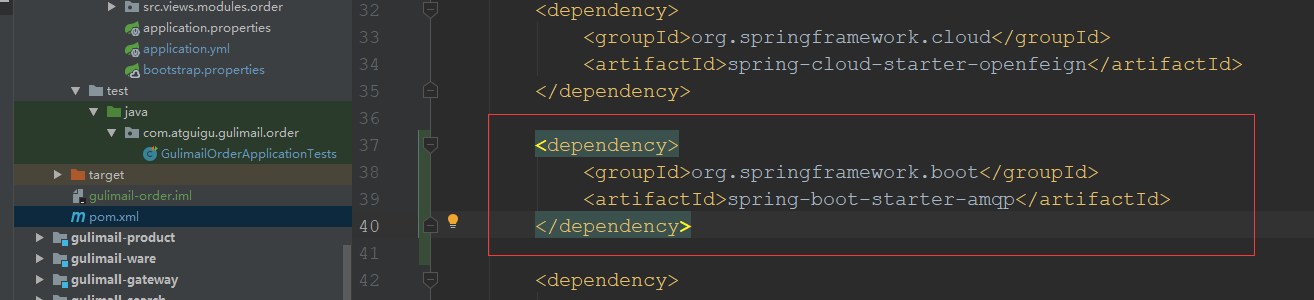
2.给配置文件中添加spring.arbbitmq的信息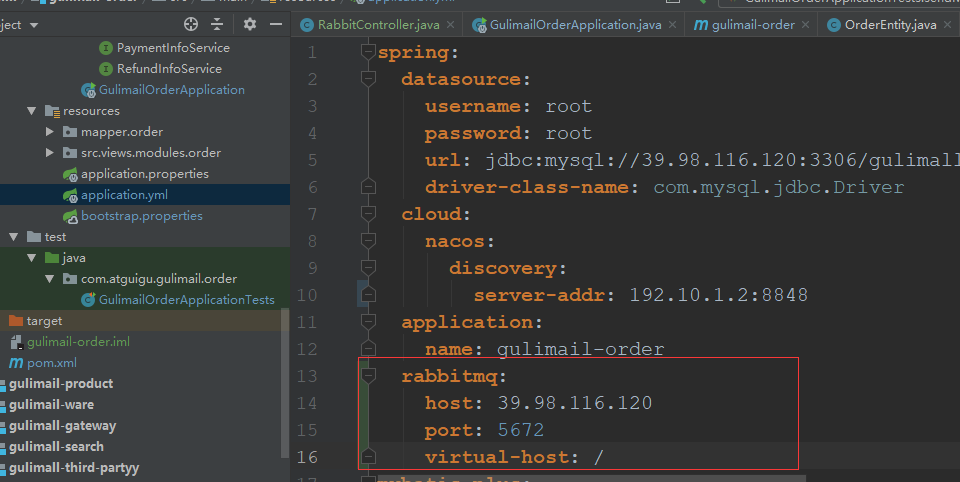
3.启动类上加上注解@EnableRabbit:开启功能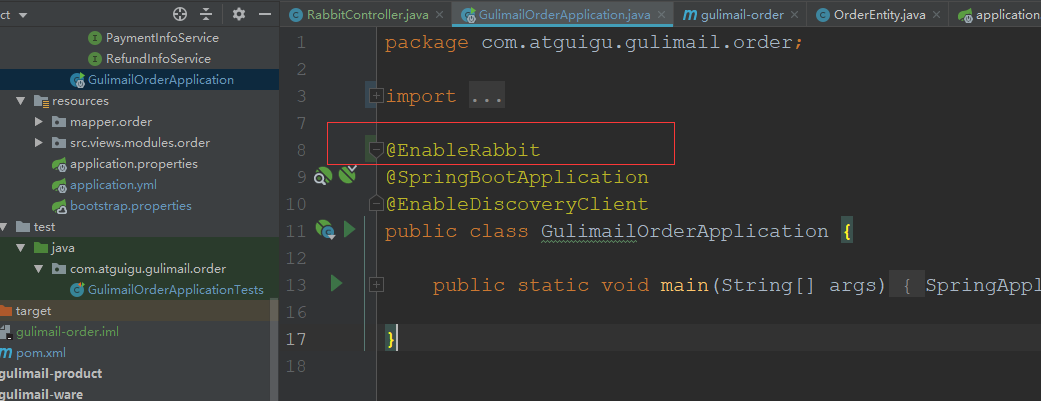
4.类+方法上都可以(监听哪些队列)
@RabbitListener(queues ={“hello-java-queue”} )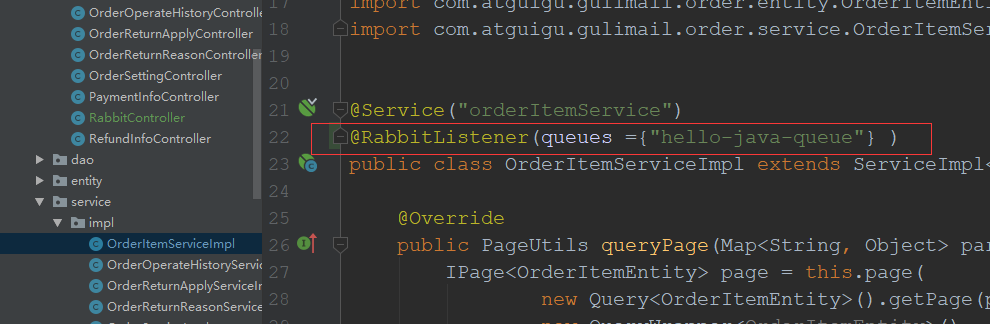
5.@RabbitHandler标在方法上,重载区分不同的信息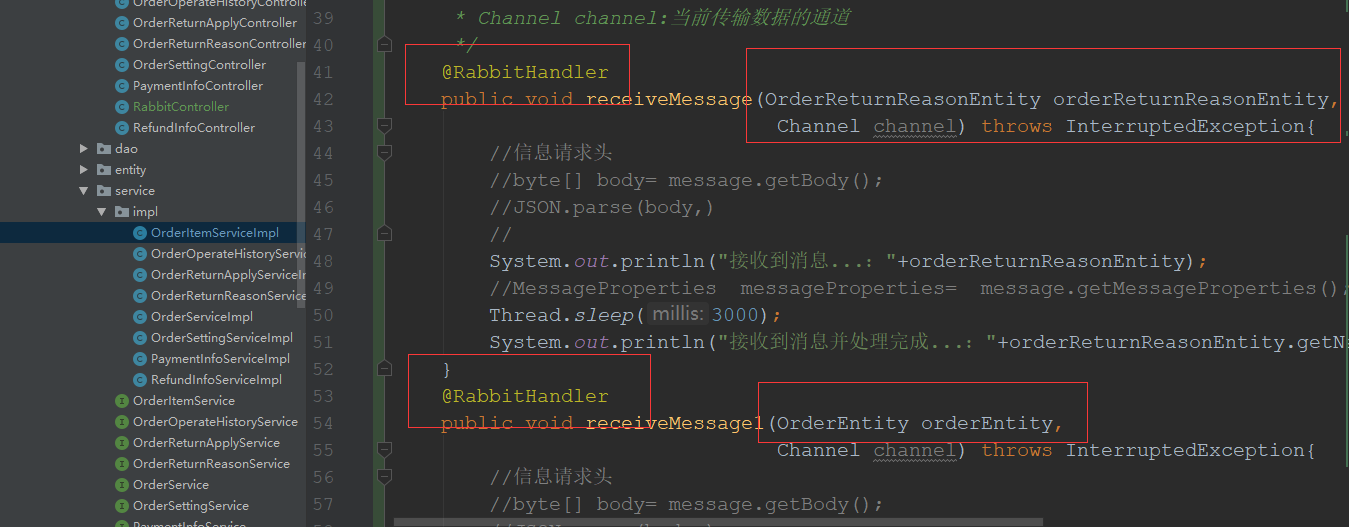


4)可靠投递


步骤:

代码如下:
消息发送到服务器端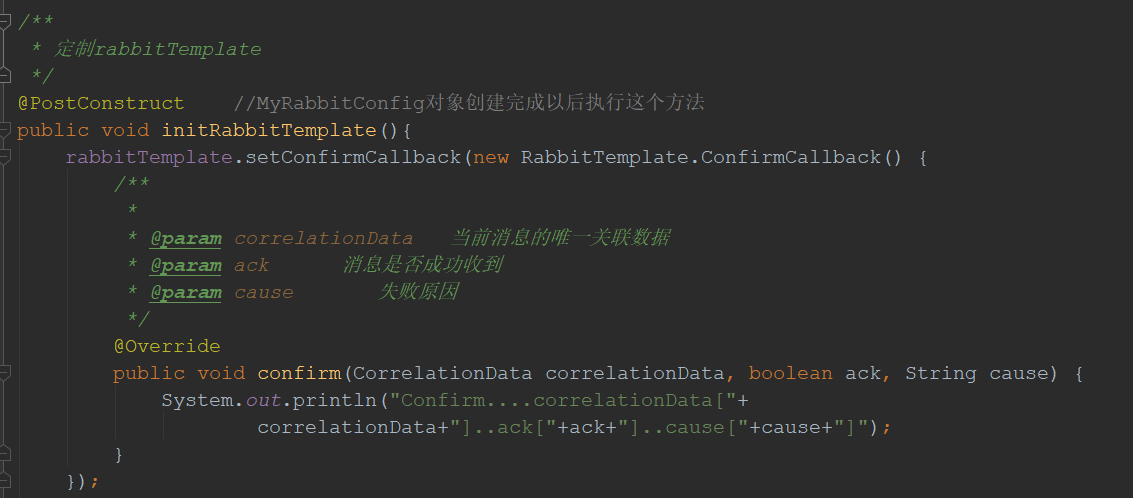
消息从交换机到队列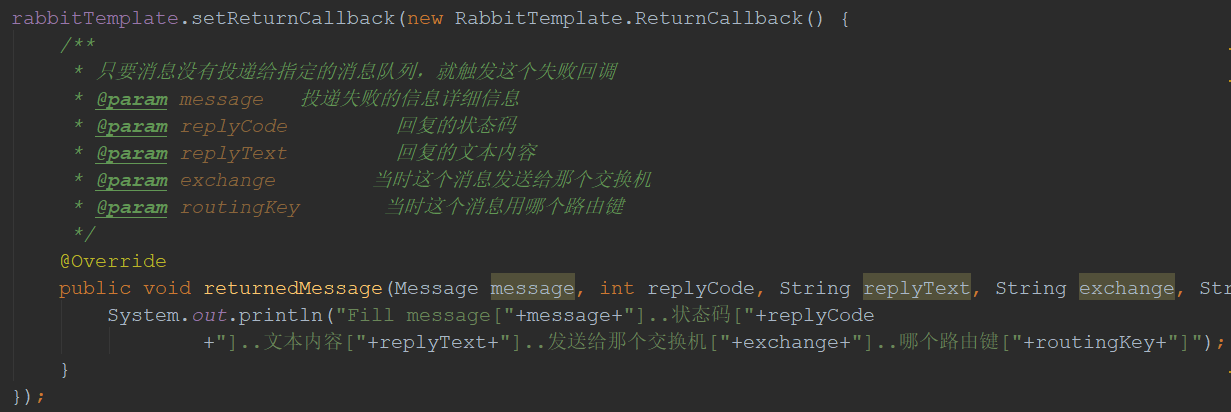
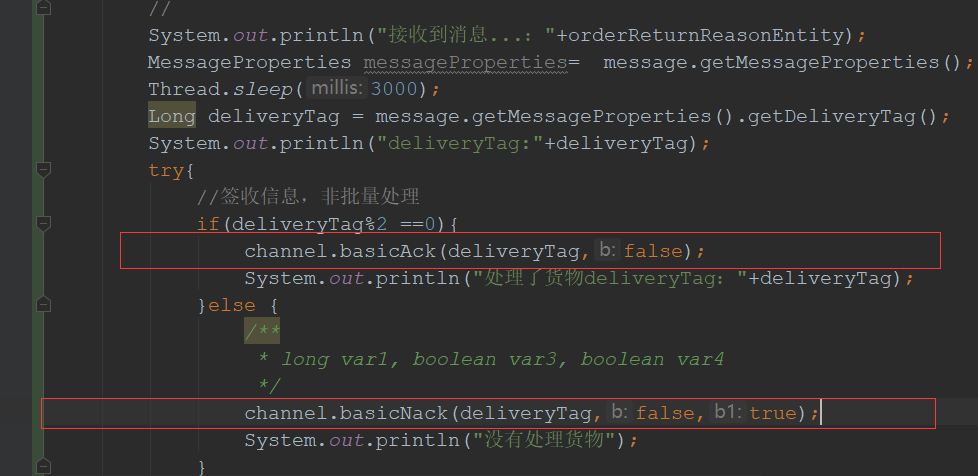
消费端确认机制-ack机制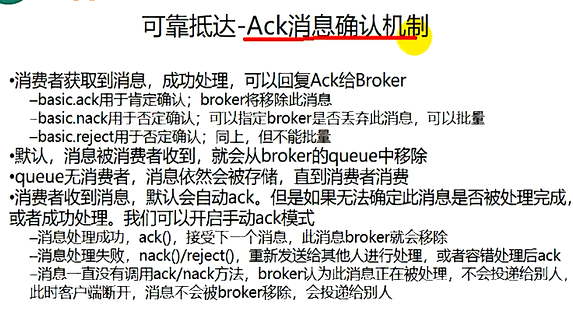



若有收获,就点个赞吧
0 人点赞
