每秒20条数据,每日数据量200万左右,2个月达到一亿条,年数据量大约在7亿数据量。
从上表中发现,目前订单数据量已达上亿,并且每日以百万级速度增长,之后还可能是千万级。
为了使系统抗住千万级数据量的压力,各种SQL优化都已经做完,最终确定下来的方式是将订单表拆分,再进行分布存储,这也就是本章我们要讨论的内容——分库分表。
二、拆分存储的技术选型
关于拆分存储常用的技术解决方案,市面上目前主要分为4种:MySQL的分区技术、NoSql、NewSQL、基于MySQL的分库分表。
4、基于MySQL的分库分表
什么是分库分表?分表是将一份大的表数据拆分存放至多个结构一样的拆分表;分库就是将一个大的数据库拆分成多个结构一样的小库。
主要是有一个重要考量:分库分表对于第三方依赖较少,业务逻辑灵活可控,它本身并不需要非常复杂的底层处理,也不需要重新做数据库,只是根据不同的逻辑使用不同的SQL语句和数据源而已。
如果使用分库分表方式,存在三个技术通用需求需要实现。
1、SQL组合:因为我们关联的表名是动态的,所以我们需要根据逻辑组装动态的SQL。
2、数据库路由:因为数据库名也是动态的,所以我们需要根据不同的逻辑使用不同的数据库。
3、执行结果合并:有些需求需要通过多个分库执行,再合并归集使用。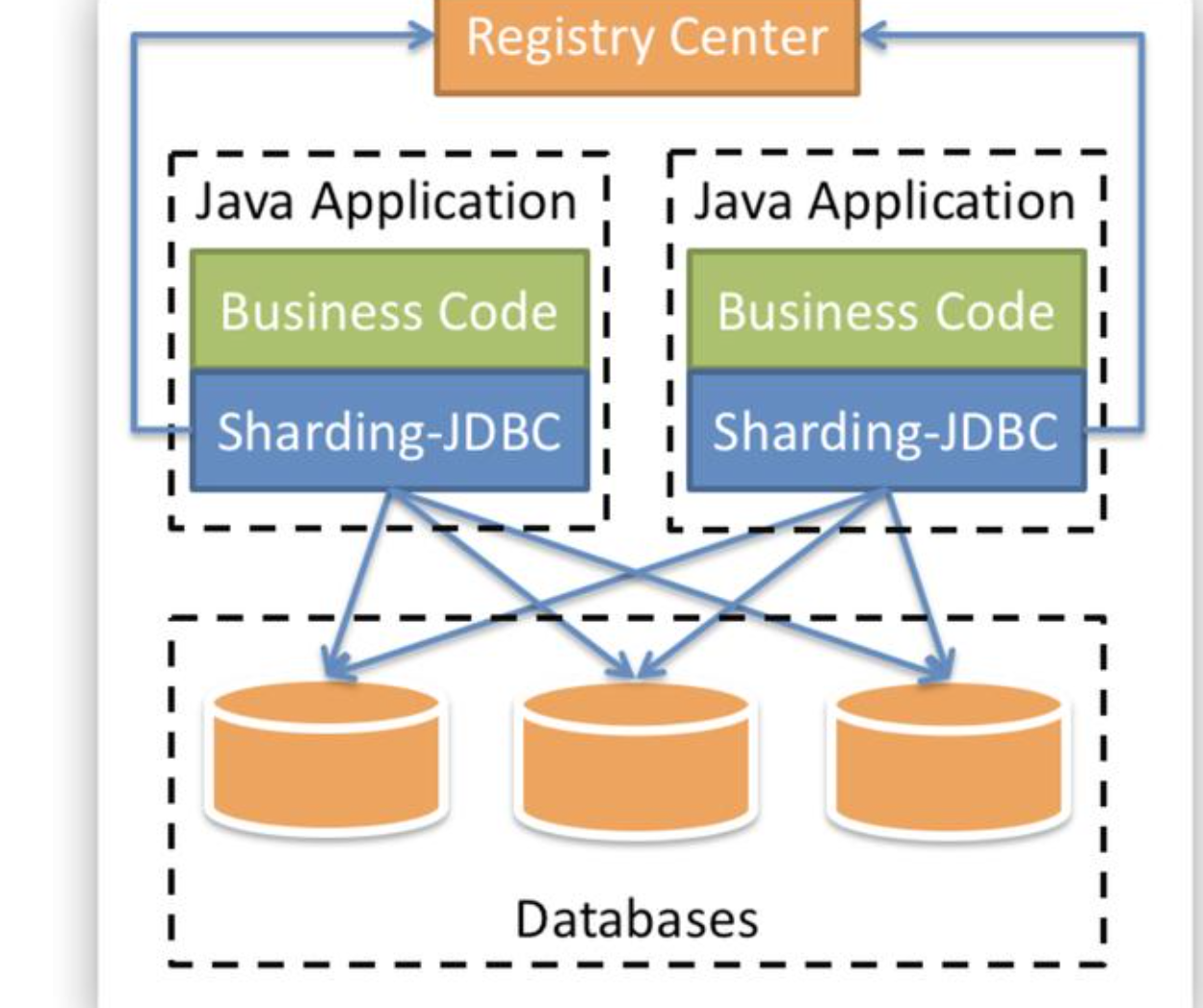
以上这种设计模式,把分库分表相关逻辑存放在客户端,一版客户端的应用会引用一个jar,然后再jar中处理SQL组合、数据库路由、执行结果合并等相关功能。
三、分库分表实现思路
此时,如果我们使用user_id作为订单分片字段,就能保证每次用户查询数据时(第一个需求),在一个分库的一个分表里即可获取数据。
这里需要特殊说明下,选择字段作为分片键时,我们一般要考虑三个因素:数据尽量均匀分布在不同的库或表、跨库查询尽可能少、这个字段值会不会变(这点尤为重要)。
2、分片的策略是什么?
分片策略分为根据范围分片、根据hash值分片,根据hash值及范围混合分片这三种。
- 根据范围分片:比如用户id是自增型数字,我们把用户id按照每100万份分为一个库,每10万份分为一个表的形式进行分片,如下表所示:
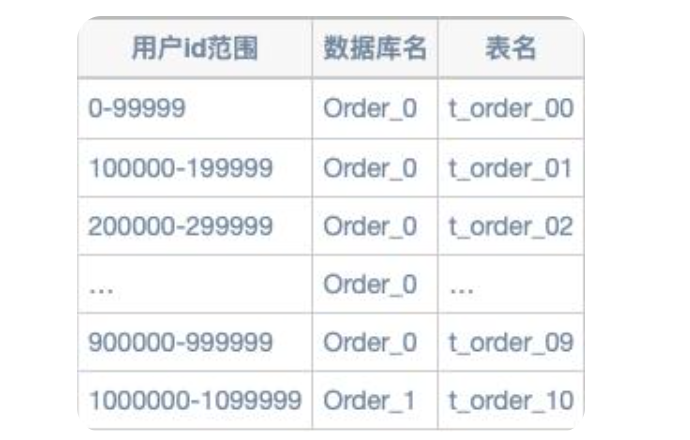
特殊说明:这里我们只说分表,至于分库则是把分表分组存放在一个库即可,就不另行说明了。
- 根据hash值分片:指的是根据用户id的hash值mod一个特定的数进行分片。(避免方便后续扩展,一版是2的几次方)
- 根据hash值及范围混合分片:先按照范围分片,再根据hash值取模分片。比如:表名=order#user_id%10##hash(user_id)%8,即被分成了10*8=80个表。为了方便理解,我们画个图来说明,如图所示:
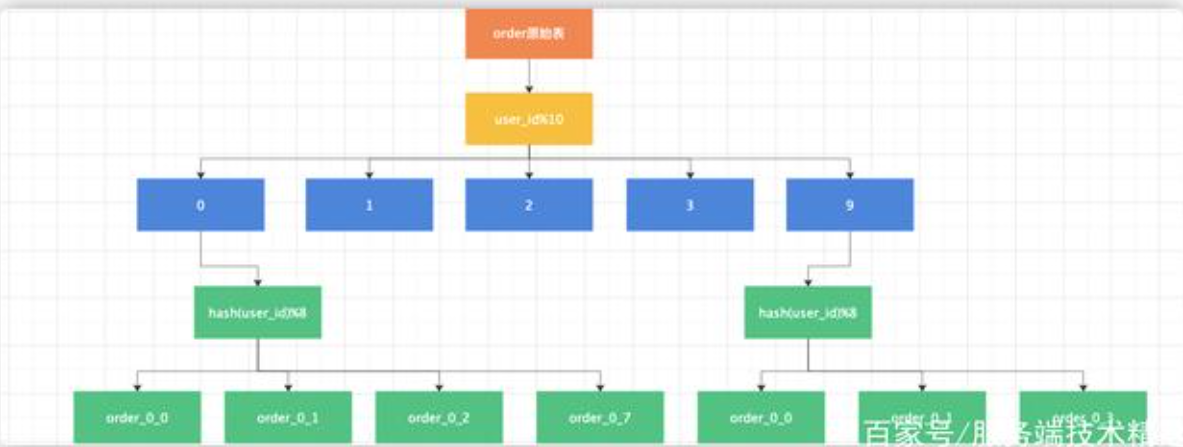

若有收获,就点个赞吧
0 人点赞
