1. 硬件的升级:
加内存,cpu(i5—->i7)等等这些升级,其实对于性能的提高作用并不是很大
2. 系统的配置:
修改服务器的配置,使得服务器的性能更加偏重,使得服务器的性能好点
1.通过对bufferpool知识的学习,我们知道,数据库的数据,一部分是在内存中,一部分是在磁盘上。那么我们 也知道数据放在内存中进行交互的话,性能更加的好。(bufferpool里面放尽量多的数据)
方案:调大bufferpool的空间大小,使得bufferpool放下足够多的数据:innodbbuffer_pool_size
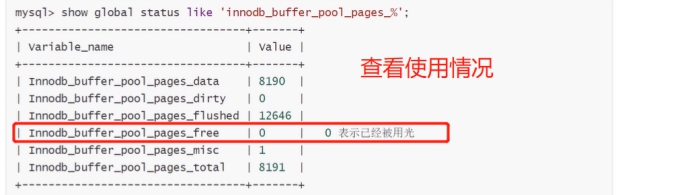
2.数据预热:数据库重启的时候将磁盘的数据加载到内存中
3.降低磁盘写入次数:
3、表机构的设计
2.在表中设计冗余的字段(冗余的字段尽量是不会改的数据):这样就省的联表查询
3.拆表:将字段非常多的表拆开,要不然扫描的时候非常耗时。
4.主键的优化:主键的类型最好是int类型(存储空间小,方便排序):
问题:在分布式环境下,怎么保证表的主键的唯一性:雪花算法:64bit的引入时间戳和自增id的算法:(推荐使用雪花算法)
问题:redis的全局id能解决并发问题,但是在集群模式下会造成数据不一致的问题。
UUID保证了唯一性,但是没有顺序可言
5.字段设计:
1.字段的宽度设计的小一些
2.字段尽量不要设置成not null
3.能用数字的就用数字类型
4. Sql优化以及索引
- 避免in里面的值过多,因为mysql对in做了优化,会将in里面的值排序并放入到数组里面去。所以值过多情况下不要使用in
2. 避免select * 这种写法(消耗带宽,cpu,io,内存)
3. limit可以阻止全表扫描(分页的时候可以使用)
4. 排序字段加索引
5. 如果限制条件中其他字段没有索引,尽量少用or ,or两边的字段中,如果有一个不是索引字段,会造成该查询不走索引的情况。
6.尽量用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序, 增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
7.不使用ORDER BY RAND()
ORDER BY RAND() 不走索引
6.union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
7.区分in和exists、not in和not exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。如何高效的写出一个替代not exists的SQL语句?
7.分段查询 :一些用户选择页面中,可能一些用户选择的范围过大,造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段进行查询,循环遍历,将结果合并处理进行展示。
不建议使用%前缀模糊查询
例如LIKE“%name”或者LIKE“%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE “name%”。
那么如何解决这个问题呢,答案:使用全文索引或ES全文检索
8.避免在where子句中对字段进行表达式操作
9.避免隐式类型转换
where子句中出现column字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定where中的参数类型。 where age=’18’
10.对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段id、name、school,可以直接用id字段,也可以id、name这样的顺序,但是name;school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询字段放在最前面。
11.必要时可以使用force index来强制查询走某个索引
有的时候MySQL优化器采取它认为合适的索引来检索SQL语句,但是可能它所采用的




若有收获,就点个赞吧
0 人点赞

{kind=link}