redis<br />1. 为什么会出现redis:以前存储文件是放在硬盘上,寻址时间是ms(毫秒),当文件变大,进行全量扫描的时间变长了,寻址时间变长,不足以满足人们的需求,所以发明了redis(基于内存操做,寻址时间是ns(纳秒)),也就是磁盘的10w倍<br /> <br />2. 使用数据库:相比存放在磁盘上,还是比较快的,那么为什么就快了呢:分治+索引<br /> <br />3. 当数据库中的表数据量很大的时候,写是肯定会变慢的,因为索引结构需要调整,但是读不一定慢:当只有一个连接连接到数据库,客户端只发来一个简单的查询,且命中索引,那么查询还是毫秒级别的。如果是高并发的场景下,那么就变慢了:每个人都读取数据,每个人的数据都是独立的,那么就需要从磁盘中将数据返回放到内存中,这里会涉及到带宽吞吐量的问题,不能全部一次性读取到内存中,所以就会延迟,从而变慢<br /> <br />注意:以上几点说的都是如何解决全量扫描io问题,解决这个就会变快。<br /> <br />提问:1.redis是什么?<br />基于内存操做的worker线程是单线程的nosql数据库<br /> <br />2.redis的工作流程:这个是5.x之前的版本<br />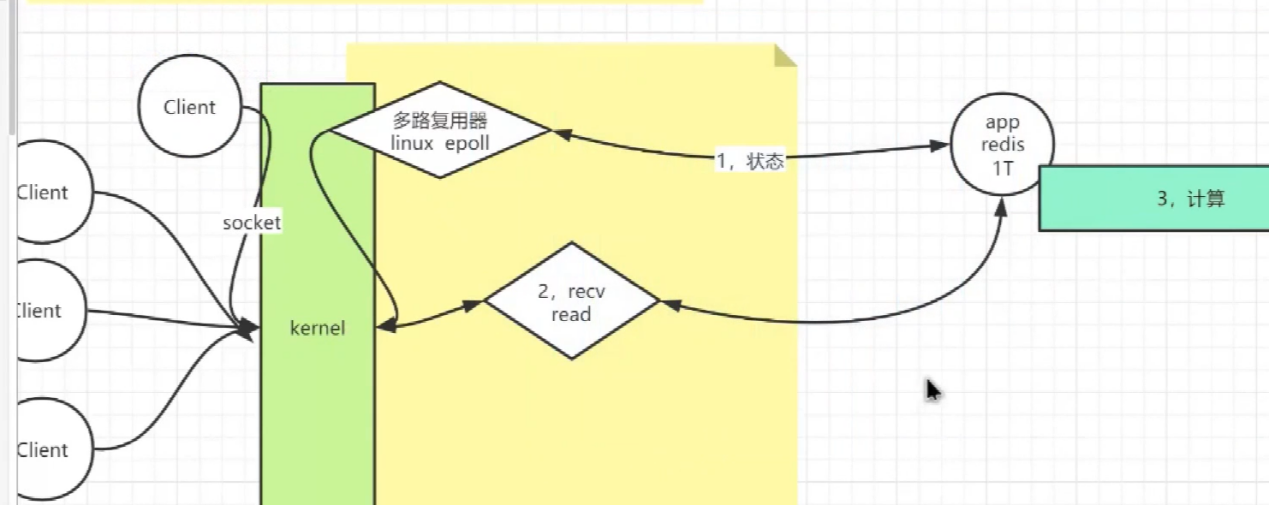<br /> <br />4. redis和memcache:都是key-value格式的<br />1. redis是nosql的(key-value),不存在聚合的概念,只要关注自身就行了,而且是单线程的,也就是操做是原子的。<br />2. Redis6.x存在多线程的概念:工作线程负责计算,io线程负责读和写(数据存在堆中)<br />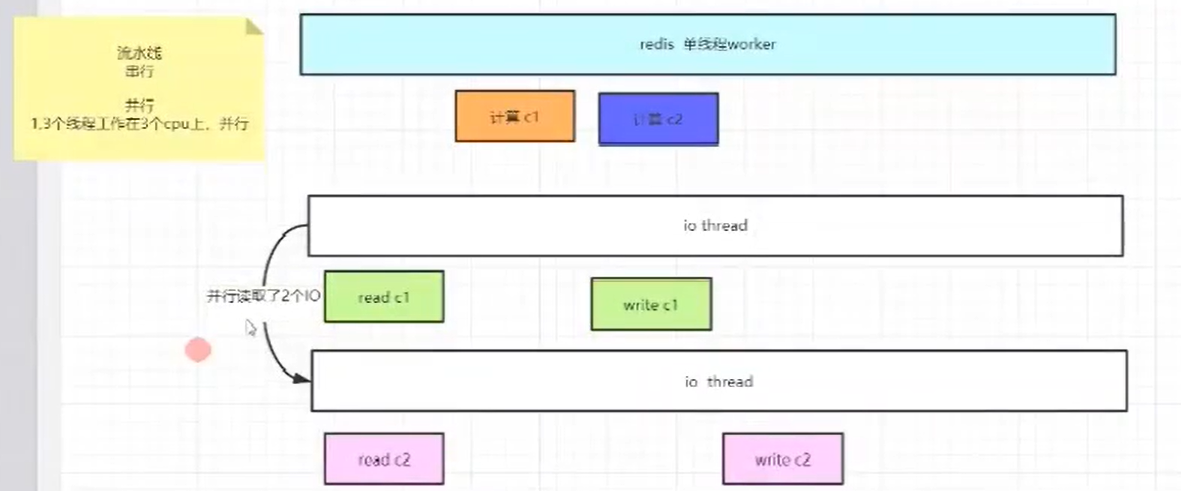<br />3. redis支持5种数据类型,并且每种类型都有自己的api,而memcache只有一种数据类型<br />4. Memcache在读取的时候,需要全部读取,自行在客户端实现自己的序列化,而redis直接在服务器上完成并直接返回自己想要的数据<br />5. Redis的性能来自于nio和epoll,多路复用<br />6. Redis是高并发但串行执行的<br />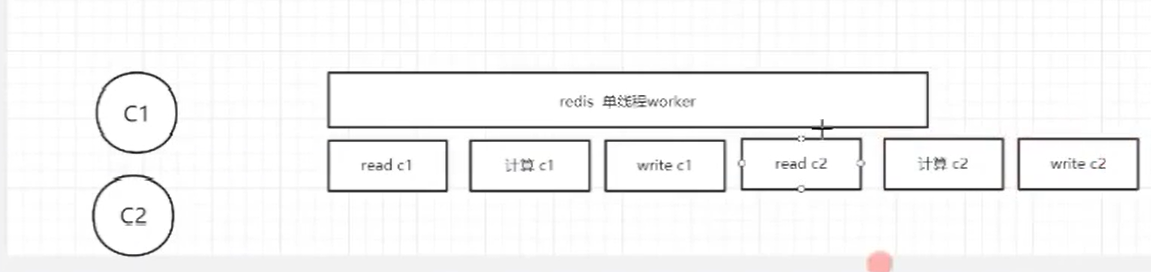<br /> <br />缺点:单线程比较浪费cpu(现在基本上都是多核的)<br /> <br /> <br /> <br />redis的数据类型:如果想要学习操做命令,直接在客户端查看:help @String hash set list zset<br />1. String:操做字符串和数值和二进制的操做(bitmap)<br />使用场景:<br />1. session共享(string)<br />2. Token(string)<br />3. 对象/小文件:静态页面也可以直接存储在里面,或者静态资源(string)<br />4. 分布式锁(string)<br />5. 数值计算可以做秒杀,库存的扣减(数值)<br />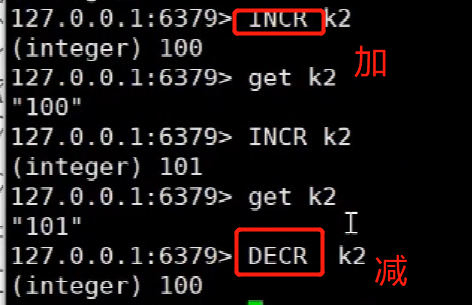<br />6. 位图的操做:bitmap:<br />1. 活跃用户数的统计<br />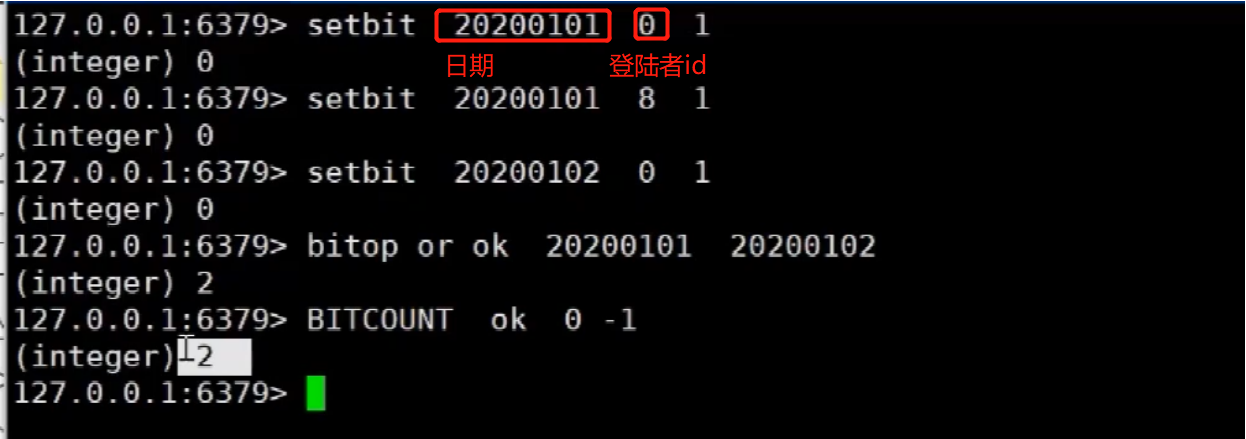<br />2. 某个用户登录次数的统计<br />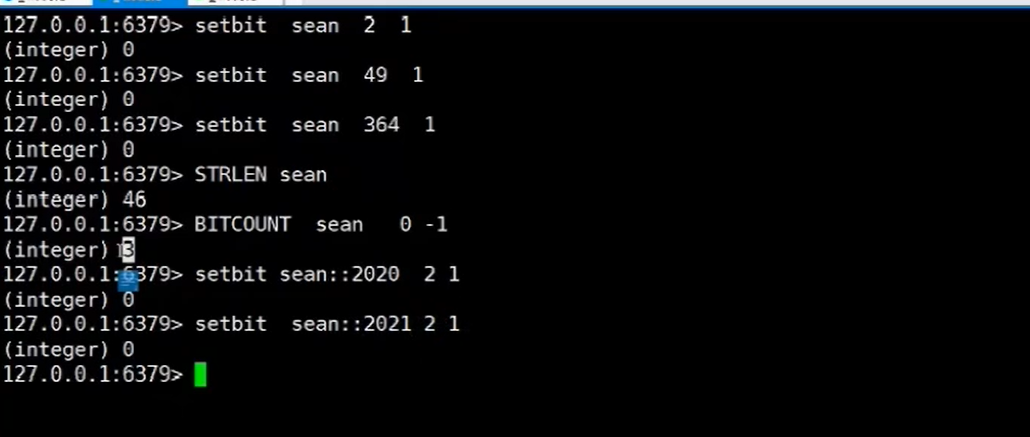<br />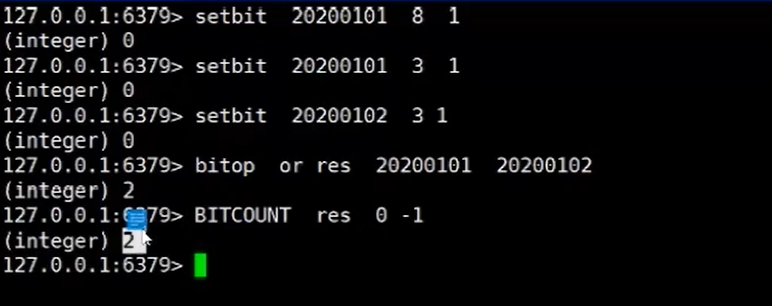<br /> 3.12306买票的优化:<br />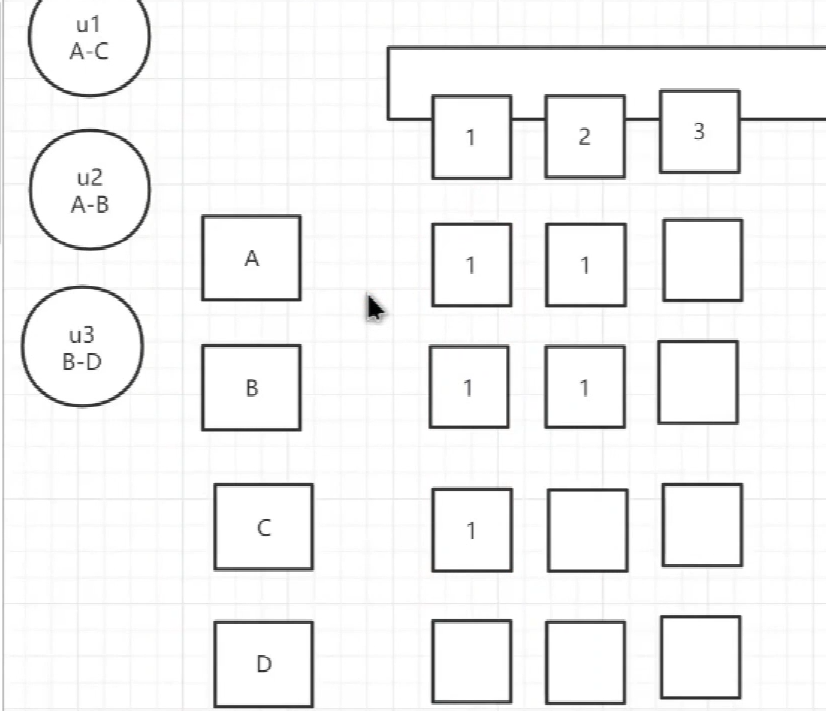<br />补充:什么是二进制:<br /> <br />2. list:左右都可以插入数据,底层是双向链表:同方向是栈,异向是队列,lindex命令还能模拟数组<br />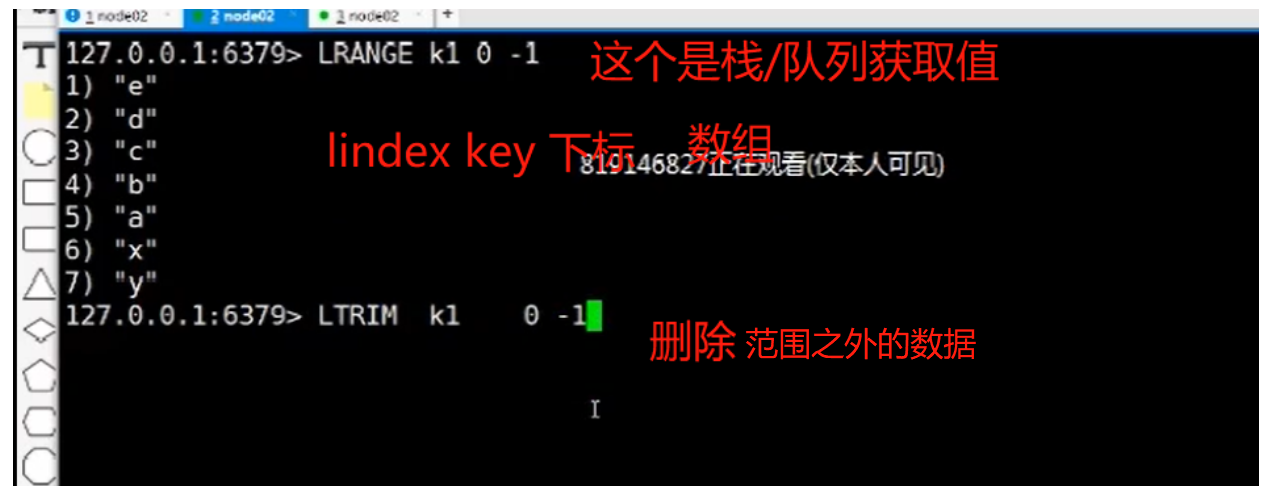<br />使用场景:<br /> 1.<br /> <br />3. hash:<br />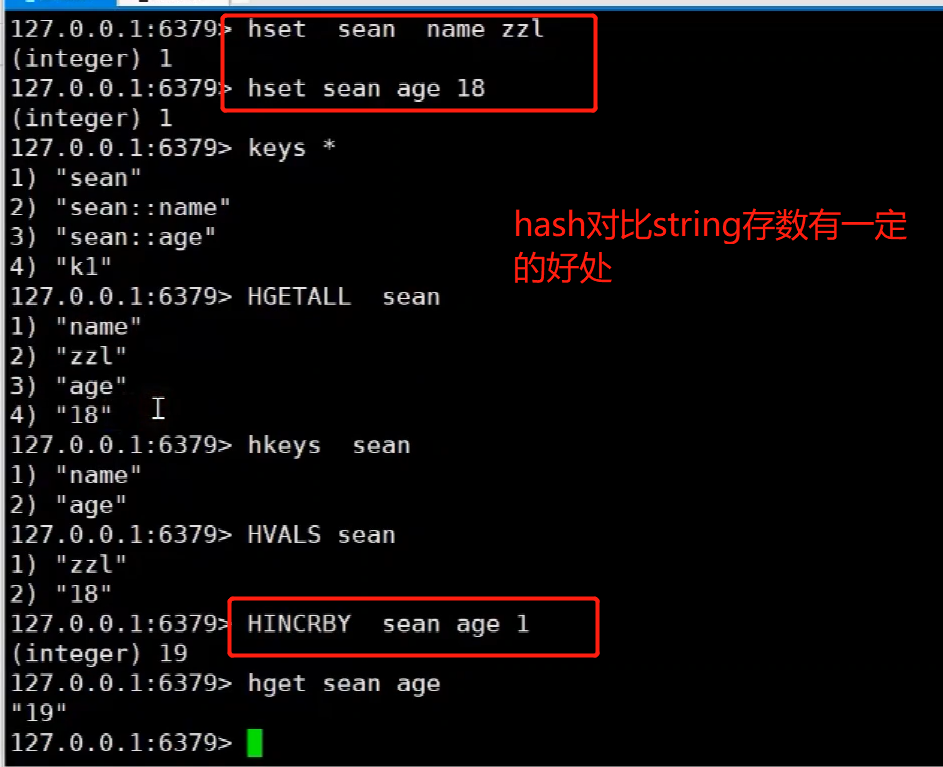<br />场景:1.将数据进行聚合存储:将不同请求的数据从各个不通过的服务中获取并聚合,客户端只需要一次io就能获取全部想要的数据(数据不是经常用的)<br /> <br /> <br />4. set:集合:去重且无序。不建议使用:大量数据获取的时候会影响带宽:如果必须使用建议单独使用一台服务器专门做集合的操做<br /><br />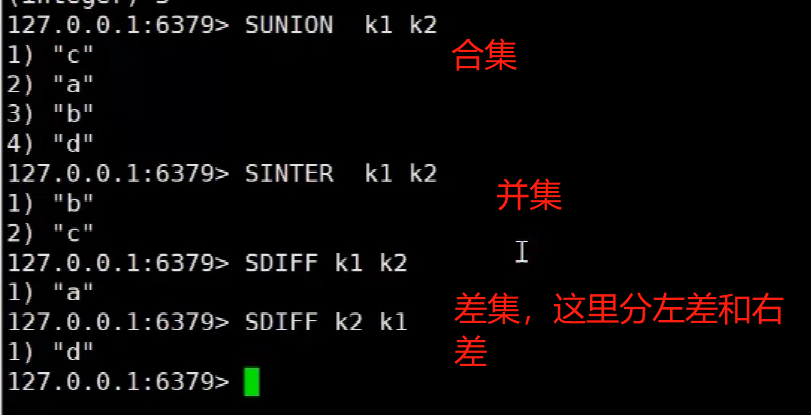<br /> 使用场景:<br />1.推荐系统<br />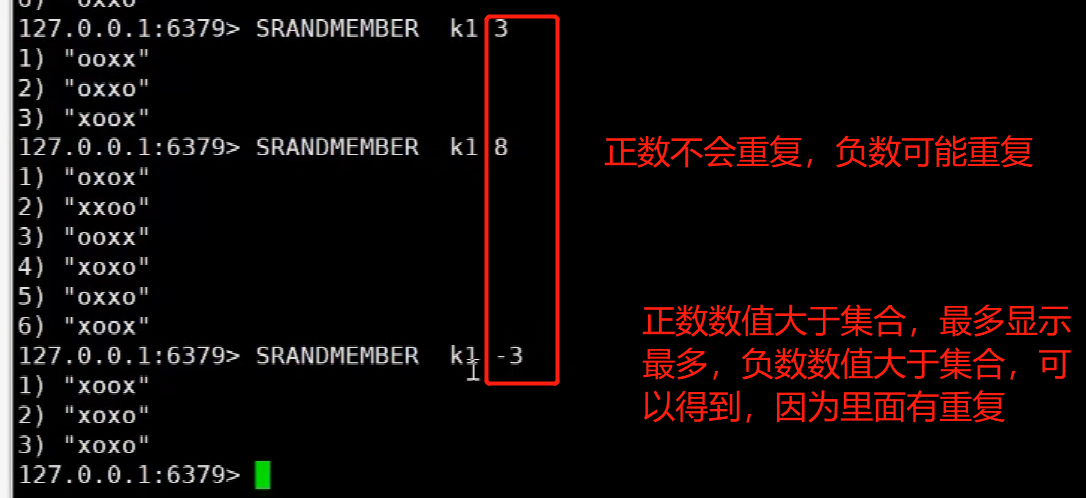<br /> <br />zset:有序集合:<br />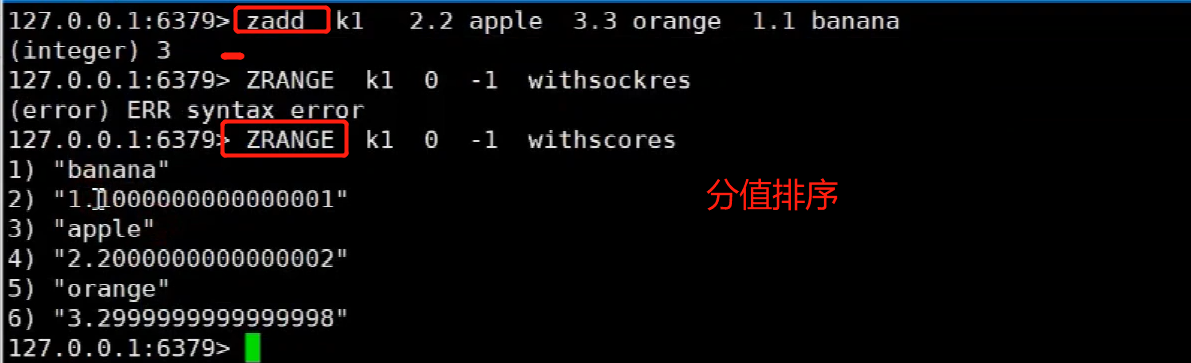<br />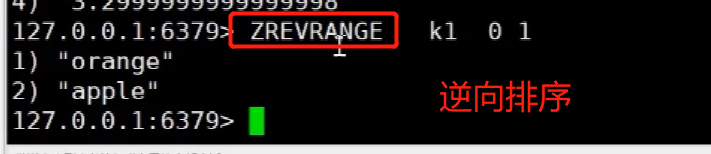<br />使用场景:<br />1. 排行榜<br />2. a评论+分页(动态)<br /> <br />redis的持久化:4.x版本之后可以混合使用<br /> 快照rdb:定期存储(dump.rdb):快但缺失多:默认开启<br /> 日志aof:慢且冗余但丢失少<br /> <br />注意:aof持久化的配置:appendonly yes redis.conf<br /> <br />持久化策略:<br />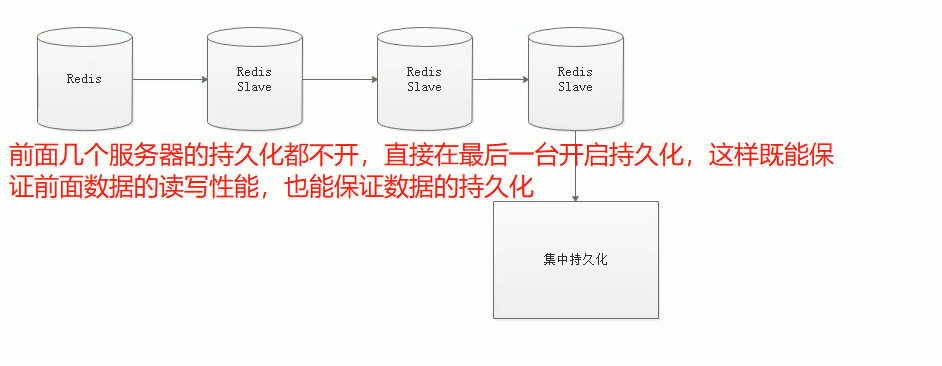<br />redis中的问题:<br />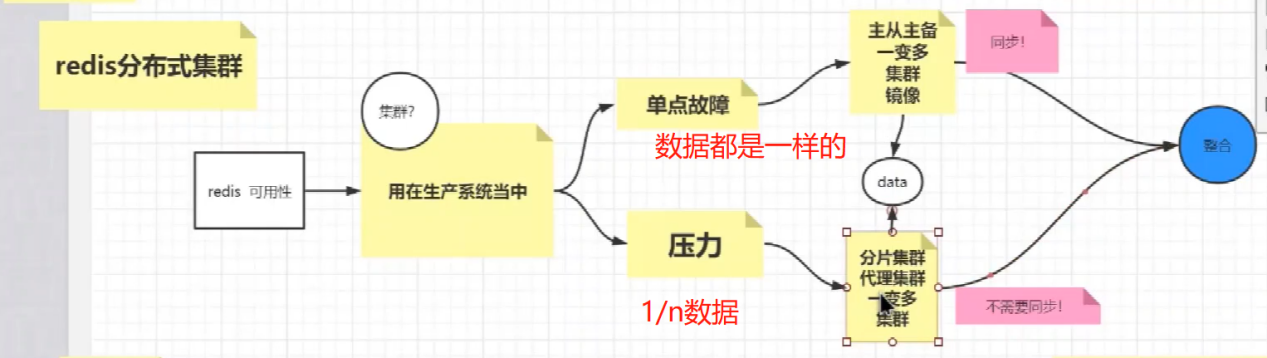<br />注意:这里的分片我们可以采用hash%4这种方式进行分片<br /> <br />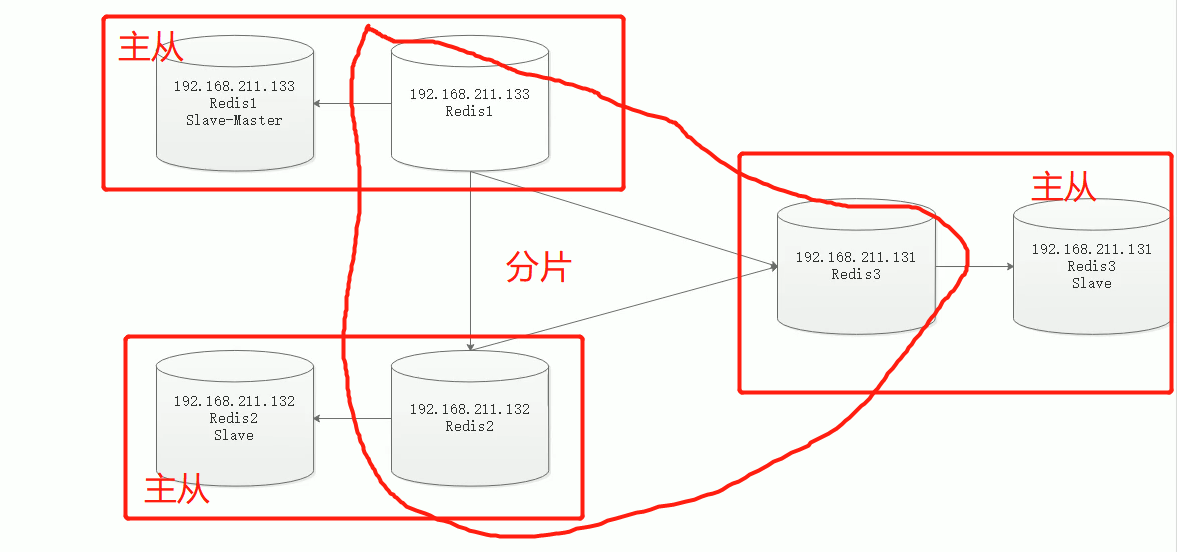<br /> <br />1. 单点问题的数据强一致性问题:<br />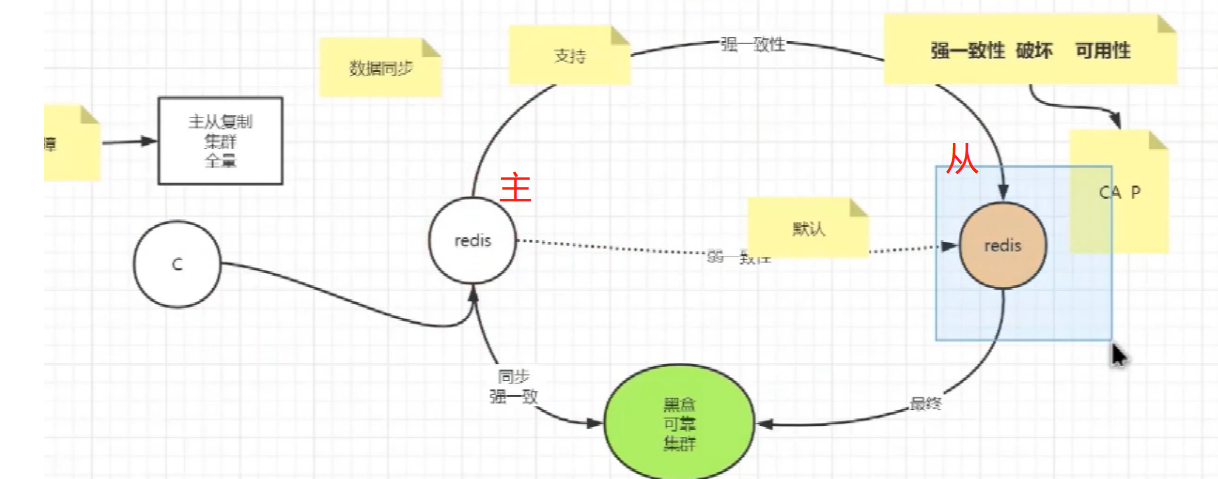<br />1. 强一致性:客户端访问主redis,主redis先不回答客户端,将数据写给从redis,等从redis回复了ok,主redis再回复客户端:这个需要自己配置,当收到几个ok的情况下,主redis再去回复客户端<br />2. 弱一致性:直接给主写数据,不关心从节点是否同步数据成功,主要主节点成功就返回(redis默认采取的是弱一致性)<br /> <br /> <br />缓存穿透:数据库和redis都没有,黑客的攻击,假id的不断攻击:<br /> 解决方案:校验<br />缓存击穿:redis没有,数据库有,用户同时请求数据库,导致io过大<br /> 解决方案:设置为永不过期<br />缓存雪崩:redis中大量的key过期,导致大面积的请求数据库,导致数据库io过大<br /> 解决方案:随机过期时间/二级缓存<br /> <br />Sharding分片存储的思想:<br />1. 在客户端的代码中使用算法来统计将数据存储在哪个redis中<br />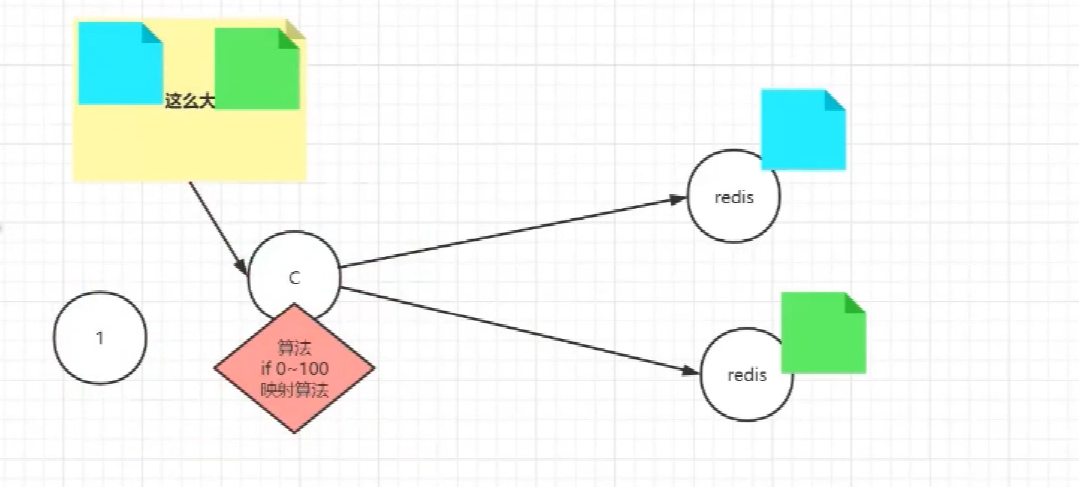<br />2. 使用代理中间件<br />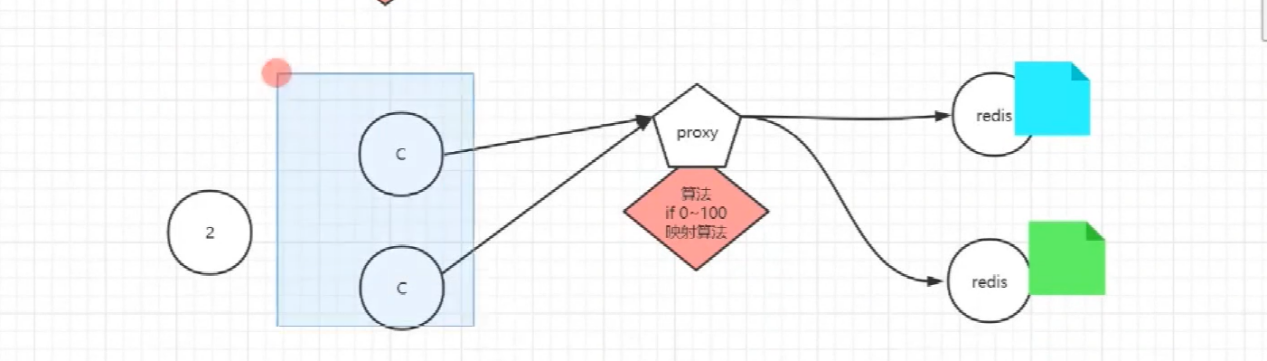<br />3. redis自己提供了一个算法实现数据的存储的统计<br />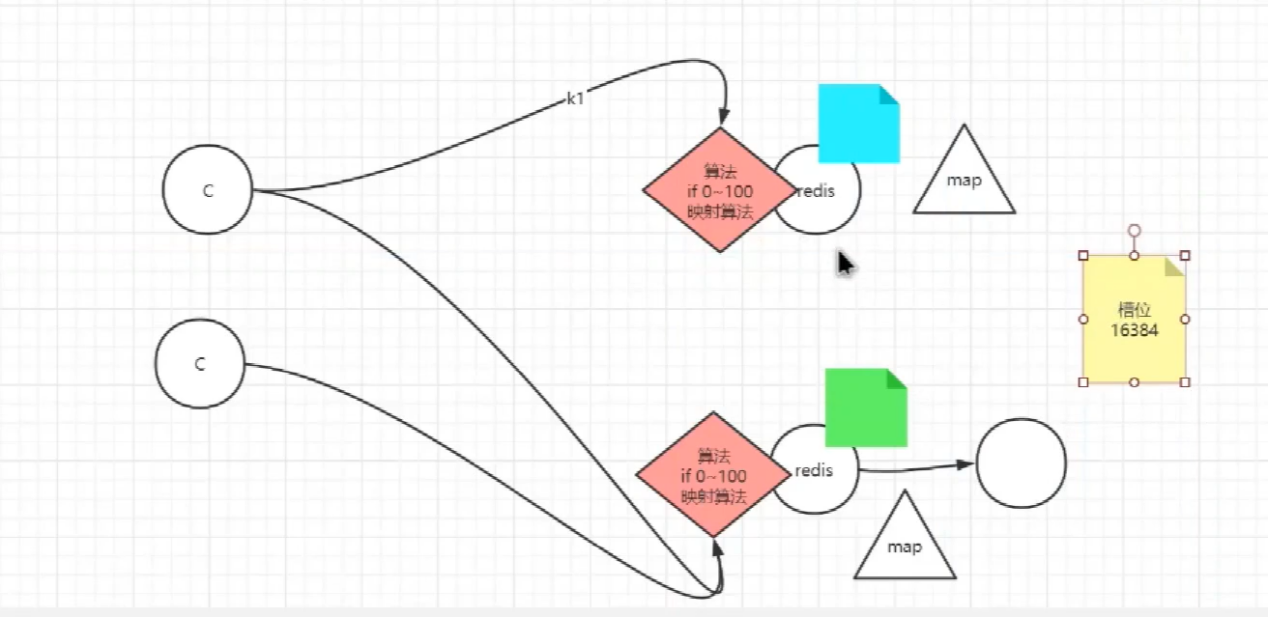<br />讲解:redis提供了一个巢位的概念,一个redis有16384个巢位:将巢位使用map映射进行分配<br />1. 客户端携带过来的key进行hash运算并取模16384,然后结合一个map映射,去放置最后的数据的具体位置:比如第一个map定义是0到10000放在这里,另外放10001到16384,当计算后是10002,那么就给客户端返回一个top,让客户端重新连接另外一台<br /> <br /> <br />redis集群原理讲解:<br /><br />1. 集群中节点的个数正常都是奇数个<br />2. 集群中主节点数过半宕机,则认为集群是失败的<br />3. 客户端只要连接任意一台节点就能获取其他节点的数据<br />4. 在redis集群中会有16384个hash巢,通过map映射分配到各个分片中,<br />5. 任意存入redis中的数据的key经过hash算法,再cr16算法后得到的值在0~16383之间<br />6. 每次存取值都会根据cr16算法得到的值去自己连接的redis节点中找,如果第一次没有命中,则第二次会直接重定向到对应的节点上去<br />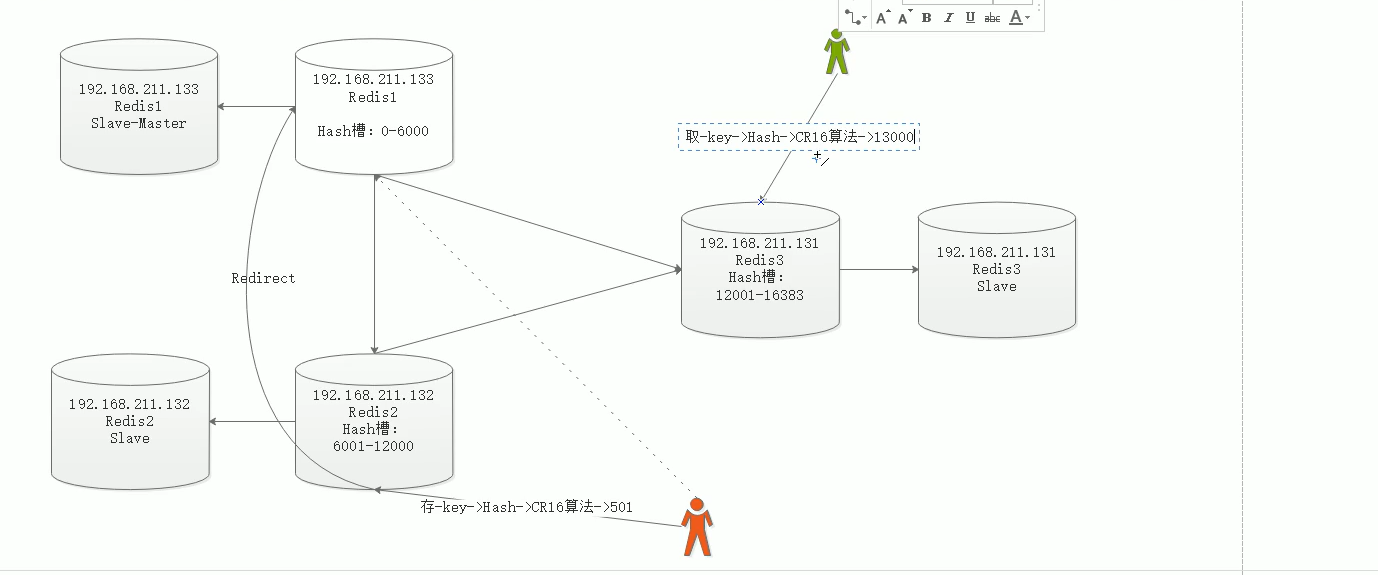<br /> <br /> <br />redis集群的搭建:基于linux的安装步骤(后期改进为docker)<br />1. 因为redis是基于c语言开发的,需要安装依赖:yum install gcc-c++ -y<br />2. 因为集群的搭建过程中需要ruby语言,也安装一下:yum install ruby -y<br />yum install rubygems<br />3. 下载redis的安装包:`wget ``[https://download.redis.io/releases/redis-6.0.9.tar.gz](https://download.redis.io/releases/redis-6.0.9.tar.gz)`<br />4. 解压:tar -zxf redis-6.0.9.tar.gz<br />5. 使用安装包将redis安装到指定路径下:<br />1. 进入到redis安装包:cd redis-6.0.9<br />2. 进入安装包目录之后执行编译命令:make<br />注意:执行编译命令得时候会报错,几乎都是环境依赖问题: 升级gcc<br /> 1.yum -y install centos-release-scl<br /> 2.yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils<br /> 3.scl enable devtoolset-9 bash<br /> 然后重新执行编译命令:make<br /> <br />3. 编译完成之后将其安装到指定目录下:make install PREFIX=/usr/local/redis<br />4. 执行安装测试命令:make test(这个步骤完全可以省略)<br />5. 将解压包路径下的redis.conf移动到redis的安装目录的bin目录下:主要目的是方便管理而已<br />以上单机版本得redis就安装好了<br /> redis启动校验:进入安装目录的bin目录:./redis-server redis.conf<br /> redis客户端连接:进入安装目录的bin目录:./redis-cli<br /> <br />注意:1.linux的top命令也可以查看运行中的服务<br /><br /> 2.redis的配置文件的位置:<br /><br /> <br /> <br />集群的搭建:<br /> 1.主要工作:<br /> 1.安装redis的几个服务器<br /> 2.每个节点需要开启集群<br /> 3.需要用ruby语言将每个节点串联起来(5.x版本以下需要,5.x及以后就直接不需要了)<br /> <br /> 2.集群搭建的详细步骤:在单机版本的基础之上<br />1.开启集群模式:编辑redis的配置文件:redis.conf<br />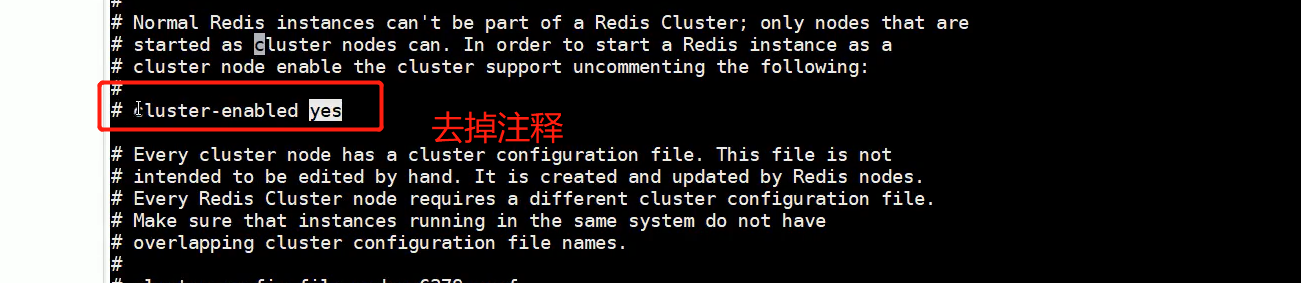<br />2. 启动各个服务:后台启动模式:daemonize yes<br />3. <br /> 1, 5.x版本以前的版本:在任意一台redis集群的节点上执行ruby脚本,实现redis多主多从并实现hash巢的分配:<br />在解压路径下的src目录下执行脚本:<br />./redis-trib.rb create --replicas 1 192.168.74.211:6379 192.168.74.212:6379 192.168.74.213:6379 192.168.74.214:6379 192.168.74.215:6379 192.168.74.216:6379<br /><br /> <br /> <br />2.5.x及以后的版本:直接使用客户端连接命令就好:_./redis-cli --cluster create --cluster-replicas 1_ 192.168.74.219:6379 192.168.74.215:6379 192.168.74.214:6379 192.168.74.218:6379 192.168.74.220:6379 192.168.74.221:6379<br />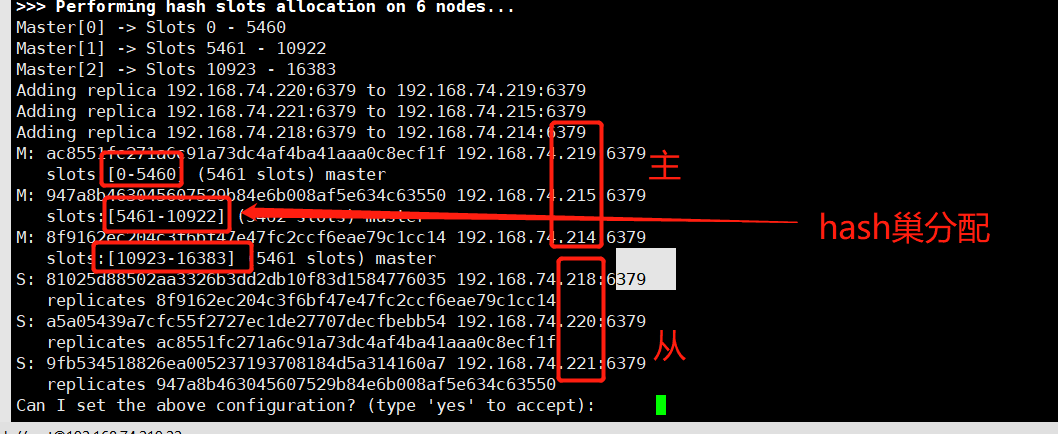<br /> <br />注意:在我们创建集群的时候可能会发生redis无法远程连接问题:<br /> 查看当前redis的运行id号,并杀死进程:ps -aux |grep redis kill -9 xxx<br />1. 保护模式设置为no<br />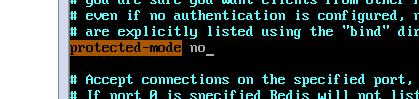<br />2. 注释掉绑定的ip:127.0.0.1<br />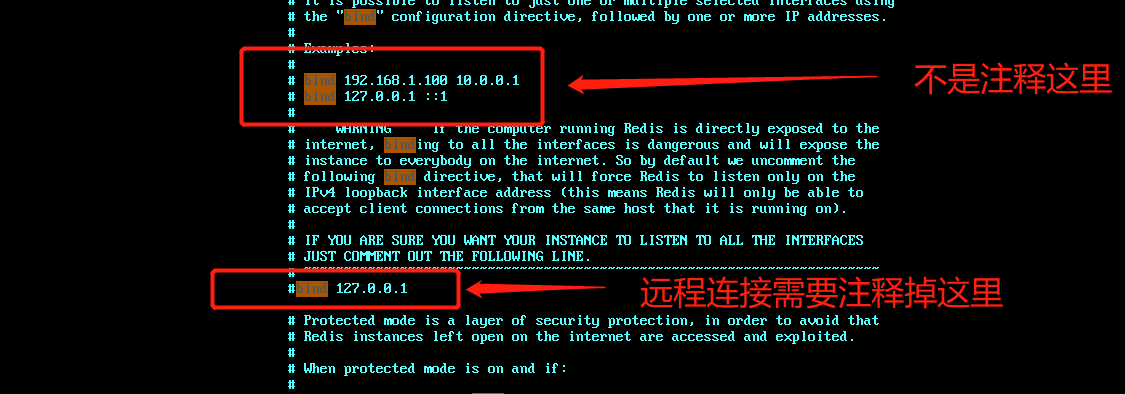<br /> <br /> <br />在idea搭建的java项目中如何连接集群进行使用:直接添加配置就可以使用了<br />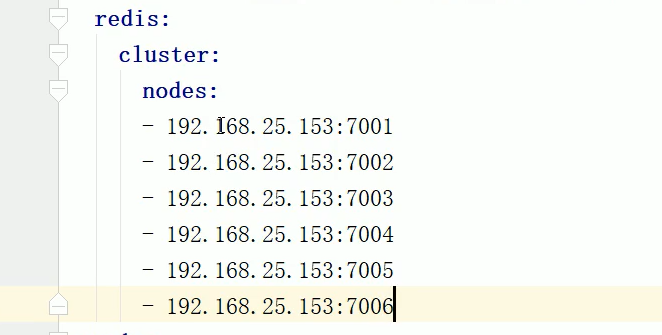<br /> <br />集群中的哨兵策略:监控redis的健康状态并实现redis的主从切换:哨兵本身也存在集群模式<br /> <br />注意:每个redis节点都需要一个哨兵<br /> <br />节点哨兵的搭建:<br />1. 找到解压路径的sentinel.conf配置文件,修改配置文件并复制到安装路径的bin目录下<br /><br />2.开启哨兵模式:进入安装路径的bin目录下:./redis-sentinel sentinel.conf <br />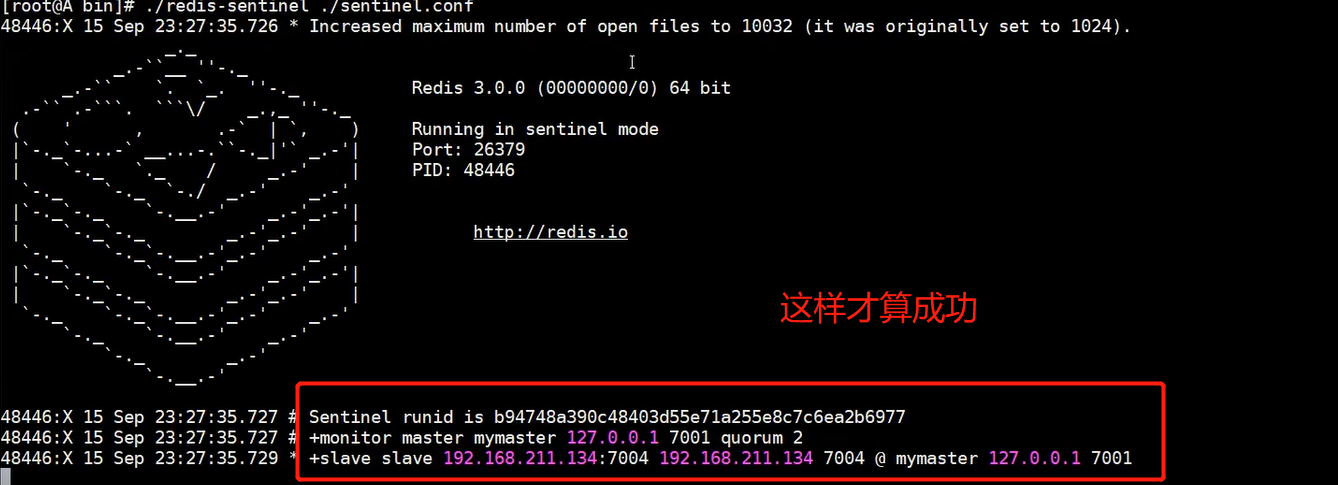<br /> <br />注意:这里的哨兵是需要在主节点启动与监控<br /> <br />项目实战中的缓存架构:<br />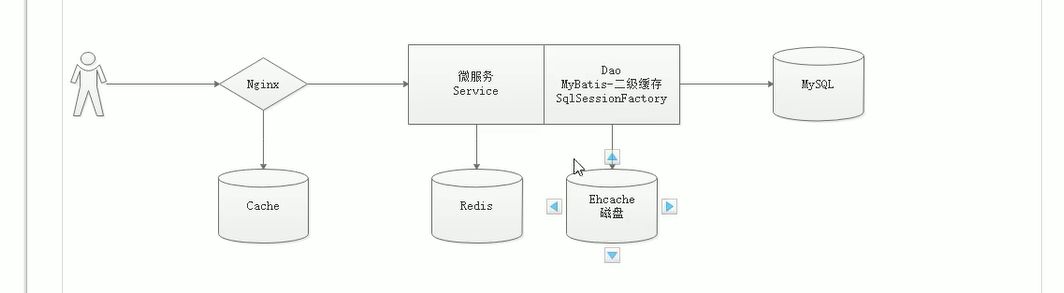<br />缓存同步的实现:canal实现同步:先复制数据库数据,然后同步数据到各个缓存中<br /> <br />

若有收获,就点个赞吧
0 人点赞
