深入理解Mysql索引底层数据结构与算法.ppt
二叉数:极端情况下,会是一个链表,效率低
红黑树:在数据量很大的时候,高度不可控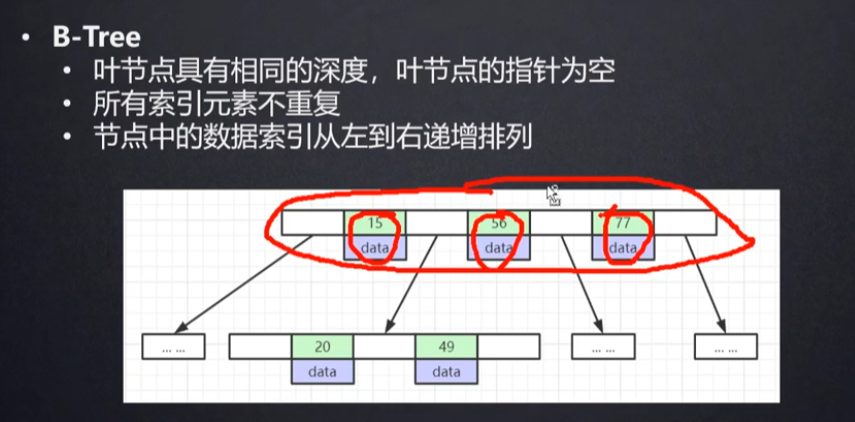


主键索引
数据库引擎-MYISAM
有三个文件:frm(数据表结构信息)、MYD(数据)、MYI(索引)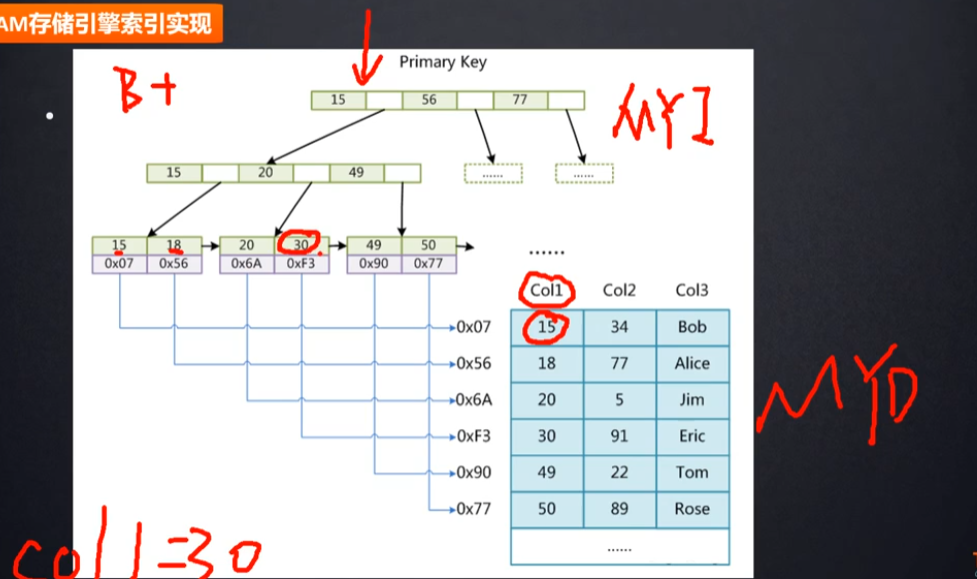
假设Col1设置为索引,现在查询Col1=30
data:索引所在行的磁盘地址(即30对应的0x6A),拿到0x6A,就可以去MYI文件定位我们的具体数据行
数据库引擎-innoDB


为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
开发人员在设计这个InnoDB表的时候,ibd文件存储数据的时候必须要用B+tree来组织,那这个B+tree哪里来啊,如果我们表里面有主键,主键自带索引,那就可以用主键,来组织我们整张表所有数据,那可能有人会问,不建主键,那数据如何存储的呢,如果表不建主键的话,会从表中去选则一列(所有元素都不相等),用这么一列数据去组织B+tree,如果没有选到这么一列,那mysql会建一隐藏列(像rowID),去维护唯一的id,用这个隐藏列去组织整张表数据。mysql数据库资源宝贵,让mysql去组织整张表数据的唯一id不合适,我们本身也是要去建主键的,却要mysql去进行一个挑选操作,更甚去建一个隐藏列。
为何自增?
在不自增的情况下(B+tree会帮你进行排序),比如先插入8,在插入7的情况下,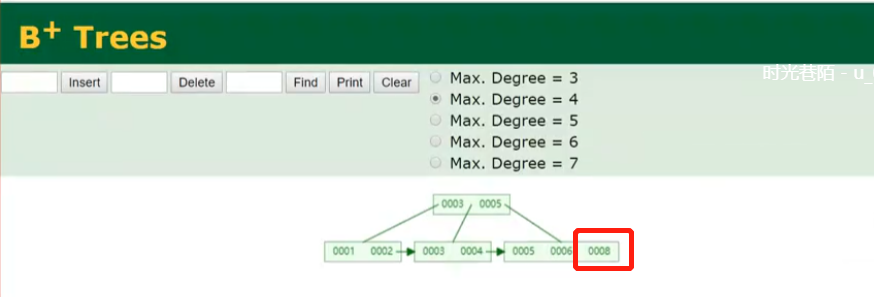

原来的一个大节点分裂成两个小节点,然后还做了一点点平衡。而自增元素都是在后面加,不会涉及到如此复杂的树结构变化
说白了,就是要把每个叶节点的第一个(最小)元素提上去,这是他构建的一个方法。树的构建是这样子,节点如果插满了之后,会把节点的第一个元素提上去,作为冗余索引。
普通索引(innoDB)


Col3作为普通索引,B+tree依然是B+tree,按照字符串进行比较依次递增,但是叶子节点有点不同,放的是聚集索引值(整张表只有一个聚集索引)。
为何不在这个普通索引的叶子节点下放索引和数据?
1、节约存储空间:如果有三四个普通索引,就会放三四个索引和数据,浪费空间;
2、一致性:在插完一行记录的时候,主键索引和非主键索引都要维护整张表数据的话,是不是要涉及到这两个索引都插完之后才认为是成功了,但凡一个没有成功,都会出现问题。但是要是如上图所示设计的话,我们可以等主键索引创建成功了以后,再创建普通索引再把对应的主键值放进来(减少复杂度)。
联合索引
索引最左前缀原理
如何进行排序:先比较name,再比较age,再比较position.(下图为联合主键,不可能有相同的)
最左前缀原理为何先name,再age,再position?
假设现在条件判断为where age = 30 and position = “dev”;我们从上图得知,在整张表中去看age这一行的时候,不在是排好序的结构了,那就意味着我们需要全表扫描找到所有age-30的数据。(我们的B+tree结构的高效体现在排好序)
回表:用二级索引去查,比如col = “Eric”,去ibd文件找到对应的30,然后再去ibd文件找30对应的数据,这就是回表。
什么建议In咋noDB表必须建主键,并且推荐使用整型的自增主键?

若有收获,就点个赞吧
0 人点赞
