07-VIP-深入理解MVCC与BufferPool缓存机制.pdf
mvcc机制
1、undo日志版本链(只有一份)与read view机制详解
undo日志版本链是指一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚 日志,并且用两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链(见下图,需参考视 频里的例子理解) 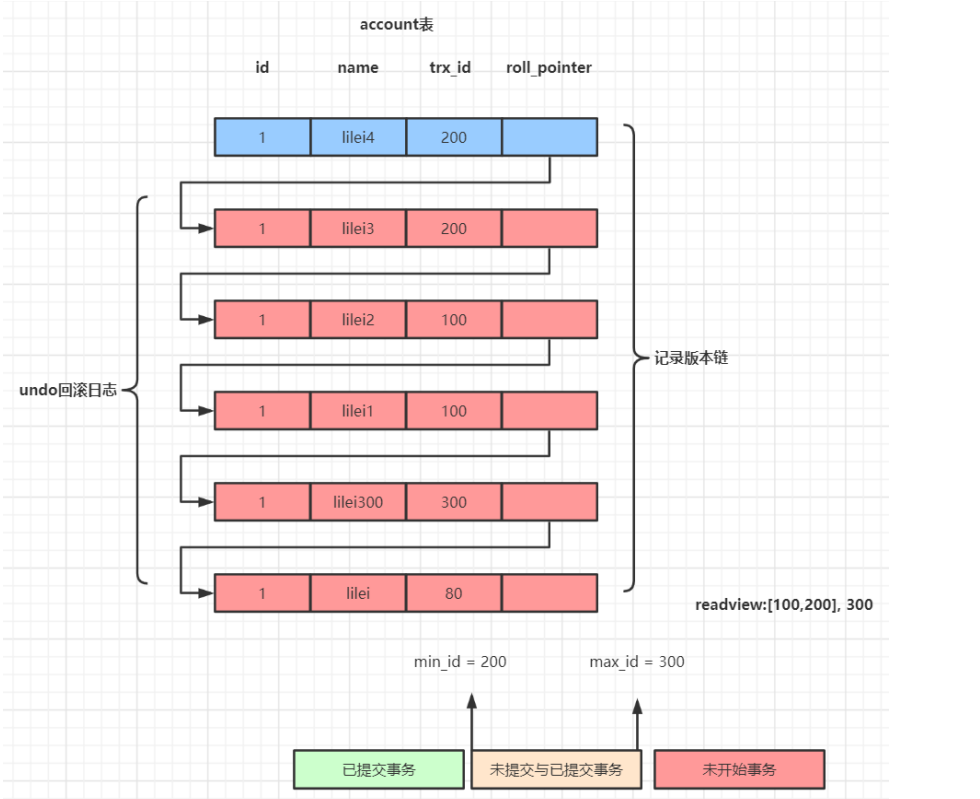
undo日志,即回滚日志。
例如:把一个商品减库存(10-6),但是失败了,抛异常,回滚到了10,但是我们怎么回滚啊,就是靠undo日志。就是在你改之前会把你库存=10的数据记录在undo日志中(汇总,即数据改之前会将你的数据先在undo日志保存一份,万一没改成功,就回滚)
针对一行数据,可能做很多修改,对数据库来说,会把每一次的undo日志,用一个指针给串联起来。
例如account表,有id、name会有两个隐藏字段trx_id、roll_pointer(回滚指针)
数据1 
把name修改成lilei300 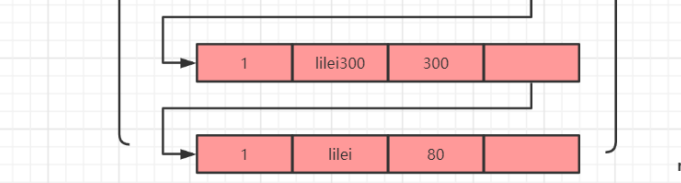
事务id(trx_id):这条数据操作的那个事务对应的id。roll_pointer(回滚指针):指向之前的旧数据,如果事务失败,可以根据这个字段找到老数据并回滚。
不断的执行事务,并对数据进行修改操作,形成一条条的undo回滚日志,即记录版本链
假设我们之前的事务1读到了lilei300这条数据,按照MVCC机制,只要这个事务不结束,再执行相同的查询语句这个name还是=lilei300(但是在经过其他多个事务,这条数据已经被改成name=lilei4),这个到底是怎么实现的呢?
2、一致性视图read-view
MVCC机制举例.xlsx
在可重复读隔离级别中, 当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束 之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),这个视图由执行查询时所有未提交事 务id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成,事务里的任何sql查询结果需要从对应 版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。 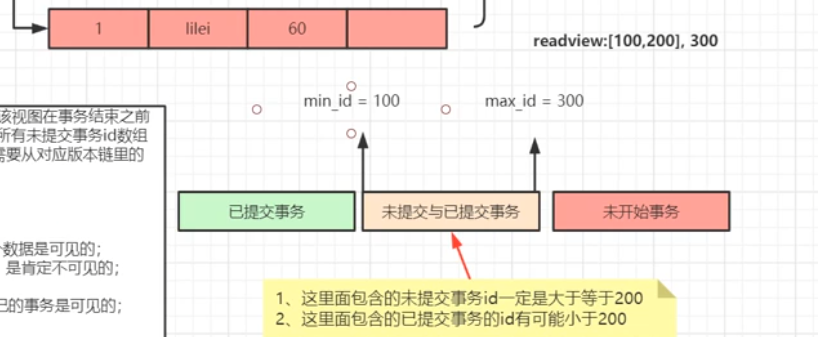
3、版本链比对规则
如果 row 的 trx_id 落在绿色部分( trx_idmax_id ),表示这个版本是由将来启动的事务生成的,是不可见的(若 row 的 trx_id 就是当前自己的事务是可见的); 3. 如果 row 的 trx_id 落在黄色部分(min_id <=trx_id<= max_id),那就包括两种情况 a. 若 row 的 trx_id 在视图数组中,表示这个版本是由还没提交的事务生成的,不可见(若 row 的 trx_id 就是当前自 己的事务是可见的); b. 若 row 的 trx_id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
注意:begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个修改操作InnoDB表的语句, 事务才真正启动,才会向mysql申请事务id,mysql内部是严格按照事务的启动顺序来分配事务id的。
Innodb引擎SQL执行的BufferPool缓存机制
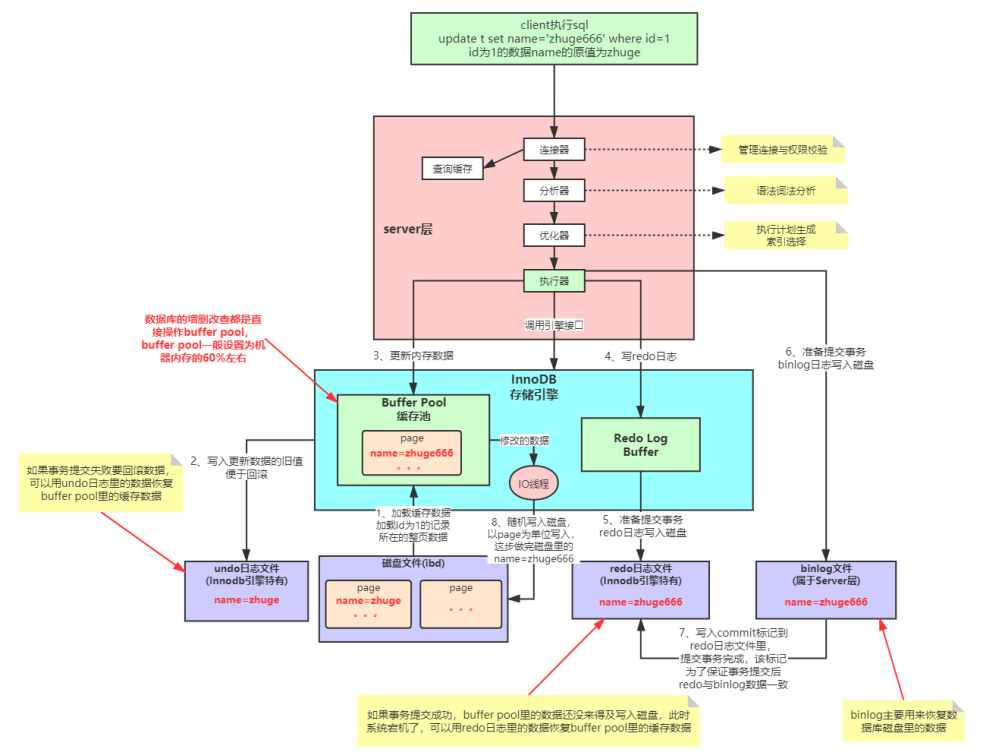
1、执行器调用引擎接口,(非先更新磁盘,即放入ibd文件)先将id= 1,name=”诸葛”所在的整页数据加载到innodb引擎的buffer pool缓存池中
2、写入更新数据的旧值到undo日志文件,便于回滚
3、更新内存数据,先更新Buffer Pool中的数据
4、写入redo Log Buffer(重做),就是刚刚更新完的数据(name=zhuge666)
5、准备提交事务,将redo log Buffer里的数据写入redo日志文件(也就是写入磁盘),这个是批量写入的
6、准备提交事务,binlog日志(server层独有的,存储引擎共享)写入磁盘,也是刚刚更新完的数据(name=zhuge666)
7、写入commit标记到redo日志文件里,提交事务完成,该标记为了保证事务提交后redo和binlog日志数据一致。
binlog日志:主要用来恢复数据库磁盘里的数据。
redo 日志:重做,重新刷新buffer pool里面的数据,再由IO线程写入磁盘
到这一步更新数据还兵没有到磁盘文件ibd,万一mysql挂了,怎么办?
redo日志就是保证这样的场景而不出错的;如果事务提交成功了,buffer pool里的数据还没来的及写入磁盘,此时系统宕机了,可以用redo日志里的数据恢复buffer pool里的缓存数据
8、buffer pool里面的数据由IO线程来随机写入磁盘(以页为单位写入),什么时候写,不确定;这步做完磁盘里的name=zhuge。
mysql为何要设计如此复杂的机制来存储数据,这个数据存储过程中还涉及到redo日志的恢复,难道不能一次直接存入磁盘中么?
还是性能问题,整个数据库的增删改查都是根据buffer pool来做的,比如查询,就算你的磁盘上的数据还是老的,你发起的查询id = 1的数据,注意,直接从buffer pool里面获取数据的。buffer pool里面的数据在commit以后就变成了最新的数据了,所以是没有任何问题的,他是基于缓存去做的。基于内存去操作,肯定比基于磁盘操作更快。
但是这边还多些一个redo日志文件,在提交之前需要将commit标记写入redo日志,感觉效率也不是特别高?
这边很简单,针对于我们的数据库的写读,实际上是随机的读写,针对redo日志的写读,是磁盘顺序写入;顺序IO和随机IO之间的效率相差了2-3个数量级,顺序IO写读是可以与与内存操作相媲美。
这就是mysql为何要设置这么一个机制的原因
redo的顺序IO和kafka很像,顺序写,不涉及到删除,然后根据offset去消费
但是磁盘文件ibd,有时候会删除数据,删除的空间可能写了其他数据,不能顺序读
为什么Mysql不能直接更新磁盘上的数据
而且设置这么一套复杂的机制来执行SQL了?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。
因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。 Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能 保证各种异常情况下的数据一致性。 更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。 正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。

若有收获,就点个赞吧
0 人点赞
