01-高性能表结构及索引设计最佳实践.pdf
新系统
刚刚开始阶段,设计表先按照范式去进行设计,先完成功能
后期业务上线了,业务量上来了,在视情况,进行sql优化等(反范式)
范式
第一范式(1NF)
保证每列的原子性
属于第一范式关系的所有属性都不可再分,即数据项不可分(原子性)
比如有一张用户信息表:
一般来说”住址”设计成一个字段就行,但是如果经常访问”住址”中城市的部分,那么就非要将”住址”这个属性重新拆分为”省份”、”城市”、”地址”等多个部分进行存储,这样在对”住址”中某一部分进行操作的时候将非常方便。这么设计才算满足了数据库的第一范式,修改之后的表结构如图:
第二范式(2NF)
保证一张表只描述一件事情
要求数据库表中的每个实例或行必须可以被惟一地区分。
例1:订单表,产品表
一个订单有多个产品,所以订单的主键为【订单ID】和【产品ID】组成的联合主键,这
样2个组件不符合第二范式,而且产品ID和订单ID没有强关联,故,把订单表进行拆分为
订单表与订单与商品的中间表
列2: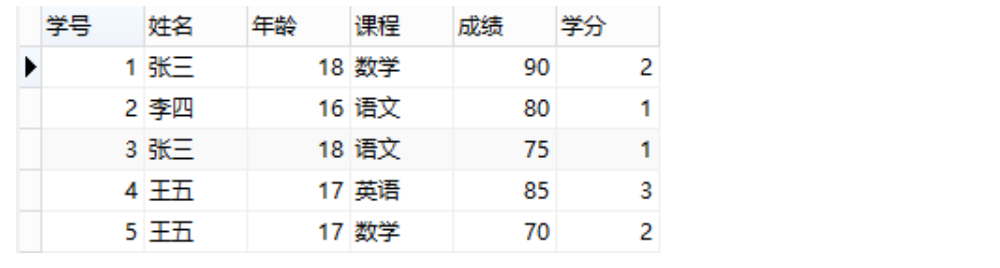
表满足第一范式,即每个字段不可再分,但是这张表设计得并不好,或者说,这张表的设计并不满足第二范式。因为这张表里面描述了两件事情:学生信息、课程信息,”学分”完全依赖于”课程名称”、”姓名”与”年龄”完全依赖于”学号”。这么做的后果是:
1、数据冗余:同一门课程由n个学生选修,”学分”重复n-1次;同一个学生选修了m门课程,姓名和年龄重复m-1次
2、更新异常:若调整了某门课程的学分,数据表中所有行的”学分”值都需要更新,否则会出现同一门课程学分不同的情况
3、插入异常:假设要开一门新课程,暂时没有人选修,那么由于没有”学号”关键字,”课程”与”学分”也无法记录入数据库
4、删除异常:假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,”课程”和”学分”也被删除了,显然,这最终可能会导致插入异常
所以,此表的结构必须修改,修改后如下:
第三范式(3NF)
保证每列都和主键直接相关或者理解为决定某字段值的必须是主键。
每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。
举个例子,看一下如下的表结构:
第三范式和第二范式有点像,从这张数据库表结构中可以看出,”姓名”、”年龄”、”学院”和主键”学号”直接关联,但是”学院地点”、”学院电话”却不直接和主键”学号”相关联,和”学院电话”直接相关联的是”学院”,如果表结构这么设计,同样会造成和第二范式一样的数据冗余、更新异常、插入异常、删除异常的问题。
巴斯-科德范式(BCNF)
第四范式(4NF)
第五范式(5NF,又称完美范式)
反范式
完全符合范式化的设计真的完美无缺吗?很明显在实际的业务查询中会大量存在着表的关联查询,而大量的表关联很多的时候非常影响查询的性能。所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反。允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间。
实际工作中的反范式实现:
性能提升-冗余:副表里的字段冗余一部分到主表,查询的话只查主表,不查副表
缓存:统计用户发表了多少次记录,原本select count(*) from;现在直接发表一次记录,在主表字段+1;这样就不需要去进行计算用户记录表
汇总:有些数据每次查,都需要从好几个表里面写很复杂的sql,显示在报表页面上,后来觉得这个报表没什么用,每次统计都划不来;
干脆把汇总后的数据放在一个汇总表里面,每次存放,用的时候就从这个汇总表里面去查询,有频次的把数据进行汇总,然后写入汇总表
缓存和汇总有什么缺点?一致性问题
因为你的数据多放了一份
更新的时候有什么策略呢? 1、实时维护;比如上面的记录统计,(在用户表插入一条记录的同时,在主表字段+1)整体上一个事务
2、定期重建:比较适合汇总,汇总数据实时性不是那么强,可以在晚上进行
性能提升-计数器表:
反范式设计-分库分表中的查询:在电商系统中,用户购买商品,对于用户来讲,买家有交易记录,卖家也有交易记录,商品是放在买家表还是卖家表呢
如果放在买家表里面,查询订单,很好查;但是在卖家查询就不是很方便了。
解决方法:买家记录放一份,卖家记录也放一份,就是都各冗余一份
当然也可以用搜索,因为下订单的信息基本上是不会改的
表设计总结:1、尽可能遵循范式设计
2、当范式设计成为约束你系统性能的阻碍的时候,毫不犹豫,启用反范式设计
索引

很明显,回表的记录越少,性能提升就越高,需要回表的记录越多,使用二级索引
的性能就越低,甚至让某些查询宁愿使用全表扫描也不使用二级索引。
那什么时候采用全表扫描的方式,什么时候使用采用二级索引 + 回表的方式去执
行查询呢?这个就是查询优化器做的工作,查询优化器会事先对表中的记录计算一
些统计数据,然后再利用这些统计数据根据查询的条件来计算一下需要回表的记录
数,需要回表的记录数越多,就越倾向于使用全表扫描,反之倾向于使用二级索引
+ 回表的方式。
回表可能导致一个问题MRR(多范围
读取),即通过二级索引查到的主键id不一定是有序的,这就导致,回表通过主键id查询数据的时候是随机查询(随机IO),效率极低
解决方案:先给一部分排序,排好序,到聚簇索引去进行统一的回表操作
自适应哈希索引
正常的B+tree树一般3-4层,也就是3-4次IO查询;而在InnoDB引擎内维护一张索引表,一但这个索引查询次数多了,会被认为是热数据,会直接放入hash(内部自己创建的),下次通过这个索引再查询的时候,直接hash一次就查到了而不必查询3-4次,提高了效率。
InnoDB存储引擎使用的哈希函数采用除法散列方式,其冲突机制采用链表方式。
全文检索之倒排索引
它是将存储于数据库中的整本书或整篇文章中 的任意内容信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词 等信息,也可以进行各种统计和分析。我们比较熟知的Elasticsearch、Solr等就是全文 检索引擎,底层都是基于Apache Lucene的。
但是如果我们现在有个需求:要求找到包含“望”字的诗词怎么办?
数量少,大概性能还能接受, 如果数据量稍微大点,就完全无法接受了,更何况在互联网这种海量数据的情况下 呢?怎么解决这个问题呢,倒排索引
高性能的索引创建策略
索引列的类型尽量小
利用索引选择性和前缀索引
索引的选择性/离散性 :索引值字段/总行数的比值,数值越高,查询效率越高,能筛选掉更多的数据(唯一索引是最好的,比值为1,效率也最高)
模拟哈希索引和前缀索引
前缀索引,既不能太长,也不能太短,字符串类型,20长度为最佳
缺点:无法使用order by和group by
后缀索引(反转,例如邮箱,后,参考前缀索引)

若有收获,就点个赞吧
0 人点赞
