本章主干知识点:
- 服务器返回的状态码 200、302、404、500 分别是什么意思?
- GET 和 POST 的区别
- server.MapPath 的作用
- ContentType 的作用
- ASP.NET 处理文件上传
- ASP.NET 中对于用户上传的文件要做哪些检查
HTTP 协议
HTTP(超文本传输协议)是一种用于分布式、协作式和超媒体信息系统的应用层协议,它是万维网数据通信的基础。
- 连接(Connection):浏览器和服务器之间传输数据的通道(一般就是个 socket 通道)。 一般请求完毕就关闭,HTTP 不保持连接。不保持连接会降低处理速度(因为建立连接速度很慢),保持连接会降低处理客户端的并发请求数,而不保持连接服务器可以处理更多的请求
- 可以通过 Keep-Alive、Http/2 等实现保持连接
- 请求(Request):浏览器向服务器发送“我要 xxx”的消息,包含请求的类型、请求的数据、浏览器的信息(语言、浏览器版本等)
- 响应(Response):服务器对浏览器的请求返回的数据,包含是否成功、错误码等
- 浏览器不知道服务器内部发生了什么,也不知道服务器是直接输出静态文件还是经过 C# 运算动态输出
- 处理(Process)
HTTP 协议报文
页面图片请求的 Referer: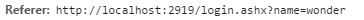
表示对这张图片的请求来自于 login.ashx 页面。
Refer 可以用来判断用户是从那个页面来到当前页面的。
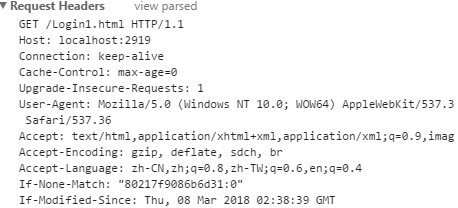
Request Headers:
- GET / HTTP/1.1:用 GET 方式向服务器请求首页,使用 HTTP/1.1 协议
- User-Agent(UA):浏览器版本信息。通过该信息可以读取浏览器是 IE 还是 FireFox、支持的插件、.NET 版本等
- Referer:请求的来源页面、所属页面
- Accept-Encoding:服务器支持什么压缩算法
- Accept-Language:浏览器支持什么语言
注:浏览器请求是可以伪造的,不能信任。
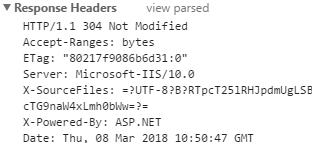
Response Headers:
- Content-Type: 返回数据类型
- charset:报文体编码格式
- Accept-Ranges:服务器是否支持断点续传
- Server:服务器版本
- X-Powered-By:服务器端语言
- Content-Length:正文字节数
注:响应也是可以造假的,有的网站通过修改 X-Powered-By 和 Server 来隐藏服务器信息以欺骗黑客。
响应码
- 200:OK
- 302:Found 暂时转移,用于重定向。Response.Redirect() 让浏览器以 GET 方式再请求一次重定向的地址
- 304:服务器把文件的修改日期通过 Last-Modified 返回给浏览器,浏览器缓存该文件。当下次向服务器请求该文件时,通过 If-Modified-Since 问服务器“我本地的文件的修改日期是……”,服务器如果发现文件没有修改,就返回 304 Not Modified,浏览器继续使用本地缓存
- 可通过 Ctrl + F5 强制刷新
- 403:客户端访问未被授权。
- 404:Not Found
500:服务器错误(一般服务器出现异常),通过报错信息找出异常的点
总结:2xx 没问题;3xx 浏览器需要干点啥;4xx 浏览器错误;5xx 服务器错误
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
重定向示例:
将页面重定向至 1.html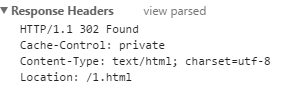
Size 谜题
- Login1.html 在本地是 854 B
- 浏览器第一次请求 Size 是 1.2K
浏览器之后(有缓存)请求 Size 只有 295B
注:Login1.html 是个单纯的 HTML 文件,内部不包含图片等页面资源,但浏览器依然进行了缓存,由此看出浏览器不仅缓存页面资源也缓存网页源码。
SOF 上关于该问题的解析:
“Size” is the number of bytes on the wire,
and “content” is the actual size of the resource. A number of things
can make them different, including:
- Being served from cache (small or 0 “size”)
- Response headers, including cookies (larger “size” than “content”)
- Redirects or authentication requests
gzip compression (smaller “size” than “content”, usually)
GET 与 POST
区别:GET(默认值)通过 URL 传递表单值,POST 传递的表单值隐藏到 HTTP 报文体中
GET 传递的数据量有限、且明文传递不适合传递密码
POST 注意点:无法把网址发给其他人
若原来是 POST,F5 刷新依然是 POST,但在地址栏回车会变成 GET
URL 中的汉字、特殊符号等会被编码。
GET 通过 URL 传值:
POST 通过报文头传值: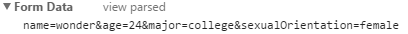
HttpContext
HttpContext:和本次请求相关对象的一个上下文对象,一般通过它获取其他对象。
在 HttpHandler 的
ProcessRequest 方法中可以通过方法的
context 参数获得该对象。
在其他地方可以通过 HttpContext.Current 拿到当前请求堆栈中的 HttpContext 对象,但是建议通过参数传递,这样思路清晰,避免对全局对象的依赖。
注:在子线程是无法获得 HttpContext.Current
推荐通过参数传递 HttpContext:
public void ProcessRequest(HttpContext context){...Test(context);context.Response.Write("</body></html>");}void Test(HttpContext context){if (!string.IsNullOrEmpty(context.Request["wonder"])){context.Response.Write("梦想");}}
HttpRequest
context.Request(HttpRequest 类型),包含请求相关的信息。
- context.Request.Form[“name”]:获取 POST 请求中的值
- context.Request.QueryString[“name”]:获取 GET 请求中的值
context.Request[“name”]:依次从 QueryString、Form、Cookies、 ServerVariables 中找,第一个找到的就是(下面通过反编译进行了验证)
注:所有 HttpRequest 的信息都来自于浏览器当初发送请求的 Request Headers。服务器无法获知任何浏览器未提交的信息。
通过 JetBrains dotPeek 反编译 HttpRequest 的索引器:
public string this[string key]{get{string str1 = this.QueryString[key];if (str1 != null)return str1;string str2 = this.Form[key];if (str2 != null)return str2;HttpCookie cookie = this.Cookies[key];if (cookie != null)return cookie.Value;return this.ServerVariables[key] ?? (string)null;}}
HttpRequest 示例:
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";// Brower 还有很多属性context.Response.Write(context.Request.Browser.Browser + "\n");context.Response.Write(context.Request.Browser.Platform + "\n");context.Response.Write(context.Request.Browser.Version + "\n");context.Response.Write("--------------\n");foreach (var key in context.Request.Headers.AllKeys){context.Response.Write(key + ":" + context.Request.Headers[key] + "\n");}context.Response.Write("--------------\n");context.Response.Write(context.Request.HttpMethod+ "\n");context.Response.Write(context.Request.InputStream + "\n");context.Response.Write(context.Request.Path + "\n");context.Response.Write(context.Request.QueryString + "\n");context.Response.Write(context.Request.PhysicalPath+ "\n");context.Response.Write(context.Request.UserAgent + "\n");// 客户端 IP 地址context.Response.Write(context.Request.UserHostAddress + "\n");context.Response.Write(context.Request.UrlReferrer + "\n");context.Response.Write(context.Request.UserLanguages + "\n");}

HttpResponse
context.Response,包含响应相关信息。
- ContentType:返回数据类型
- OutputStream:输出流
- End():将当前所有缓冲的输出发送到客户端,停止该页的执行
- Redirect():重定向
通过对 End() 进行异常捕获,发现是抛出了 ThreadAbortException,所以 End() 之后的代码就不会执行了。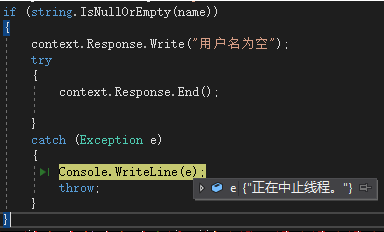
因为异常处理效率低,所以能用 return 时就不用 End():
if (string.IsNullOrEmpty(name)){context.Response.Write("用户名为空");context.Response.End();}if (string.IsNullOrEmpty(pwd)){context.Response.Write("密码为空");return;}
context.Server
Server 是一个 HttpServerUtility 类型的对象
- MapPath:将虚拟路径(~代表项目根目录)转换为磁盘上的绝对路径,操作项目中的文件时常用
- HtmlEncode、HtmlDecode:HTML 编码解码
- UrlEncode、UrlDecode:URL
编码解码。汉字、特殊字符(空格、尖括号)等通过 URL 传递时需编码
- URL 传输前最好进行 UrlEncode 编码
- Transfer()
MapPath:
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/html";// 绝对路径,一旦项目移动到其它位置就失效了;但程序中也不提倡使用相对路径,容易进坑//var fi = new FileInfo(@"F:\Projects\ASP.NETCoreDemo\Web1\海错图.jpg");// 转换相对路径为绝对路径var imgPath = context.Server.MapPath("~/海错图.jpg");var fi = new FileInfo(imgPath);context.Response.Write(fi.Length);}
HtmlEncode:
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/html";var csCode = "var list = new List<T>()";// 把 < > 等特殊字符转换为 HTML 转义字符var encodeCsCode = context.Server.HtmlEncode(csCode);context.Response.Write(encodeCsCode);}
HtmlEncode 的效果: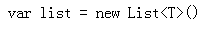
HtmlDecode:
var encoded = "var list = new List<T>();";var source = context.Server.HtmlDecode(encoded);
UrlEncode:
“香香”被 URL encode 为 “%E9%A6%99%E9%A6%99”
- URL 表示字符序列而不是八位字节序列。这是因为 URL 可能通过非计算机网络传输,例如被打印在纸上、通过收音机播放
- 将包含 non-ASCII 字符的原始序列转换为 ASCII 字符序列
输出图片
HttpHandler 是对请求的响应,既可以输出 HTML 内容,也可以输出图片、输出文件供下载。
注:
- 永远不要使用中文文件名
- 再次强调,浏览器不知道服务器上是有原始图片文件还是动态生成的图片
输出已有图片:
public void ProcessRequest(HttpContext context){// image/gif image/pngcontext.Response.ContentType = "image/jpeg";var filePath = context.Server.MapPath("~/hct.jpg");// 浏览器不知道服务器上有 htc.jpg 存在// 浏览器只发请求,接收请求,别的一概不知using (Stream inStream = File.OpenRead(filePath)){inStream.CopyTo(context.Response.OutputStream);}}
动态生成字符串图片:
public void ProcessRequest(HttpContext context){context.Response.ContentType = "image/jpeg";var printStr = context.Request["string"];using (var bmp = new Bitmap(300, 300))// 创建一个尺寸为 300*300 的内存图片using (var g = Graphics.FromImage(bmp))// 得到图片的画布using (var font = new Font(FontFamily.GenericSerif, 30)){// 设置背景为白色g.Clear(Color.White);g.DrawString(printStr, font, Brushes.Red, 0, 0);g.DrawEllipse(Pens.Blue, 100, 100, 100, 100);// 图片保存到输出流bmp.Save(context.Response.OutputStream, ImageFormat.Jpeg);}}
图片中显式访问者浏览器信息
public void ProcessRequest(HttpContext context){context.Response.ContentType = "image/jpeg";using (var bmp = new Bitmap(500, 200))using (var g = Graphics.FromImage(bmp))using (var font = new Font(FontFamily.GenericSerif, 20)){var request = context.Request;g.Clear(Color.White);g.DrawString("IP:" + request.UserHostAddress, font, Brushes.DeepSkyBlue, 0, 0);g.DrawString("浏览器:" + request.Browser.Browser + request.Browser.Version, font, Brushes.DeepSkyBlue, 0, 40);g.DrawString("操作系统:" + request.Browser.Platform, font, Brushes.DeepSkyBlue, 0, 80);bmp.Save(context.Response.OutputStream, ImageFormat.Jpeg);}}

动态生成恶搞图片
public void ProcessRequest(HttpContext context){context.Response.ContentType = "image/jpeg";var name = context.Request["Name"];var imgPath = context.Server.MapPath("~/PaoNiuZheng.jpg");using (Image bmp = Image.FromFile(imgPath))using (var g = Graphics.FromImage(bmp))using (var font1 = new Font(FontFamily.GenericSerif, 12))using (var font2 = new Font(FontFamily.GenericSerif, 5)){{g.DrawString(name, font1, Brushes.Black, 125, 220);g.DrawString(name, font2, Brushes.Black, 310, 50);bmp.Save(context.Response.OutputStream, ImageFormat.Jpeg);}}}

生成验证码
参考 SOF,写了个生成真随机验证码,后续可以添加些麻子点点。
真随机码性能有点低,如果追求性能可以参考这个答案。
public void ProcessRequest(HttpContext context){context.Response.ContentType = "image/jpeg";using (var bmp = new Bitmap(200, 100))using (var g = Graphics.FromImage(bmp))using (var font = new Font(FontFamily.GenericSerif, 10)){var random = TrueRandomString(4);g.Clear(Color.White);g.DrawString(random,font,Brushes.CadetBlue,0,0);bmp.Save(context.Response.OutputStream,ImageFormat.Jpeg);}}static string TrueRandomString(int length){//const string valid = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890";const string validChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";var res = new StringBuilder();using (var rng = new RNGCryptoServiceProvider()){byte[] uintBuffer = new byte[sizeof(uint)];while (length-- > 0){rng.GetBytes(uintBuffer);// 利用随机的字节数组生成一个 uint 数字var num = BitConverter.ToUInt32(uintBuffer, 0);// num 对有效字符长度取模,得到一个有效字符res.Append(validChars[(int)(num % (uint)validChars.Length)]);}}return res.ToString();}

如果对随机数有兴趣,请参阅我的另一篇文章 Random 细节
文件下载
增加报文头告诉浏览器返回的内容是“附件形式”,要给用户保存。
context.Response.AddHeader("Content-Disposition","attachment;filename=" + context.Server.UrlEncode("用户数据.txt"));
对于“.ashx”右键另存为其实还是浏览器向服务器发 Http 请求,然后把服务器运行后返回的 Http 报文体保存到文件中。不会把 ashx 的源代码下载下来。
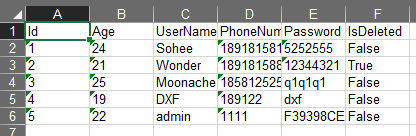
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";context.Response.AddHeader("Content-Disposition","attachment;filename=" + context.Server.UrlEncode("用户数据.txt"));using (var dt = SqlHelper.ExecuteQuery("SELECT * FROM T_Users")){foreach (DataRow row in dt.Rows){context.Response.Write("Name:" + row["UserName"] + " Age:" + row["Age"] + "\n");}}}
服务器返回报文头里面多了 Content-Disposition:
导出数据生成 Excel 供下载
NPOI 太丑了,下面使用 Aspose.Cells。
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";context.Response.AddHeader("Content-Disposition","attachment;filename=" + context.Server.UrlEncode("用户数据.xlsx"));using (var dt = SqlHelper.ExecuteQuery("SELECT * FROM T_Users")){var workbook = new Workbook();var sheet = workbook.Worksheets[0];// Headerfor (var i = 0; i < dt.Columns.Count; i++){sheet.Cells[0, i].PutValue(dt.Columns[i].ColumnName);}// Contentfor (var i = 0; i < dt.Rows.Count; i++){for (var j = 0; j < dt.Columns.Count; j++){sheet.Cells[i + 1, j].PutValue(dt.Rows[i][j].ToString());}}workbook.Save(context.Response.OutputStream,SaveFormat.Xlsx);}}
提取码下载图片
输入正确提取码下载图片,否则提示“提取码错误”。
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";var fetchCode = context.Request["fetch"];if (fetchCode == null || fetchCode != "hct"){context.Response.Write("提取码错误");return;}context.Response.ContentType = "image/jpeg";context.Response.AddHeader("Content-Disposition","attachment;filename=" + context.Server.UrlEncode("hct.jpeg"));var filePath = context.Server.MapPath("~/hct.jpg");using (Stream inStream = File.OpenRead(filePath)){inStream.CopyTo(context.Response.OutputStream);}}
文件上传
进行文件上传,需要采用 method=”post”,并且设定 enctype=”multipart/form-data”。
文件不可能变成字符串在地址栏中提交(GET)。
报文里不知道具体类型的文件的 ContentType 都是 application/octet-stream。
上传图片示例:
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";// 根据 input 的 name 属性获取上传的文件HttpPostedFile file1 = context.Request.Files["file1"];file1.SaveAs(context.Server.MapPath("~/upload/" + file1.FileName));context.Response.Write(file1.FileName);}
设置过 multipart 后,上传文件的报文格式变了。
不难发现 HttpPostedFile.FileName 也是浏览器提交给服务器的。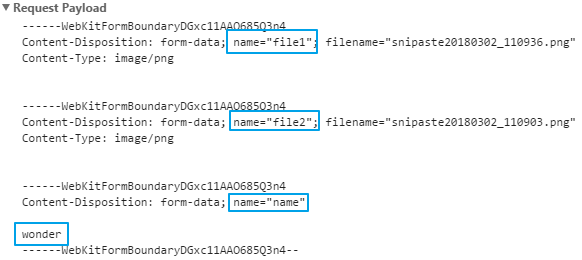
对上传文件进行限制
将用户上传的图片保存到网站的 upload 目录,检查文件大小不能大于1MB(避免撑爆服务器),不能是 jpg、gif、png 之外的图片。
Q:可以用 Request 中的 ContentType 来判断文件类型吗?
A:不能,牢记 Request 是可以伪造的。
下面使用了 FileName 来进行类型判断,但其实这个也能伪造。
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";HttpPostedFile file1 = context.Request.Files["file1"];if (file1.ContentLength > 1024 * 1024){context.Response.Write("图片不能超过 1 MB");return;}var fileExt = Path.GetExtension(file1.FileName);if (fileExt != ".jpg" && fileExt != ".gif" && fileExt != ".png"){context.Response.Write("文件类型不允许");return;}file1.SaveAs(context.Server.MapPath("~/upload/" + file1.FileName));context.Response.Write("上传成功");}
图片水印
通过 file.InputStream 获得上传图片的文件流,并在图片上打印水印。
文件不落地原则:用户上传的文件尽量不保存到本地,能用流操作就用流。可以避免服务器撑爆、非法文件造成安全性问题。
像我之前在某个项目里面接收 Excel 文件后,存储在服务器才开始分析的做法就是不提倡的。
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/plain";HttpPostedFile file1 = context.Request.Files["file1"];if (file1.ContentLength > 1024 * 1024){context.Response.Write("图片不能超过 1 MB");return;}var fileExt = Path.GetExtension(file1.FileName);if (fileExt != ".jpg" && fileExt != ".gif" && fileExt != ".png"){context.Response.Write("文件类型不允许");return;}// 文件不落地原则:用户上传的文件尽量不保存到本地// 可以避免服务器撑爆、非法文件造成安全性问题using (Image img = Image.FromStream(file1.InputStream)){using (Graphics g = Graphics.FromImage(img))using (var font = new Font(FontFamily.GenericSerif, 20)){g.DrawString("Wonder",font,Brushes.SteelBlue,0,0);}img.Save(context.Response.OutputStream,img.RawFormat);}}

WebExcel
通过 Web 展示上传的 Excel。
下面代码只做演示,实际情况需检查上传文件类型并考虑 Excel 版本兼容问题。
public void ProcessRequest(HttpContext context){context.Response.ContentType = "text/html";var writeSb = new StringBuilder();writeSb.Append("<html><head><title>ExcelWeb</title>");writeSb.Append("<style>table{border-collapse: collapse;}table, th, td {border: 1px solid #D4D4D4;}</style></head>");writeSb.Append("<body>");var file1 = context.Request.Files["file1"];var workbook = new Workbook(file1.InputStream);var sheet = workbook.Worksheets[0];writeSb.Append("<h1>" + sheet.Name + "</h1>");writeSb.Append("<table>");foreach (Row row in sheet.Cells.Rows){writeSb.Append("<tr>");for (var i = sheet.Cells.MinColumn; i < sheet.Cells.MaxColumn; i++){writeSb.Append("<td>" + row[i].StringValue + "</td>");}writeSb.Append("</tr>");}writeSb.Append("</table></body></html>");context.Response.Write(writeSb.ToString());}

若有收获,就点个赞吧
0 人点赞
