2018年,曾小满的盒子个人数据整理过程记录。
导出数据
通过在MySQL数据的库建立视图,我把的我的2018年个人数据导出成了一份Excel格式的文件
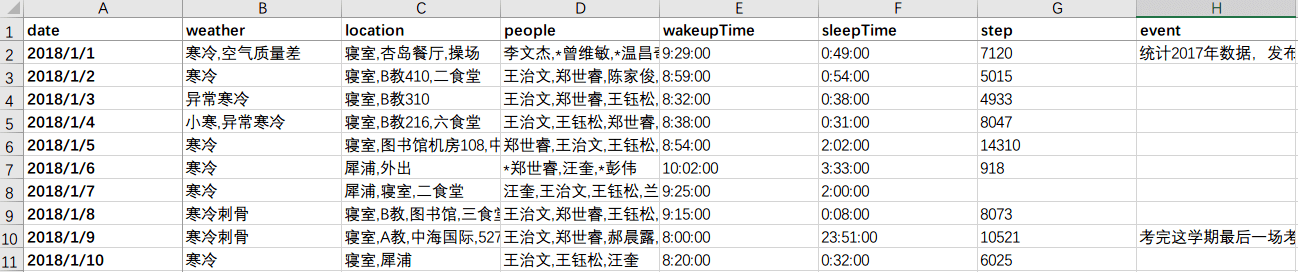

这张Excel表格以行的形式记录了我的每一天,以列记录了每一天具体事项的相关记录。
表中有如下字段:
date 日期 weather 天气 location 地点 people 人物 wakeupTime 起床时间 sleepTime 睡觉时间 step 步数 event 事件 mood 心情 movement 常规活动 weight 体重 food 食物
为了方便后续步骤的使用,我把Excel文件又导出为了纯文本TXT格式。

哈哈,一年的生活也就在这143kb中。
数据分项
处理编码问题
这次打算通过Shell来处理这批数据,就搬出了WIN10的子系统Ubutu,好处是不用开虚拟机还可以与Winodws系统共享同一空间的文件。
进入子系统后一路cd到目标文件夹:
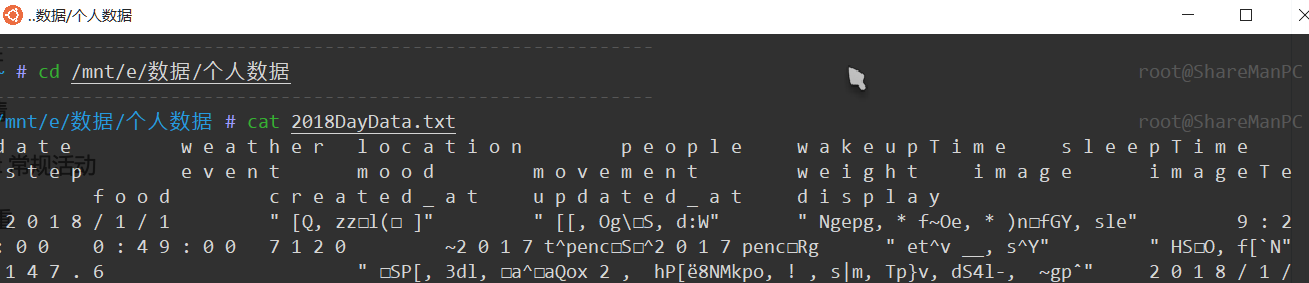
通过 cat命令 查看下这份文件在Shell环境下是否能够正确打开,果不其然是乱码,这是由于EXCEL导出默认编码格式和BOM头的原因导致的。
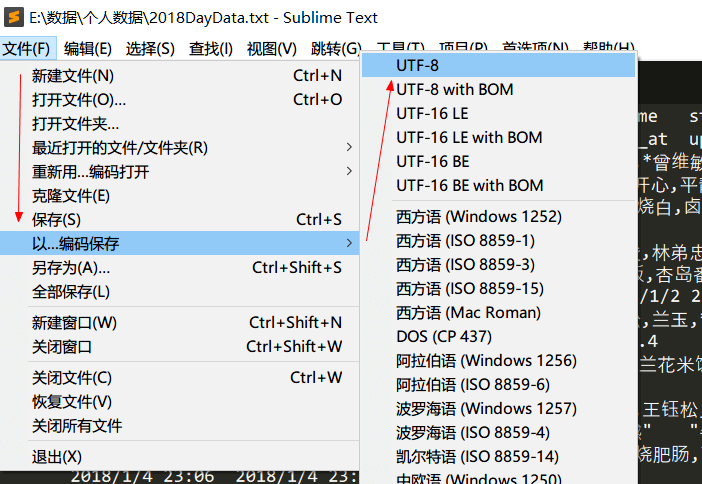
出现这样的情况我们只需要重新保存为UTF-8编码格式即可。
接下来,我们对数据进行分表存储,方便后面针对不同的字段进行数据处理。
###- 数据分项处理
cat 2018DayData.txt| awk -F ' ' '{print $1"\t"$2}'| sed '1d'> 2018DayData_wather.txt# 管道1 以制表符分割 输出第一列和第二列的内容以制表符分割# 管道2 通过sed命令删除第一行表头内容# 输出 weather列数据到当前文件夹你
如法炮制,我们将后面几项数据列(字段)也按照这种方式输出成单独的文件。
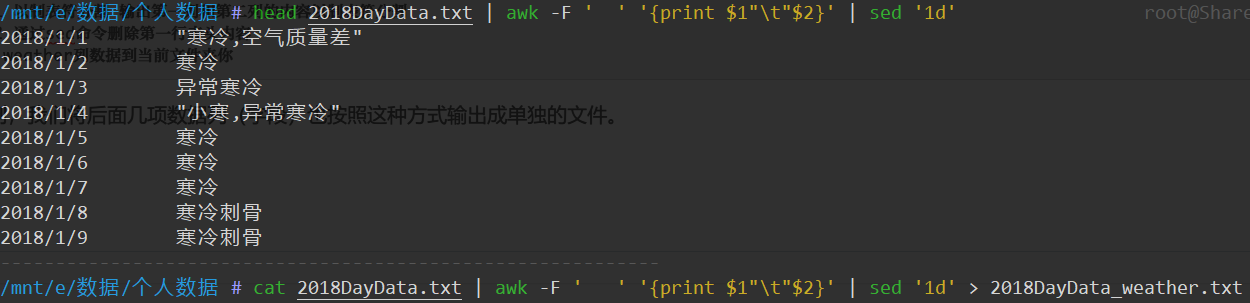
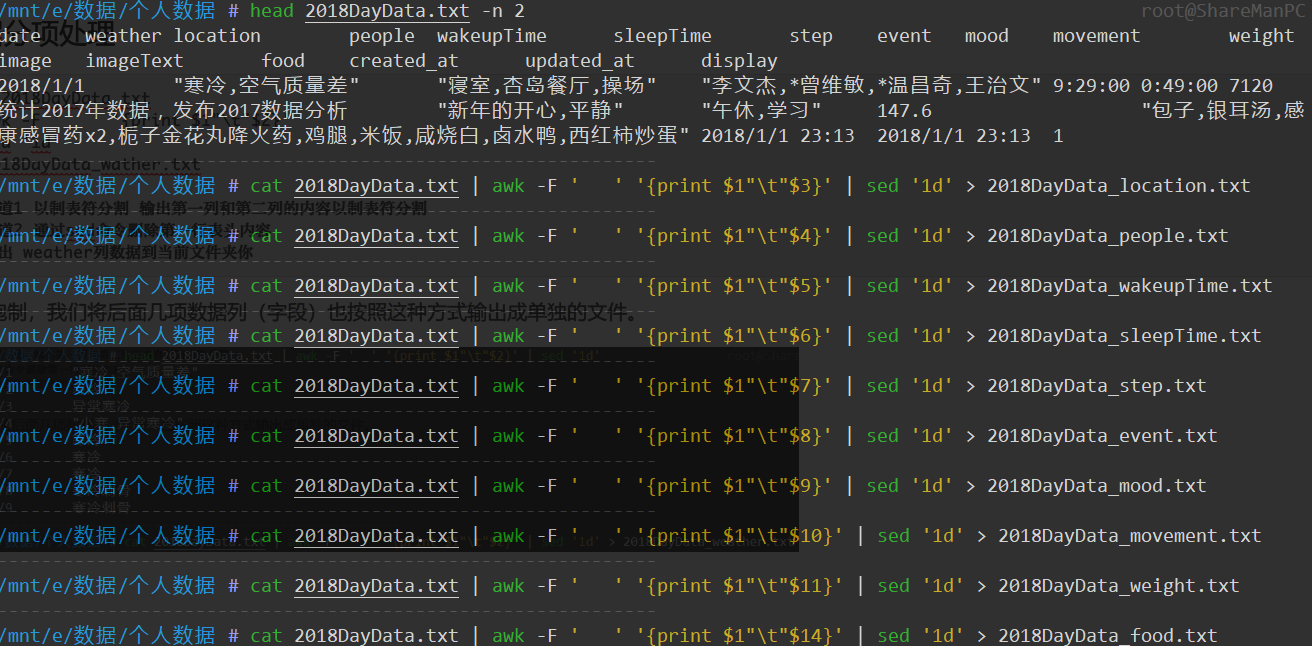
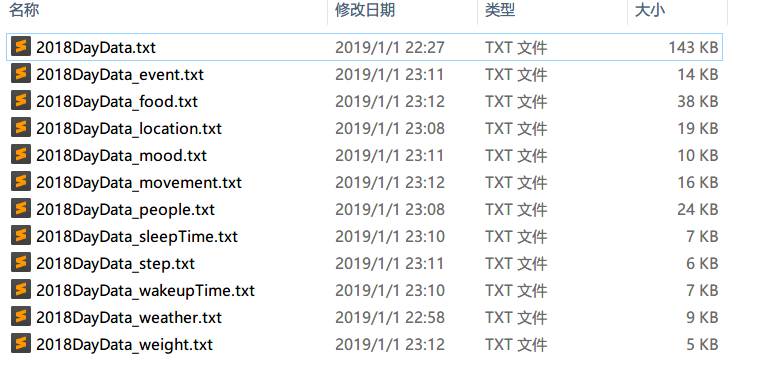
最终我们就得到了这样几份数据文件。
单项数据处理
食物数据
首先我想处理的是与食物相关的数据,毕竟食物给我提供每一天的能量。
以下是食物数据文件 “2018DayData_food.txt” 的基本格式:

食物Wordcount:
通过WordCount的步骤可以了解我每一项食物在我今年记录中的出现频次。
cat 2018DayData_food.txt| awk -F ' ' '{print $2}'| sed 's|[" ]||g'| sed 's|,|\n|g'| sort -k 1| uniq -c| awk '{print $2"\t"$1}'| sort -k 2 -nr> output/food_wordcount.txt# 管道1 awk命令 只取第二列数据列# 管道2 sed命令 全局替换删除空格和"号# 管道3 sed命令 全局替换,为回车分行,让每一个食物名称单独占据一行以便后续步骤操作# 管道4 sort命令 -k(key)参数用于指定按照第1列排序(虽然这里只有一列)# 管道5 uniq命令 -c(count)在每列旁边显示该行重复出现的次数# 管道6 awk命令 自定义uniq命令处理后的行数据显示形式(食物名称在前,频度在后)# 管道7 sort命令 -k参数用于按照第二列食物频度进行排序;-n是按照数字大小排序;-r是以相反顺序排
wordCount得到如下格式结果:
米饭 236柠檬水 95包子 60牛肉 51土豆 48酸奶 42酱肉包 42顺旺基 39苏打饼干 38银耳汤 35
地点数据
地点WordCount,如法炮制,细节不再详述。
cat 2018DayData_site.txt| awk -F ' ' '{print $2}'| sed 's|[" ]||g'| sed 's|,|\n|g'| sort -k 1| uniq -c| awk '{print $2"\t"$1}'| sort -k 2 -nr> output/food_wordcount.txt中洲锦城湖岸 189天府新谷 104寝室 99桂溪生态公园 55C教 43健身房 37家 35环球中心 31六食堂 27航天城上城 22
人物数据
地点WordCount,如法炮制,细节不再详述。
cat 2018DayData_people.txt| awk -F ' ' '{print $2}'| sed 's|[" ]||g'| sed 's|,|\n|g'| sort -k 1| uniq -c| awk '{print $2"\t"$1}'| sort -k 2 -nr> output/people_wordcount.txt
wordcount结果如下:
王治文 277*郑世睿 143杨坤 95王钰松 94郑世睿 85*曾钰杰 75兰玉 75*马洪俊 64*杨坤 42胡鋼 39
*号代表没有见面但是通过网络或电话进行较长时间沟通和通讯过。
周期运动
地点WordCount,如法炮制,细节不再详述。
cat 2018DayData_people.txt| awk -F ' ' '{print $2}'| sed 's|[" ]||g'| sed 's|,|\n|g'| sort -k 1| uniq -c| awk '{print $2"\t"$1}'| sort -k 2 -nr> output/people_wordcount.txt
wordcount结果如下:
午休 301写代码 225学习 118工作 99外出 87运动 85跑步 84休息 72骑车 69健走 44
步数数据
通过EXCEL中的AVERAGE、MAX、MIN函数可以找到三项数据:
平均每日行走步数 8803.51步数最多的一天数量 24223步数最少的一天数量 266
通过数据透视图可以看到每个月的总步数,通过折线图可以将全年行走步数的频率绘制出来:
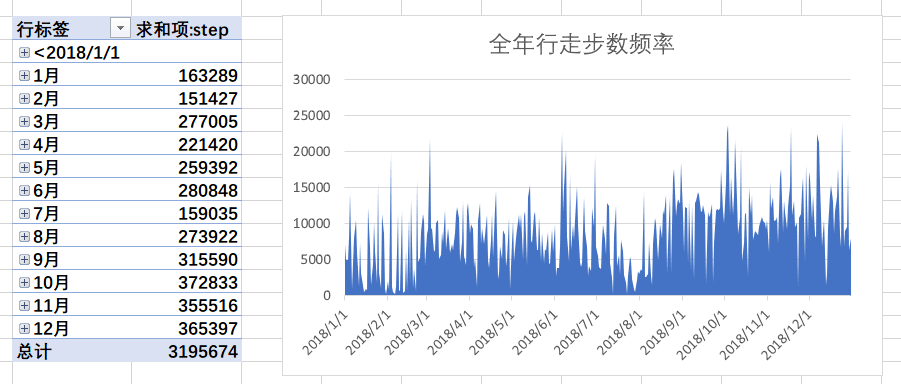
体重数据
因为不是每一天都有条件称体重,我将空的体重数据进行剔除,用Excel的定位查找功能很容易剔除这部分空数据。
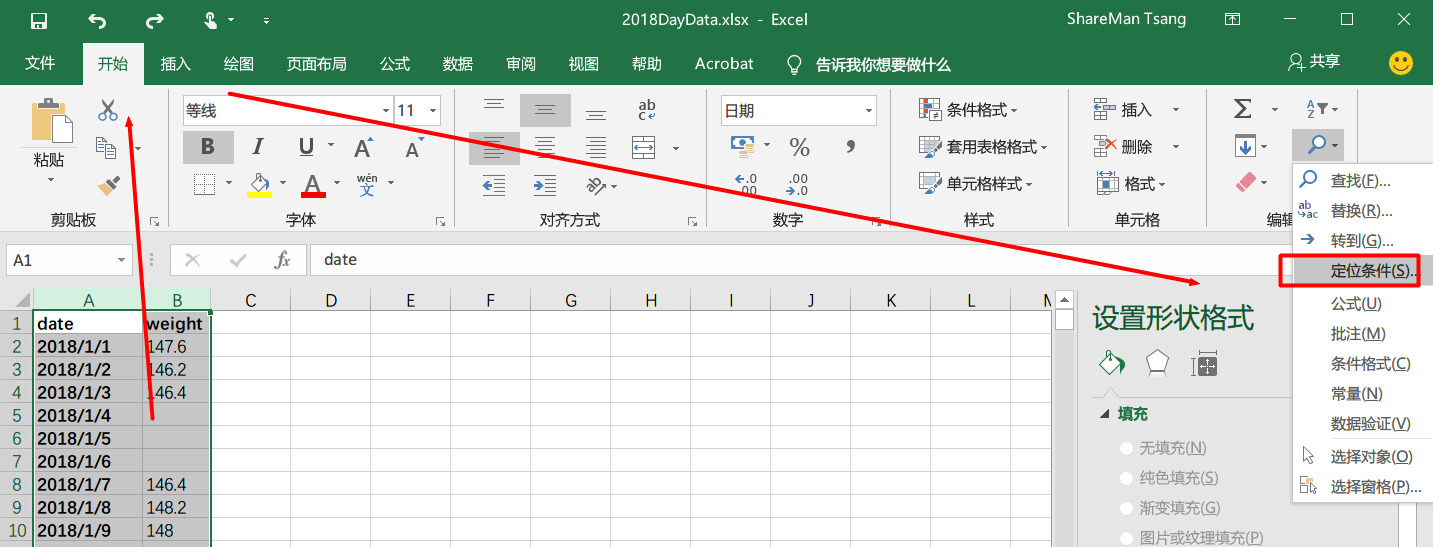
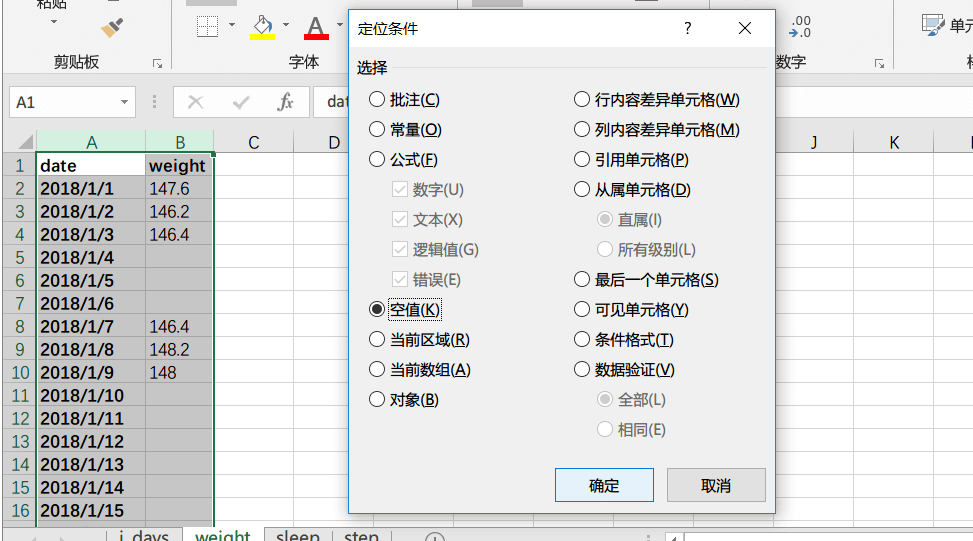
再用右键在弹出的菜单中选择删除,删除整行。
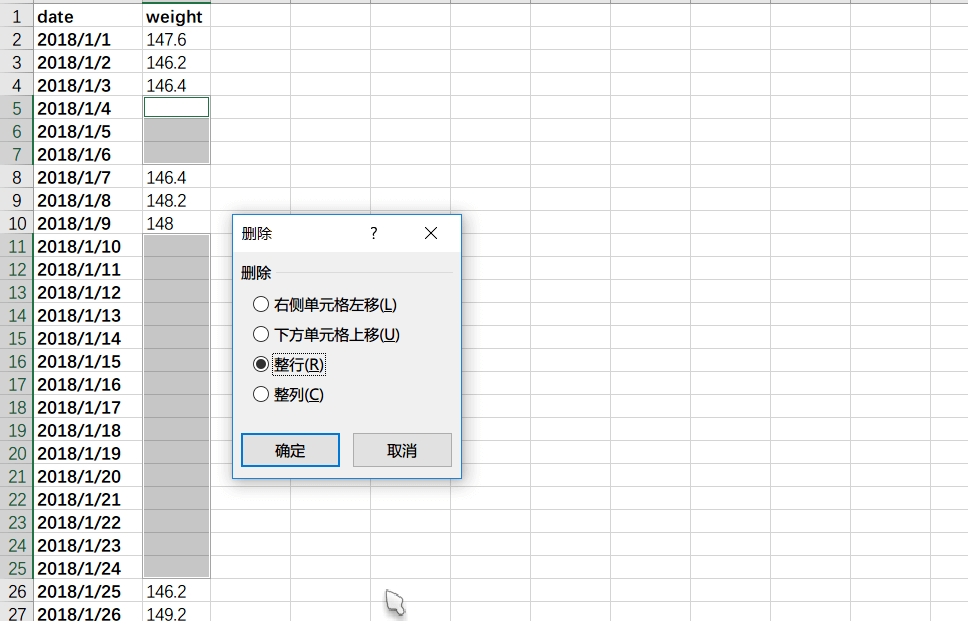
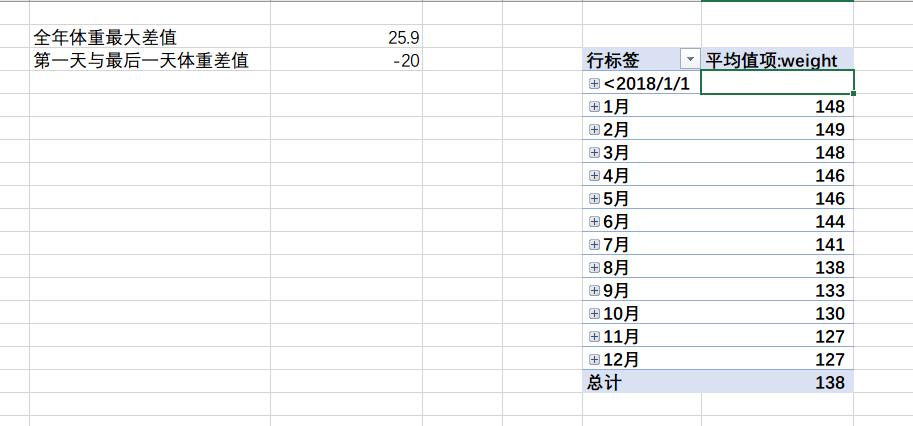
接下来就按照我的意向来做最激动人心的计算:
全年体重最大差值 25.9第一天与最后一天体重差值 -20
睡眠数据
睡眠数据我借助Excel来处理:
我想统计起床和入睡时间,先把时间数据进行格式处理,通过设置自定义单元格格式只保留h字符,即小时。
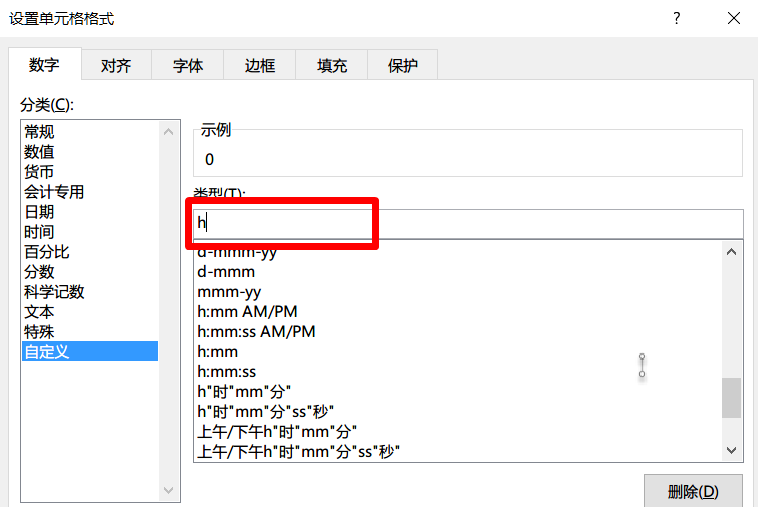
处理后形成如下数据格式:
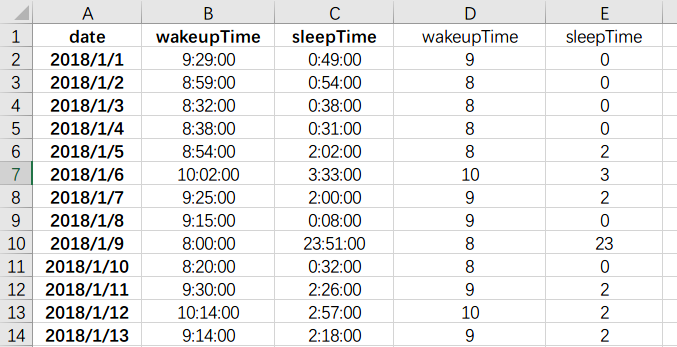
接下来对起床时间和睡眠时间做直方图用以显示数据出现频次:
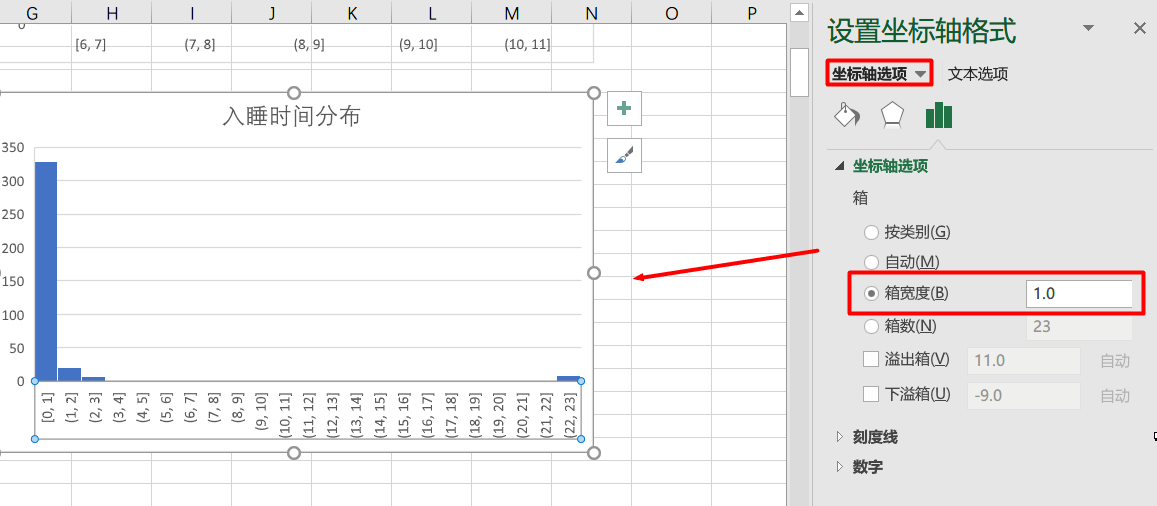
通过调整坐标轴选项设定箱宽度为1,这样就能直观地看到以每个小时为划分的入睡时间和起床时间的图表。
情绪数据
情绪WordCount,如法炮制,细节不再详述。
cat 2018DayData_mood.txt| awk -F ' ' '{print $2}'| sed 's|[" ]||g'| sed 's|,|\n|g'| sort -k 1| uniq -c| awk '{print $2"\t"$1}'| sort -k 2 -nr> output/mood_wordcount.txt
wordcount结果如下:
平静 310开心 34轻松 31烦躁 29郁闷 11焦虑 10激动 9难过 7难受 7纠结 7
体感数据
体感WordCount,如法炮制,细节不再详述。
cat 2018DayData_weather.txt| awk -F ' ' '{print $2}'| sed 's|[" ]||g'| sed 's|,|\n|g'| sort -k 1| uniq -c| awk '{print $2"\t"$1}'| sort -k 2 -nr> output/mood_weather.txt
wordcount结果如下:
寒冷 164炎热 32热 26凉爽 26小雨 19闷热 16湿热 16下雨 16中雨 7阴 6

若有收获,就点个赞吧
0 人点赞
