
记录一次处理数据处理的过程,涉及LINUX操作系统及相关指令以及Hadoop。
任务需求
数据需求
需要以下四个方面的数据:
学生成绩
A、以学生为单位:计算每个学生总的平均分(按年限分)
图书馆数据(按借阅为准)
A、以学生为单位:计算每个学生借阅总数 (按年限分)
B、以学生为单位:计算每个学生借阅类型ABCD(按年限分)
C、只统计学生借阅次数,忽略学生还书数据
消费数据
A、以学生为单位:消费总额(按年限分)
B、删除学生充值记录
门禁数据
A、以学生为单位:9点后进校门次数,11点进校门(按年限分)
输出格式
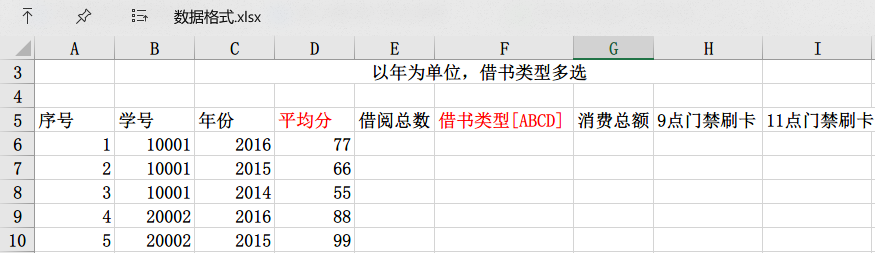
工作目录
.├── Bill.sql├── BookRecord.sql├── Grade.tsv├── Gurad.sql├── OracleSync.sql├── output (用于输出清洗的格式数据)│ ├── require (用于输出目标需求格式数据)├── Result.tsv├── Student├── 书目数据│ ├── 2005.1.1-2009.12.31.xls│ ├── 2010.1.1-2012.12.31书目数据.xls│ ├── 2013.1.1-2014.12.31书目数据.xls│ ├── 2015.1.1-2017.3.15书目数据.xls│ ├── bookIndex1.txt│ ├── bookIndex2.txt│ ├── bookIndex3.txt│ └── bookIndex4.txt├── 原始数据│ ├── db2017-03-14.rar│ └── 书目数据.rar├── 备份数据│ ├── Bill - 副本.sql│ ├── Book - 副本.sql│ ├── Grade - 副本.tsv│ ├── Gurad - 副本.sql│ ├── OracleSync - 副本.sql│ └── Result - 副本.tsv├── 数据格式.xlsx└── 数据需求.txt
清洗数据格式
通过清洗数据得到以空格为分隔符,以行为单位,以列为类别的数据文件。
姓名学号数据
源文件: 未直接给出,从图书馆借书数据中提取
查看了给出的几份文件,并没有直接给出学生姓名学号文件,但在图书馆的借阅记录文件中有相关的数据。
因此,我们可以先从这里输出一份学生姓名与学号对应的数据表,要注意的是需要对结果进行去重,因为一个学生可能存在多次借阅记录。
清洗命令如下:取学生姓名学号对应数据
cat BookRecord.sql| awk -F ', ' '{print $2"\t"$1}'| sed "s|INSERT INTO V_TSG_JYLOG VALUES (||g"| sed "s|'||g"> output/Student_temp.txt| sort| uniq> output/Student.txt# 第一根管道 awk命令 通过','(加空格)按行分割数据,取位置1和2对应的学生姓名和学生学号,输出时以制表符分隔# 第二根管道 sed命令 通过正则全局替换残留的SQL语句字段“INSERT INTO V_TSG_JYLOG VALUES (”# 第三根管道 sed命令 通过正则全局删除'符号# 输出重定向 把学生信息存储到output文件夹下的Student_temp.txt文件中# 第四根管道 对Student_temp.txt进行排序(为下一步去重做准备)# 第五根管道 将排序后的结果进行取唯一值操作# 输出重定向 输出排序和去重后的学生姓名学号对应数据到output文件夹下的Student.txt文件中
清洗结果 ( Student.txt ):
# 按列序对应分别为:(以制表符分割)# $1:学生学号 / $2:学生姓名163020417 蒋X刚163020419 黄X旭163020421 罗X武163020423 杨X林163020425 唐X雯
图书馆书目数据
源文件:多份同样格式的XLS文件
给出的XLS文件因为编码原因在linux操作系统中不能直接使用,我这里用了一个比较笨的办法来处理。
先用Excel打开,再保存为UTF-8格式的txt文件,这一步骤操作完成后文件目录如下图:
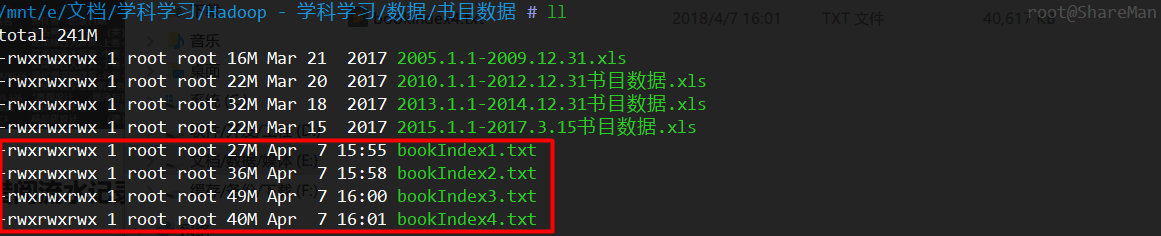
红色框起来的是按照时间顺序新生成的四份txt文件,内容格式如下:
接下来用如下命令来合并四分文件并进行清洗:
cat bookIndex1.txt| sed '1d'| awk -F '\t' '{print $2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10}'> ../output/BookIndex.txtcat bookIndex2.txt | sed '1d' | awk -F '\t' '{print $2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10}' >> ../output/BookIndex.txtcat bookIndex3.txt | sed '1d' | awk -F '\t' '{print $2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10}' >> ../output/BookIndex.txtcat bookIndex4.txt | sed '1d' | awk -F '\t' '{print $2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10}' >> ../output/BookIndex.txt# 第一根管道 sed命令 删除第一行(无用的表头)# 第二根管道 awk命令 按制表符分割输出$2-$12的文件,不输出$1是因为序号无效# 输出重定向 >>追加输出四份书目索引文件到同一份名为BookIndex.txt文件中
清洗结果 ( BookIndex.txt ):
# 按列序对应分别为:# $1:索书号 / $2:书名 / $3:作者 / $4:出版日期 / $5:标准编码 / $6:书籍编号 / $7:单价 / $8:出版者 / $9:借阅次数F713.50/WBC 营销:市场营销操作1001法 王必成主编 2004 7-5078-2320-2 0002102 54 中国国际广播出版社 0B848.4/LH 跟亿万富翁站在一起 鹿荷编著 2004 7-80109-995-8 0002103 13 中央编译出版社 0F275.3/KPN 质量成本原理:原理、实施和应用 (美) Jack Campanella编著 2004 7-111-14776-6 0002104 28 机械工业出版社 0F740.45/DYL 外贸会计习题与解答 丁元霖主编 2004 7-5429-1292-5 0002105 17.5 立信会计出版社 0F270/CQM 股票期权理论与实务 "蔡启明, 钱焱著" 2004 7-5429-1230-5 0002106 17.5 立信会计出版社 0F590/W388 旅游学导论 "王晓云, 张帆编著" 2004 7-5429-1199-6 0002107 22.6 立信会计出版社 0
图书馆借阅数据
源文件: BookRecord.sql
文件的SQL语句格式如下 :
INSERT INTO V_TSG_JYLOG VALUES ('XX东', '153100476', '504948', '还书,保留本', '0791593', '0791593', '2016-07-06 08:28:26', '威尼斯商人');INSERT INTO V_TSG_JYLOG VALUES ('XX敏', '153100340', '507522', '还书', '0791600', '0791600', '2016-06-01 18:53:52', '黑塞诗选');INSERT INTO V_TSG_JYLOG VALUES ('XX成', '153020068', '508306', '还书', '0791613', '0791613', '2016-11-29 10:03:01', '未拆的家书');INSERT INTO V_TSG_JYLOG VALUES ('XX晴', '163020432', '508306', '还书', '0791614', '0791614', '2016-12-17 19:30:55', '未拆的家书');
清洗命令:取借阅记录
cat BookRecord.sql| sed "s|INSERT INTO V_TSG_JYLOG VALUES (||g"| sed "s|[');]||g"| awk -F ', ' '{print $1"\t"$2"\t"$3"\t"$4"\t"$5"\t"$7"\t"$8}'> output/BookRecord.txt# 第一根管道 sed命令 替换残留的SQL语句字段“INSERT INTO V_TSG_JYLOG VALUES (”# 第二根管道 sed命令 通过正则替全局换掉' ) ;这三种字符# 第三根管道 awk命令 以","为分隔符,取$1-$8位置上的数据# 输出重定向 输出清洗后的借阅记录
清洗结果 ( BookRecord.txt ):
# 按列序对应分别为:(以制表符分割)# $1:姓名 / $2:学号 / $3:未知(ZJM) / $4:操作类型 / $5:书籍编号 / $6:借阅时间 / $7:书名刘佳 050132021 6416 借书 0034679 2007-05-09 10:03:02 武则天传苏娟 050132020 6416 借书 0034679 2007-05-09 10:03:02 武则天传李玉 050132019 6416 借书 0034679 2007-05-09 10:03:02 武则天传王都 050132018 6416 借书 0034679 2007-05-09 10:03:02 武则天传吴茂 050132017 6416 借书 0034679 2007-05-09 10:03:02 武则天传
饭卡消费数据
源文件:Bill.sql
文件的SQL语句格式如下:
INSERT INTO YKTYHXFSJZL_NEW VALUES (NULL, NULL, NULL, NULL, NULL, NULL, '000207619', NULL, NULL, NULL, NULL, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);INSERT INTO YKTYHXFSJZL_NEW VALUES (NULL, NULL, NULL, NULL, NULL, NULL, '000207620', NULL, NULL, NULL, NULL, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);INSERT INTO YKTYHXFSJZL_NEW VALUES (77934979, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, '2017/03/09 18:27:29.527', 33, 1, NULL, NULL, NULL, NULL, '94043244', '163110195', '2032', '联网售饭', '0108027');INSERT INTO YKTYHXFSJZL_NEW VALUES (77934980, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, '2017/03/09 18:27:30.670', 244.75, 7, NULL, NULL, NULL, NULL, '94043245', '140330105', '2032', '联网售饭', '0108011');
清洗命令如下:
cat Bill.sql| awk -F ', ' '{print $11"\t"$12"\t"$13"\t"$19"\t"$21}'| sed "s|[']||g"> output/Bill.txt# 第一根管道 awk命令 取以', '(加空格)分隔符分割后位置为7,12,13,18,21的数据,输出时以制表符分割# 第二根管道 sed命令 在每一行中全面替换'符号(替换学号的左右符号)# 输出重定向 把处理后的输出结果输出到output文件夹下的Bill.txt文件中
清洗结果 ( Bill.txt ):
# 按列序对应分别为:(以制表符分割)# $1:消费消费时间 / $2:卡上余额 / $3:交易金额 / $4:学号 / $5:消费类型2016/03/29 12:50:47.453 4.25 2.50 153020240 联网售饭2016/03/29 12:36:13.630 6.75 10 153020240 联网售饭2016/03/29 17:31:42.377 104.25 100 153020240 银行转入2016/04/05 12:11:26.800 6.05 11 153020240 联网售饭2016/04/05 08:15:18.307 17.05 2.50 153020240 联网售饭
学生成绩数据
源文件:Grade.tsv
拿到的这份制表符分割文件用head命令查看了一下,发现中文读不出来,重新存储了一次编码格式化UTF-8可以正常显示中文了。
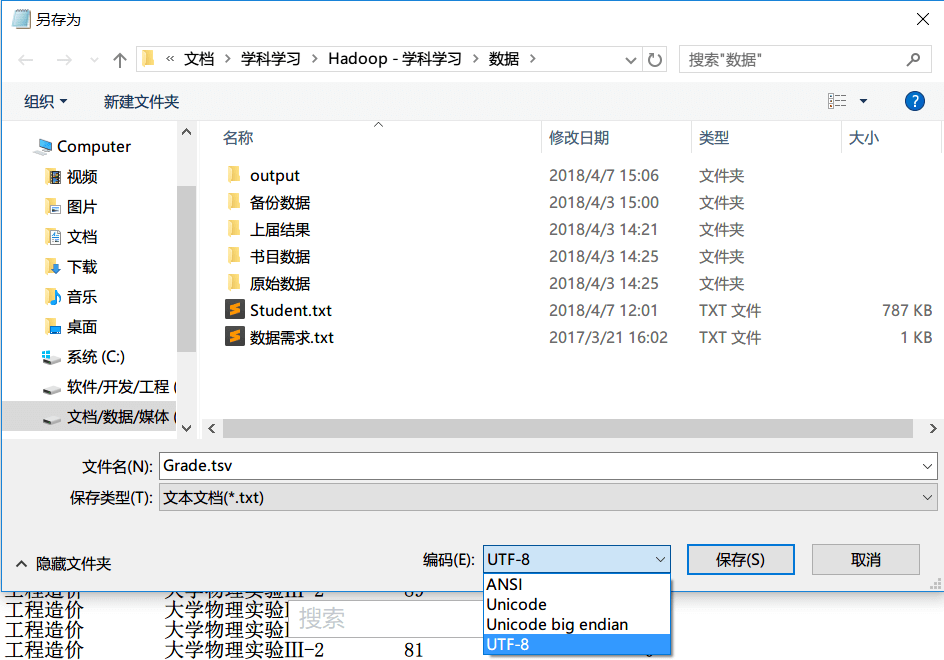
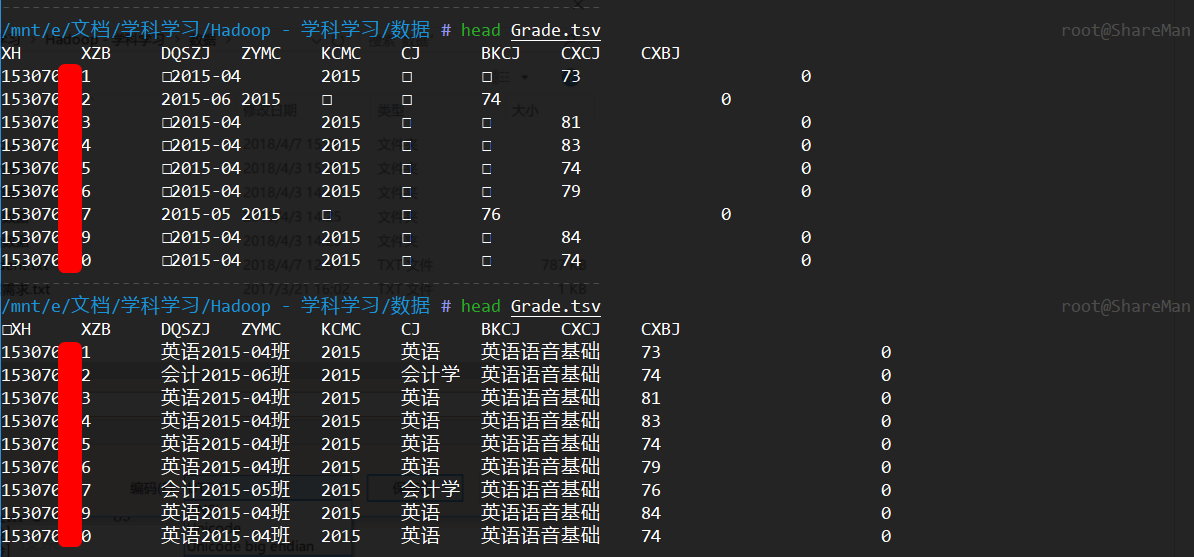
还需要注意:部分课程的名称里面包含空格,如果按空格分割会出现列数多的情况,可以用sed命令再次处理。
清洗命令如下:
cat Grade.tsv| sed '1d'| awk -F '\t' '{print $1"\t"$2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$7"\t"$8"\t"$9}'> output/Grade.txt# 第一根管道 sed命令 d命令用于按行删除内容,1d表示删除掉第一行(表头)# 第二根管道 sed命令 替换课程名称中的空格# 第三根管道 awk命令 同样地,以\t(制表符)为分割符,取$1-$9# 输出重定向命令 输出清洗后的成绩信息
清洗结果 ( Grade.txt ):
# 按列序对应分别为:# $1:学号 / $2:班级 / $3:学年 / $4:专业 / $5:学科名 / $6:正考成绩 / $7:补考成绩130680186 视觉2013-02班 2013 视觉传达设计 商业摄影 75 0130680188 视觉2013-02班 2013 视觉传达设计 商业摄影 67 0130680192 视觉2013-02班 2013 视觉传达设计 商业摄影 76 0154080002 物联网2015-01班 2015 物联网应用技术 物联网概论 80 0154080004 物联网2015-01班 2015 物联网应用技术 物联网概论 87 0154080005 物联网2015-01班 2015 物联网应用技术 物联网概论 87 0154080007 物联网2015-01班 2015 物联网应用技术 物联网概论 86 0154080010 物联网2015-01班 2015 物联网应用技术 物联网概论 67 0
门禁刷卡数据
源文件:Gurad.sql
门禁记录sql文件格式如下:
INSERT INTO MJXXB VALUES ('1001', '1', '控制器06门1', '1', '大门门禁', '20150604', '18:56:02:000');INSERT INTO MJXXB VALUES ('1001', '1', '控制器06门1', '1', '大门门禁', '20150604', '18:56:13:000');INSERT INTO MJXXB VALUES ('1001', '1', '控制器06门1', '1', '大门门禁', '20150604', '19:06:57:000');INSERT INTO MJXXB VALUES ('1001', '1', '控制器06门1', '1', '大门门禁', '20150604', '19:07:15:000');INSERT INTO MJXXB VALUES ('1001', '1', '控制器06门1', '1', '大门门禁', '20150604', '19:20:36:000');
如法炮制,用以下命令清洗:
cat Gurad.sql| sed "s|INSERT INTO MJXXB VALUES (||g"| sed "s|[');]||g"| awk -F ', ' '{print $1"\t"$2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$7}'> output/Gurad.txt# 第一根管道 sed命令 删除SQL语句残留# 第二根管道 sed命令 删除多余符号# 第三根管道 awk命令 以','分割,取$1-$7的数据# 输出重定向命令 输出清洗后的门禁记录数据
清洗结果 ( Gurad.txt ):
# 按列序对应分别为:(以制表符分割)# $1:学号 / $2:设备编号 / $3:设备名称 / $4:设备轮询编号 / $5:刷卡位置 / $6:刷卡日期 / $7:刷卡时间130840171 1 A1 2 宿舍门禁 20150902 22:34:48:000130840171 1 A1 2 宿舍门禁 20150902 22:34:51:000130840171 1 A1 2 宿舍门禁 20150902 22:34:52:000130520103 1 A1 2 宿舍门禁 20150902 22:37:33:000130820119 1 A1 2 宿舍门禁 20150902 22:38:29:000
关联提取数据
数据清洗完成后我们下一步开始提取数据 —— 提取处理需求中所需数据。
这里用到了awk的文件关联操作,过段时间会在其他文章中对awk文件关联操作的详解。
成绩平均分
awk -F '\t' 'NR==FNR{student[$1]=$2}NR!=FNR{if($6>=0){print "Grade\t"student[$1]"\t"$1"\t"$3"\t"$6}}'Student.txt Grade.txt> require/Grade.txt
注意:在做后续 Map Reduce 步骤中出现了数组越界的情况,排查发现是因为数据清洗格式没有统一有的成绩存在空的情况。
数据格式如下:
# 按列序对应分别为:(以制表符分割)# $1:数据类型标识 / $2:姓名 / $3:学号 / $4:年份 / $5:成绩Grade 董文静 140680107 2014 87Grade 宗升正 140680108 2014 72Grade 朱文莉 140680110 2014 86Grade 葛玲玮 140680111 2014 84Grade 刘佳洁 140680114 2014 72
图书借阅
awk -F '\t' 'NR==FNR{bookInfo[$6]=$1}NR!=FNR{print "BookRecord\t"$1"\t"$2"\t"substr(bookInfo[$5],1,1)"\t"$4"\t"substr($6,1,4)}'BookIndex.txt BookRecord.txt> require/BookRecord.txt
数据格式如下:
# 按列序对应分别为:(以制表符分割)# $1:数据类型标识 / $2:姓名 / $3:学号 / $4:图书类型 / $5:操作类型 /$6:年份BookRecord 彭瑶 100410750 I 借书 2012BookRecord 权婷 100410749 I 借书 2012BookRecord 孙彦 100410748 I 借书 2012BookRecord 刘姝娜 100410747 I 借书 2012BookRecord 周忆菲 100410746 I 借书 2012BookRecord 钟疆慧 100410745 I 借书 2012
饭卡消费
awk 'NR==FNR{student[$1]=$2}NR!=FNR{if($5!="NULL"){print "Bill\t"student[$4]"\t"$4"\t"substr($1,1,4)"\t"$3"\t"$5}}'Student.txt Bill.txt> require/Bill.txt
数据类型如下:
# 按列序对应分别为:(以制表符分割)# $1:数据类型标识 / $2:姓名 / $3:学号 / $4:年份 / $5:交易额 / $6:操作类型Bill 张燕芳 153070194 2016 2 联网售饭Bill 何枫玲 163070207 2016 1 联网售饭Bill 163060430 2016 1 联网售饭Bill 潘捷 140920106 2016 3.50 联网售饭Bill 罗蕊 154100051 2016 4 联网售饭
门禁刷卡
awk 'NR==FNR{student[$2]=$1}NR!=FNR{print "Gurad\t"student[$1]"\t"$1"\t"substr($6,1,4)"\t"substr($7,1,2)}'Student.txt Gurad.txt> require/Gurad.txt
数据类型如下:
# 按列序对应分别为:(以制表符分割)# $1:数据类型标识 / $2:姓名 / $3:学号 / $4:年份 / $5:刷卡时间(小时)Gurad 刘畅 120350240 2017 19Gurad 梁潇 120350303 2017 19Gurad 严鉥文 120350307 2017 17Gurad 高子涵 120350329 2017 19Gurad 朱兴奇 120350330 2017 19Gurad 周力君 120930130 2017 19Gurad 黄丹 130110118 2017 19

若有收获,就点个赞吧
0 人点赞
