
学习背景
学习Hadoop的第一节课,老师做了Hadoop的基本介绍后问我们有没有什么疑问。
我提了一个问——“如果我更熟悉其他编程语言,能不能不用写JAVA程序来做相关的Hadoop运算处理”,老师说当然可以。
这周我们刚好学习了Hadoop Streaming,没错,就是它了!
对于能够用其他喜欢的编程语言来与Hadoop并肩我很感兴趣,于是,把Hadoop Straming的学习笔记记录在这里。
基础知识
我在Hadoop官网(链接)上找到了如下介绍:
Hadoop streaming is a utility that comes with the Hadoop distribution. The utility allows you to create and run Map/Reduce jobs with any executable or script as the mapper and/or the reducer.
基本介绍
从介绍中可以得出如下关于 Hadoop Streaming 的信息:
- 它是一个Hadoop的实用工具 =》 它在我们使用Hadoop的过程中做辅助作用
- 它随着Hadoop发布 =》我们不需要去单独下载,只要安装了Hadoop就可以找到Hadoop Streaming
- 它可以提供给我们用其他语言写M/R任务的条件 =》 用它来编写的是处理M/R这部分任务的代码
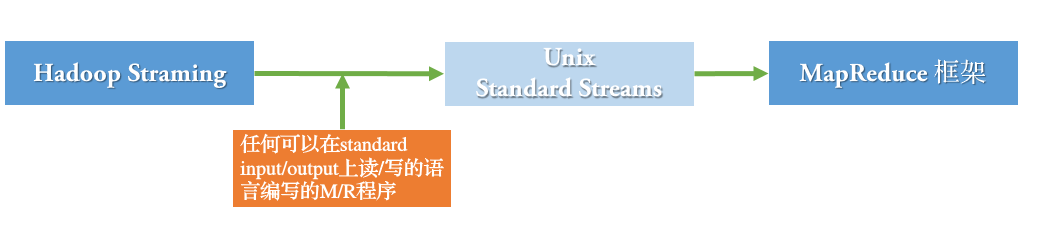
Hadoop Streaming 支持而已在Unix标准流上进行读写操作的所有语言,包括但不限于:
bash shell、php、C/C++、ruby、python
运行指令
$hadoop jar [hadoop-streaming.jar包路径] \-input [指定HDFS中进行输入的路径] \-output [指定HDFS中进行] \-mapper [指定mapper程序路径] \-reducer [指定reducer程序路径] \-file [指定要提交到集群中的文件]
进行实验
假定已经安装好了Hadoop,配置好了Hadoop环境变量,但我不知道Streaming这个包在哪里以及它的命名。
让我来搜索一下它,验证一下是否不需要单独下载streming的jar包。
$find $HADOOP_HOME -name "*streaming*.jar"#下面是搜索结果/usr/lib/hadoop/hadoop-2.8.2/share/hadoop/tools/lib/hadoop-streaming-2.8.2.jar/usr/lib/hadoop/hadoop-2.8.2/share/hadoop/tools/sources/hadoop-streaming-2.8.2-sources.jar/usr/lib/hadoop/hadoop-2.8.2/share/hadoop/tools/sources/hadoop-streaming-2.8.2-test-sources.jar
实验材料
准备一份文本材料
#名称streamingTest.txt 内容如下153020XX3 郭XX 电子商务 杨X153020XX4 苟XX 电子商务 杨X
提交文件到HDFS
$ hdfs dfs -put /input/streamingTest
实验1:Shell wc
目标: 通过 hadoop streaming 来 count 出 streamingTest.txt 文件的行数。
运行指令:
$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.8.2.jar \-input /input/streamingTest \-output /output/streamingTest \-mapper /bin/cat \-reducer /bin/wc \-file streamingTest.txt
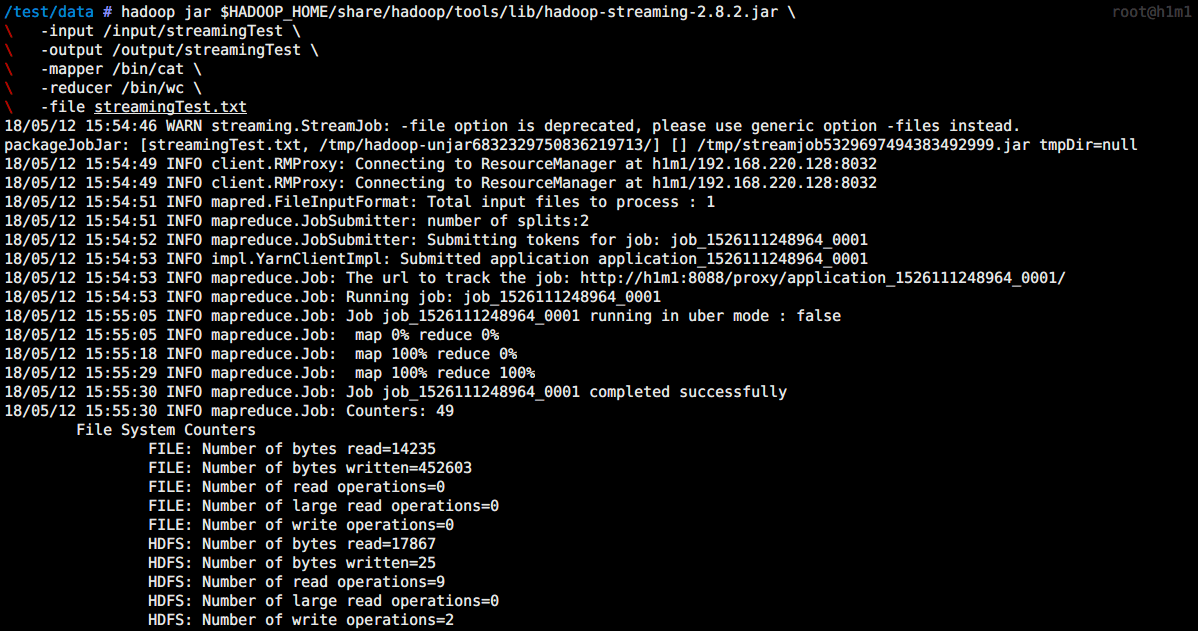
对比结果
$ hdfs dfs -cat /output/streamingTest/part-00000317 1261 13595$ cat streamingTest.txt | wc317 1261 13595
虽然使用hadoop streaming来做一个文件的wc命令有些傻逼,但通过结果的一致性我们可以加深对hadoop streaming运行过程的了解。
接下来我来使用我熟悉的php做个测试。
实验2:PHP wordcount
目标: 通过 hadoop streaming 使用 PHP 语言做 word count,以 streamingTest.txt 文件中用“\t”分割的第一列做key,余下部分做value。
编写PHP Mapper源码(文件名phpMapper.php):
#!/usr/bin/php<?php$input = fopen("php://stdin", "r");$results = array();while ( $line = fgets($input) ){$words = preg_split('/ /', $line, 0, PREG_SPLIT_NO_EMPTY);foreach ($words as $word)$results[] = $word;}fclose($in);foreach ($results as $key => $value){print "$value\t1\n";}
随便输入一段文字来测试一下:

编写PHP Reducer源码(文件名phpReducer.php):
#!/usr/bin/php<?php$input = fopen("php://stdin", "r");$results = array();while ( $line = fgets($input) ){list($key, $value) = preg_split("/\t/", trim($line), 2);$results[$key] += $value;}fclose($input);ksort($results);foreach ($results as $key => $value){print "$key\t$value\n";}
同样地输入一段文字来测试一下:

PHP知识回顾1:PHP脚本传取参数的方法
- web开发中常用 $_GET, $_POST超全局变量里面取参数
- 次之是从$_SERVER[‘argv’]里取通过命令行传入的参数
- 采用标准输入stdin取参数
PHP知识回顾2: PHP在linux操作系统中执行过程 在php脚本所在目录下执行 phpMapper.php。 控制台等待用户通过键盘输入(标准输入)文本,当按下Ctrl + D终止输入,streamingTest.php开始执行真正的业务逻辑,并将执行结果输输出。
运行指令:
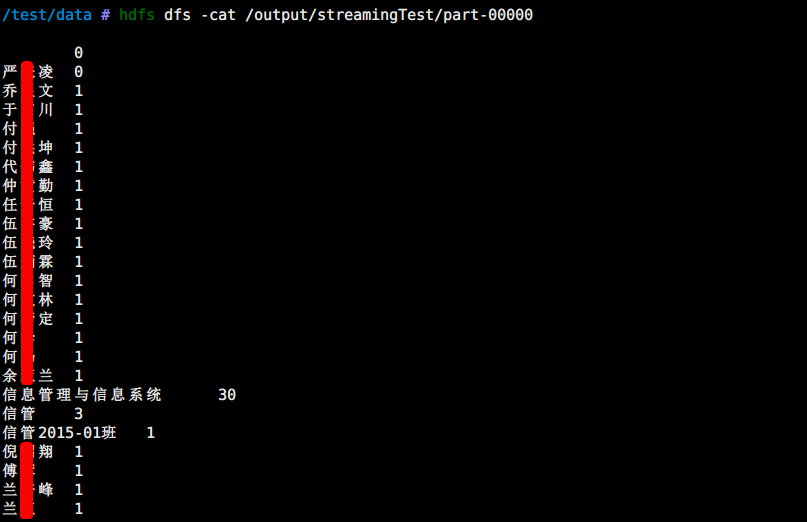
$ hdfs dfs -rm -r /output/streamingTest/$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.8.2.jar \-input /input/streamingTest \-output /output/streamingTest \-mapper /test/data/phpMapper.php \-reducer /test/data/phpReducer.php \-file streamingTest.txt
注意:在指定mapper和reducer的时候必须是绝对地址才能正确执行。否则会提示“Streaming Command Failed!”
输出结果如下:
结语
处理速度就像它的名字Streaming(溪流)一样不快,慢慢流淌,在做较少的数据处理的时候也会显得多此一举。
不过,能通过Streaming用其他语言跑M/R总归是件愉快的事情。

若有收获,就点个赞吧
0 人点赞
