术语
| 名称 | 解释 |
|---|---|
| 数据库 | 是逻辑建模的信息集或数据集。 数据库可以是任何数据的集合,不仅仅是存储在计算机上的数据集合。 |
| 数据库管理系统(DBMS) | 是与数据库交互的计算机程序。 DBMS允许你对数据库的访问,写入数据,运行查询以及执行与数据库管理有关的其他任务。 |
| 关系型数据库管理系统(RDBMS) | 专用于处理关系型数据库中数据的数据库管理系统。 |
尽管数据库管理系统通常被称为“数据库”,但这两个术语并不可以完全互换。
背景
关系型数据库的局限性
从历史上看,关系模型一直是用于管理数据的最广泛使用的方法,并且直到今天许多最受欢迎的数据库管理系统都实现了关系模型。
但是,关系模型存在一些限制,这在某些特定情况下可能是有问题的。
水平扩展难度高
水平扩展(横向扩展)是在现有堆栈中添加更多的计算机以分散负载并允许更多的流量及更快的处理速度。
这通常与垂直扩展形成对比,垂直扩展通常通过添加更多RAM或CPU来升级现有服务器的硬件来实现。
关系型数据库难以水平扩展的原因主要是:关系模型旨在确保一致性。
这意味着查询同一数据库的用户将始终看到最新的数据。如果要在多台计算机上水平扩展关系数据库,则很难确保一致性。
这是因为用户可能会将数据写入某一个节点,而非其他的节点,并且在初始写入节点和其他节点更新数据库变动的这段时间可能存在延迟。
非结构化数据存储难
关系模型旨在管理结构化数据或者与预定义数据类型一致或至少以某种预定方式组织的数据,从而使其易于分类和搜索。
然而,随着1990年代初个人计算的普及和互联网的兴起,非结构化数据(例如邮件,照片,视频等)变得越来越普遍。
随着这些限制变得越来越收缩,开发者开始寻找传统关系数据模型的替代方法,从而导致NoSQL数据库的普及。
与关系数据库相似处
与关系数据库类似,NoSQL 也不适合用作搜索型数据处理。
虽然常见的 NoSQL 数据库,比如 MongoDB 或 Redis 有支持一定程度上的搜索功能,但是它们的搜索均不是用索引来实现的。
因此,当需要快速搜索功能的时候,不管是关系型数据库的 MySQL,Postgres 或是 NoSQL 里的 MongoDB 或 Redis,都不能很好地满足要求。
而像 Lucene,Elastic Search 或卡拉搜索这样的工具,则可以更好地解决搜索需求。如果你需要比较快的文本搜索、文档查询功能。
发展
1998年
“ NoSQL”的概念由 Carlo Strozzi 创造,这是他开发的新的 NoSQL 数据库的名称。之所以选择它,是因为它不使用SQL来管理数据。
有趣的是,Strozzi 的NoSQL 数据库实际上采用了关系模型,这意味着原始的 NoSQL 数据库不符合当代 NoSQL 的定义。
2009年
Johan Oskarsson 组织了一次面向开发人员的聚会后该术语有了新的含义,会议讨论了诸如 Cassandra 和 Voldemort 之类的“开源,分布式和非关系数据库”术语的传播。
奥斯卡森(Oskarsson)将聚会命名为 NOSQL,从那时起,该术语就被用作所有不使用关系模型的数据库的“包罗万象”。
定义
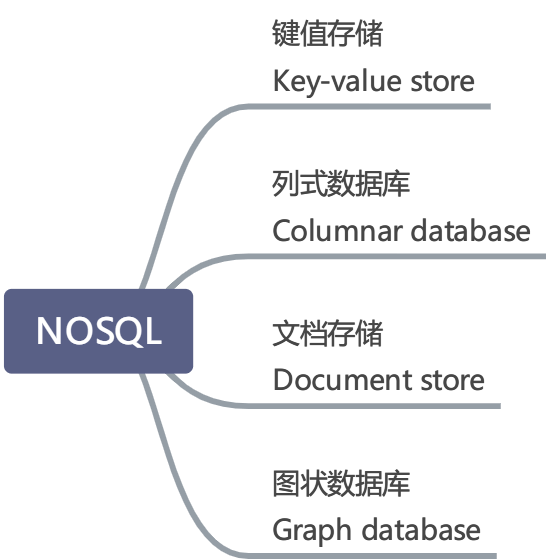
NoSQL 通常指任何不使用关系模型的 DBMS ,因此有几种与 NoSQL 概念相关的操作数据库模型。
模型
下表包括几个此类的数据模型,但请注意,这不是完整的列表:
| 数据库模型 | 实现 |
|---|---|
| 键值存储 Key-value store | Redis, MemcacheDB |
| 列式数据库 Columnar database | Cassandra, Apache HBase |
| 文档存储 Document store | MongoDB, Couchbase |
| 图状数据库 Graph database | OrientDB, Neo4j |
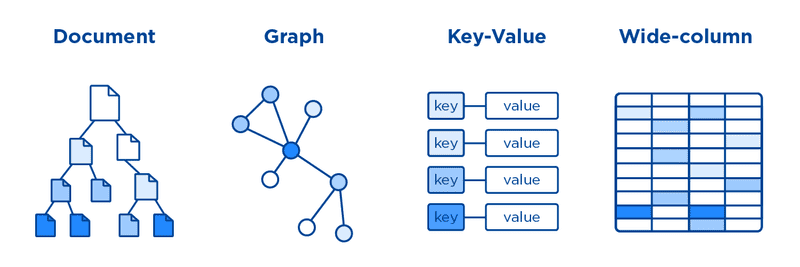
键值数据库
简述
键值数据库(也称为键值存储)通过存储和管理关联的数组来工作。
关联数组,也称为字典或哈希表,由键-值对的集合组成,其中键用作唯一标识符以检索关联值。值可以是任何东西,从简单的对象(如整数或字符串)到更复杂的对象(例如JSON)。
与关系数据库由行和列组成的表以及预定义数据类型组成的数据结构相反,键值数据库将数据存储为单个集合,而没有任何的结构或关系。
连接到数据库服务器后,应用程序可以定义一个键(例如the_meaning_of_life)并提供一个匹配的值(例如 42 ),然后可以通过该键以相同的方式检索匹配值。
特点
键值数据库将其包含的所有数据视为不透明的一团;并由应用程序决定数据库是何种结构。
键值数据库通常被描述为高性能,高效和可伸缩的。
应用
常见用例是缓存,消息队列和会话管理。
一些流行的开源键值数据存储为:
列举
| Database | Description |
|---|---|
| Redis | Redis 是用作数据库、缓存或消息代理的内存数据存储,支持各种数据结构,从字符串到位图、流和空间索引。 |
| Memcached | 一种通用内存对象缓存系统,常用于通过缓存内存中的数据和对象来加速数据驱动的网站和应用程序。 |
| Riak | 具有高级本地和多集群复制的分布式键值数据库。 |
列式数据库
简述
列式数据库(有时称为面向列的数据库)是将数据存储在列中的数据库系统。
看起来似乎与传统的关系数据库类似,但却不是将各列分组为表格,而是将每列存储在系统存储中的单独文件或区域中。
发展
面向列的数据库自 1960 年代就已经存在。
由于列式数据模型非常适合快速查询处理,因此自 2000 年中期以来列式数据库越来越广泛地用于数据分析。
特点
- 内存使用节省
列式数据库中存储的数据按记录的顺序显示,这意味着一个列中的第一个条目与其他列中的第一个条目相关。
这种设计允许查询仅读取所需的列,而不必读取表中的每一行,并在数据存储到内存后将不需要的数据丢弃。
- 查询速度快
因为每一列中的数据都是同一类型的,所以它允许各种存储和读取的优化策略。
特别是许多列式数据库管理员实施了压缩策略(例如行程长度压缩算法),将单个列占用的空间最小化。
由于查询需要遍历更少的行,因此可以提升读取的速度。
- 加载速度慢
但是列式数据库有一个缺点,由于每一列必须单独的写入并且数据通常会压缩,因此加载性能趋于降低。
特别是增量负载以及读取单个记录时就性能而言代价会非常高。
应用
在应用程序需要频繁执行汇总功能(例如查找列中数据的平均值或总计)的情况下,它们也被认为是有利的。
一些列式数据库管理系统甚至能够使用 SQL 查询。
列举
| Database | Description |
|---|---|
| Apache Cassandra | 旨在最大限度地提高可扩展性、可用性和性能的列存储。 |
| Apache HBase | 支持用于存储大量数据的结构化存储,旨在与Hadoop软件库一起使用。 |
| ClickHouse | 一种容错型DBMS,支持实时生成分析数据和SQL查询。 |
面向文档的数据库
简介
面向文档的数据库或文档存储是以文档的形式存储数据的 NoSQL 数据库。
文档存储是键值存储库的一种:每个文档都有一个唯一的标识符(即其键),而文档本身就是值。
对比
- 与键值对数据库相比
这两个模型之间的区别在于,在键值数据库中数据被视为不透明,并且数据库不知道或不在乎其中的数据;由应用程序决定存储什么样的数据。
但是在文档存储中每个文档都包含一些元数据,这些元数据提供了存储数据的一定程度的结构。
文档存储通常带有API或查询语言,允许用户根据其包含的元数据来检索文档。
它们还允许复杂的数据结构,因此可以将文档嵌套在其他文档中。
- 与关系型数据库对对比
与关系数据库不同,在关系数据库中给定对象的信息可以分布在多个表或数据库中。
而面向文档的数据库则可以将给定对象的所有数据存储在单个文档中。
文档存储通常将数据存储为 JSON,BSON,XML 或 YAML 文档,有些则可以存储二进制格式(如 PDF 文档)。
有些使用 SQL 的变体,全文搜索或原生查询语言来进行数据检索,而另外的一些功能则有不止一种的查询方法。
应用
近年来,面向文档的数据库越来越受欢迎。
凭借灵活的架构,它们在电子商务,博客和分析平台以及内容管理系统中被频繁地使用。
文档存储被认为是高度可伸缩的,分片是一种常见的水平扩展策略。
它们对于保留大量的结构上不相关的复杂信息也非常有用。
列举
| Database | Description |
|---|---|
| MongoDB | MongoDB是一种通用的分布式文档存储,在撰写本文时,它是世界上使用最广泛的面向文档的数据库。 |
| Couchbase | 最初称为Membase,这是一个基于JSON的,与Memcached兼容的基于文档的数据存储。 一个多模型数据库,Couchbase还可以用作键值存储。 |
| Apache CouchDB | 作为 Apache 软件基金会的项目,CouchDB 将数据存储为 JSON 文档,并将JavaScript 作为其查询语言。 |
图形数据库
简介
图形数据库可以被认为是文档存储模型的子类别,因为它们将数据存储在文档中,而不是要求数据遵循预定义的架构。
但是区别在于,图形数据库通过突出显示各个文档之间的关系为文档模型增加了额外的一层。
术语
为了更好地掌握图形数据库的概念,理解以下术语很重要:
| 名称 | 解释 |
|---|---|
| 节点 | 节点是图形数据库跟踪的单个实体的表示。 它或多或少地等同于关系数据库中的一条记录或行或者文档存储中的文档的概念。 例如,在唱片艺术家的图形数据库中,一个节点可能代表一个表演者或乐队。 |
| 属性 | 属性是与各个节点有关的相关信息。 以我们的唱片艺术家为例,根据数据库的相关信息,某些属性可能是“歌手”、“爵士”或“白金唱片销售艺术家”。 |
| 边缘 | 边缘也称为图形或关系,它表示两个节点之间的关系,是图形数据库中一个将它们与RDBMS和文档存储数据库区分开的关键概念。 边缘可以是有向的或无向的。 - 无向的 |
在无向图中,节点之间的边仅用于显示它们之间的连接。
在这种情况下,可以将边缘视为“双向”关系—— 一个节点与另一节点的关联间没有隐含的区别。
- 有向的
在有向图中,基于关系起始的方向,边可以具有不同的含义。
在这种情况下,边缘是“单向”关系。
例如,一个有向图形数据库可能会明确 Sammy 和 Seaweeds 之间的关系,Sammy 为该乐队制作了一张专辑,但可能不会表明 The Seaweeds 与 Sammy之间的对等关系。 |
应用
某些操作由于使用图形数据库进行链接和分组相关信息而更加容易执行。
这些数据库通常用于必须从数据点之间的关系中获得洞察力的情况下,或者在社交网络中,终端用户可用的信息由他们与其他人的连接关系决定的应用程序。
它们常用于欺诈检测、推荐引擎以及身份识别和授权访问管理程序。
列举
| Database | Description |
|---|---|
| Neo4j | 带有ACID的DBMS,具有本机图形存储和处理功能。 撰写本文时,Neo4j是世界上最受欢迎的图形数据库。 |
| ArangoDB | ArangoDB不仅是图形数据库,还是一个多模型数据库,将图形、文档和键值数据模型组合在一个DBMS中。 具有AQL(类似于SQL的本地查询语言)、全文搜索和排名引擎的特性。 |
| OrientDB | 另一个多模型数据库 OrientDB 支持图形、文档、键值和对象模型。它支持 SQL 查询和 ACID 事务。 |

若有收获,就点个赞吧
0 人点赞
