https://zhuanlan.zhihu.com/p/51566209
MobileNet v1
Mobilenet v1核心是把卷积拆分为Depthwise+Pointwise两部分。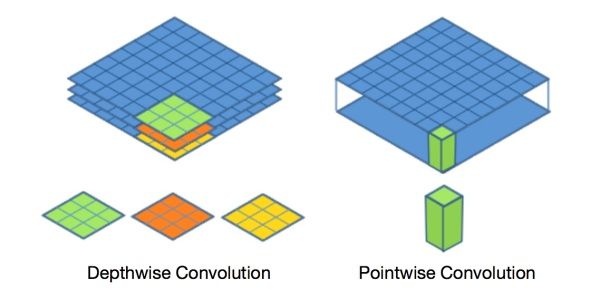
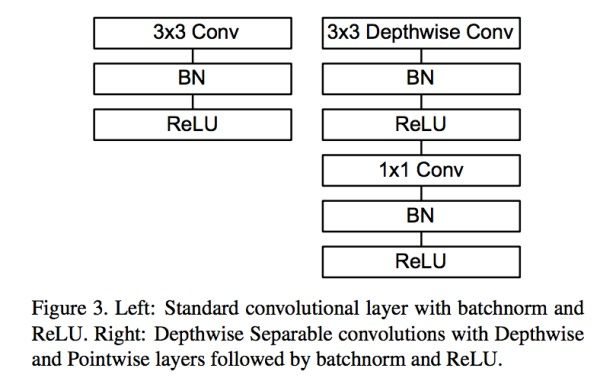
Depthwise只提取通道内部的特征,但是通道与通道间信息是相互隔离的;而Pointwise通过提取每个点的特征,对每个通道间的信息进行交换。Depthwise+Pointwise相当于把普通卷积分为了2个步骤而已。**这样就把一个普通卷积拆分成了Depthwise+Pointwise两部分。其实Mobilenet v1就是做了如下转换,如图9:
- 普通卷积:3x3 Conv+BN+ReLU
- Mobilenet卷积:3x3 Depthwise Conv+BN+ReLU 和 1x1 Pointwise Conv+BN+ReLU
MobileNet v2
MobileNet V2是Google继V1之后提出的下一代轻量化网络,主要解决了V1在训练过程中非常容易特征退化的问题,V2相比V1效果有一定提升。
问题1:ReLU造成的低维度数据坍塌(collapses)
Moblienet V2文中提出,假设在2维空间有一组由  个点组成的螺旋线
个点组成的螺旋线  数据,经随机矩阵
数据,经随机矩阵  映射到
映射到  维并进行ReLU运算,即:
维并进行ReLU运算,即:
再通过  矩阵的广义逆矩阵
矩阵的广义逆矩阵  将
将  映射回2维空间:
映射回2维空间:
对比  和
和  发现,当映射维度
发现,当映射维度  时,数据坍塌;当
时,数据坍塌;当  时,数据基本被保存,如图17。虽然这不是严格的数学证明,但是至少说明:channel少的feature map不应后接ReLU,否则会破坏feature map。
时,数据基本被保存,如图17。虽然这不是严格的数学证明,但是至少说明:channel少的feature map不应后接ReLU,否则会破坏feature map。
问题2:没有复用特征
在神经网络训练中如果某个卷积节点权重的值变为0就会“死掉”。因为对于任意输入,该节点的输出都是0。而ReLU对0值的梯度是0,所以后续无论怎么迭代这个节点的值都不会恢复了。而通过ResNet结构的特征复用,可以很大程度上缓解这种特征退化问题**,如图18(这也从一个侧面说明ResNet为何好于VGG)。另外,一般情况训练网络使用的是float32浮点数;当使用低精度的float16时,这种特征复用可以更加有效的减缓退化。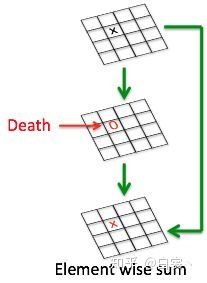
图18 复用特征可以减缓特征退化
基于上述两个问题,Mobilenet v2提出了Linear Bottlenecks+Inverted residual block作为网络基本结构,如图19。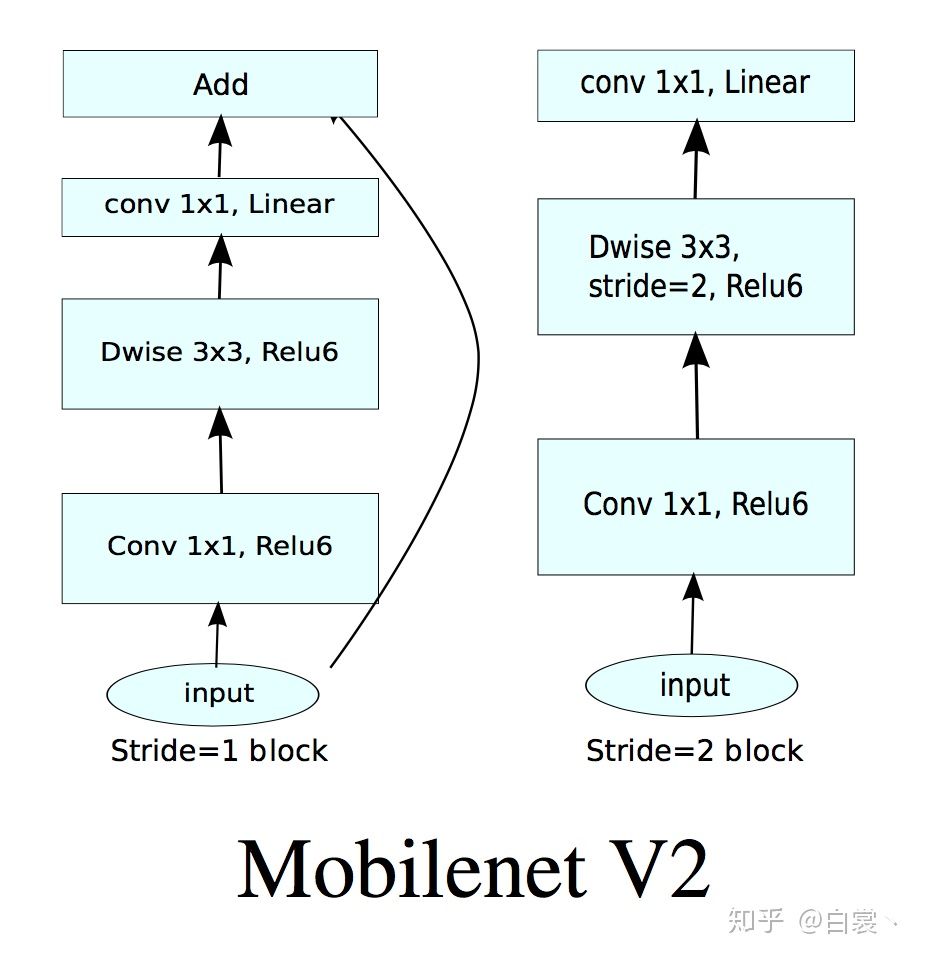
图19 Mobilenet v2基本卷积单元结构
ShuffleNet
ShuffleNet是Face++提出的一种轻量化网络结构,主要思路是使用Group convolution和Channel shuffle改进ResNet,可以看作是ResNet的压缩版本。
1、分组卷积的矛盾——计算量
使用group convolution的网络有很多,如Xception,MobileNet,ResNeXt等。其中Xception和MobileNet采用了depthwise convolution,这是一种比较特殊的group convolution,此时分组数恰好等于通道数,意味着每个组只有一个特征图。是这些网络存在一个很大的弊端是采用了密集的1x1 pointwise convolution(如下图)。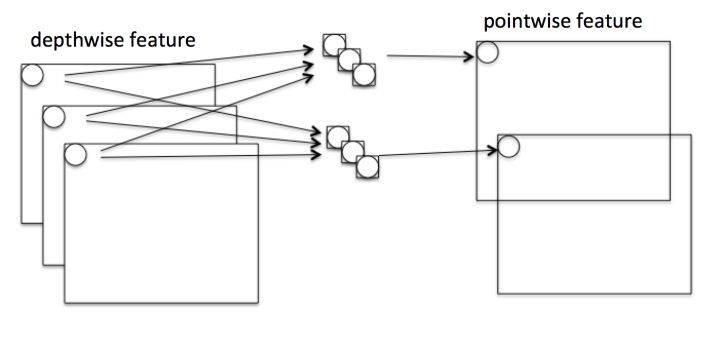
这个问题可以解决:对1x1卷积采用channel sparse connection 即分组操作,那样计算量就可以降下来了,但这就涉及到另外一个问题。
2、分组卷积的矛盾——特征通信
group convolution层另一个问题是不同组之间的特征图需要通信,否则就好像分了几个互不相干的路,大家各走各的,会降低网络的特征提取能力,这也可以解释为什么Xception,MobileNet等网络采用密集的1x1 pointwise convolution,因为要保证group convolution之后不同组的特征图之间的信息交流。
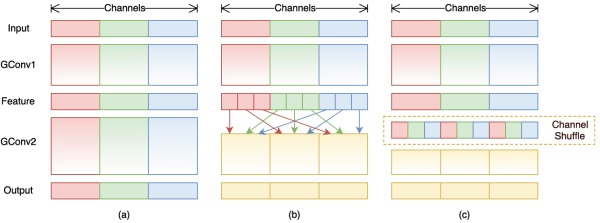
3、channel shuffle
为达到特征通信目的,我们不采用dense pointwise convolution,考虑其他的思路:channel shuffle。如图b,其含义就是对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。图c进一步的展示了这一过程并随机,其实是“均匀地打乱”。
在程序上实现channel shuffle是非常容易的:假定将输入层分为  组,总通道数为
组,总通道数为  ,首先你将通道那个维度拆分为
,首先你将通道那个维度拆分为  两个维度,然后将这两个维度转置变成
两个维度,然后将这两个维度转置变成  ,最后重新reshape成一个维度
,最后重新reshape成一个维度 。
。
ShuffleNet_v2
目前衡量模型复杂度的一个通用指标是FLOPs,具体指的是multiply-add数量,但是这却是一个间接指标,因为它不完全等同于速度。
总结一下,在设计高性能网络时,我们要尽可能做到:
- G1). 使用输入通道和输出通道相同的卷积操作;
- G2). 谨慎使用分组卷积;
- G3). 减少网络分支数;
- G4). 减少element-wise操作。
例如在ShuffleNet v1中使用的分组卷积是违背G2的,而每个ShuffleNet v1单元使用了bottleneck结构是违背G1的。MobileNet v2中的大量分支是违背G3的,在Depthwise处使用ReLU6激活是违背G4的。
ShuffleNet v2结构
图6中,(a),(b)是刚刚介绍的ShuffleNet v1,(c),(d)是这里要介绍的ShuffleNet v2。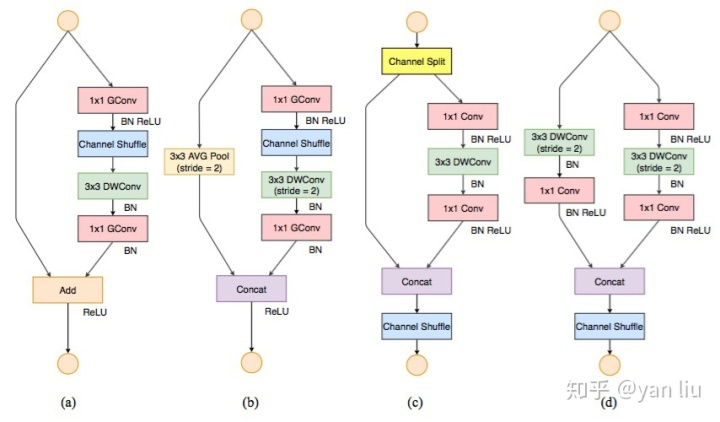 图6:(a) ShuffleNet v1 ,(b)ShuffleNet v1 降采样, (c)ShuffleNet v2,(d)ShuffleNet v2 降采样
图6:(a) ShuffleNet v1 ,(b)ShuffleNet v1 降采样, (c)ShuffleNet v2,(d)ShuffleNet v2 降采样
仔细观察(c),(d)对网络的改进我们发现了以下几点:
- 在(c)中ShuffleNet v2使用了一个通道分割(Channel Split)操作。这个操作非常简单,即将
 个输入Feature分成
个输入Feature分成  和
和  两组,一般情况下
两组,一般情况下  。这种设计是为了尽量控制分支数,为了满足G3。
。这种设计是为了尽量控制分支数,为了满足G3。 - 在分割之后的两个分支,左侧是一个直接映射,右侧是一个输入通道数和输出通道数均相同的深度可分离卷积,为了满足G1。
- 在右侧的卷积中,
 卷积并没有使用分组卷积,为了满足G2。
卷积并没有使用分组卷积,为了满足G2。 - 最后在合并的时候均是使用拼接操作,为了满足G4。
- 在堆叠ShuffleNet v2的时候,通道拼接,通道洗牌和通道分割可以合并成1个element-wise操作,也是为了满足G4。
ShuffleNet v2和DenseNet
ShuffleNet v2能够得到非常高的精度是因为它和DenseNet有着思想上非常一致的结构:强壮的特征重用(Feature Reuse)。在DenseNet中,作者大量使用的拼接操作直接将上一层的Feature Map原汁原味的传到下一个乃至下几个模块。从6.(c)中我们也可以看处,左侧的直接映射和DenseNet的特征重用是非常相似的。
不同于DenseNet的整个Feature Map的直接映射,ShuffleNet v2只映射了一半。恰恰是这一点不同,是ShuffleNet v2有了和DenseNet的升级版CondenseNet[8]相同的思想。在CondenseNet中,作者通过可视化DenseNet的特征重用和Feature Map的距离关系发现距离越近的Feature Map之间的特征重用越重要。ShuffleNet v2中第 个和第
个和第  个Feature Map的重用特征的数量是
个Feature Map的重用特征的数量是  。也就是距离越远,重用的特征越少。
。也就是距离越远,重用的特征越少。

若有收获,就点个赞吧
0 人点赞
