Title
Deep Neural Networks for YouTube Recommendations
Summary
工程借鉴意义非常强。引用自:https://zhuanlan.zhihu.com/p/52504407
1、文中把推荐问题转换成多分类问题,在预测next watch的场景下,每一个备选video都会是一个分类,因此总共的分类有数百万之巨,这在使用softmax训练时无疑是低效的,这个问题YouTube是如何解决的?
We rely on a technique to sample negative classes from the background distribution (“candidate sampling“) and then correct for this sampling via importance weighting.
2、在candidate generation model的serving过程中,YouTube为什么不直接采用训练时的model进行预测,而是采用了一种最近邻搜索的方法?
在model serving过程中对几百万个候选集逐一跑一遍模型的时间开销显然太大了,因此在通过candidate generation model得到user 和 video的embedding之后,通过最近邻搜索的方法的效率高很多。
- user vector: 这个DNN输入的特征是
- item_vecor: Softmax中v输入层video的对应的w作为这个video的vector.
3、Youtube的用户对新视频有偏好,那么在模型构建的过程中如何引入这个feature?
为了拟合用户对fresh content的bias,模型引入了”Example Age”这个feature, Example Age就是用训练时间的最后一刻减去Sample Log产生的时间用来有效区分点击的时间影响,预测时置为0保证预测时处于训练的最后一刻,论文也说了还可以稍微负一些,虽然还没试过,但可以理解为处于训练窗口以后的时间去预测。
4、在对训练集的预处理过程中,YouTube没有采用原始的用户日志,而是对每个用户提取等数量的训练样本,这是为什么?
Another key insight that improved live metrics was to generate a xed number of training examples per user, e ectively weighting our users equally in the loss function. This prevented a small cohort of highly active users from dominating the loss.
为了减少高度活跃用户对于loss的过度影响。
5、YouTube为什么不采取类似RNN的Sequence model,而是完全摒弃了用户观看历史的时序特征,把用户最近的浏览历史等同看待,这不会损失有效信息吗?
这个原因应该是YouTube工程师的“经验之谈”,如果过多考虑时序的影响,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。但RNN到底适不适合next watch这一场景,其实还有待商榷,YouTube已经上线了以RNN为基础的推荐模型, 参考论文:Latent Cross: Making Use of Context in Recurrent Recommender Systems
6、在处理测试集的时候,YouTube为什么不采用经典的随机留一法(random holdout),而是一定要把用户最近的一次观看行为作为测试集?
只留最后一次观看行为做测试集主要是为了避免引入future information,产生与事实不符的数据穿越。
7、在确定优化目标的时候,YouTube为什么不采用经典的CTR,或者播放率(Play Rate),而是采用了每次曝光预期播放时间(expected watch time per impression)作为优化目标?
这个问题从模型角度出发,是因为 watch time更能反应用户的真实兴趣,从商业模型角度出发,因为watch time越长,YouTube获得的广告收益越多。而且增加用户的watch time也更符合一个视频网站的长期利益和用户粘性。
这个问题看似很小,实则非常重要,objective的设定应该是一个算法模型的根本性问题,而且是算法模型部门跟其他部门接口性的工作,从这个角度说,YouTube的推荐模型符合其根本的商业模型,非常好的经验。
8、在进行video embedding的时候,为什么要直接把大量长尾的video直接用0向量代替?
这又是一次工程和算法的trade-off,把大量长尾的video截断掉,主要还是为了节省online serving中宝贵的内存资源。当然从模型角度讲,低频video的embedding的准确性不佳是另一个“截断掉也不那么可惜”的理由。
低频特征其实去掉比embedding更好效果更好,出现次数太少emb学不好。实际可以用HashBucket去映射,对于大规模稀疏ID类特征,实际使用上用Hash不会对结果产生太大影响,反而在增量更新的情况上可能会比置为0更好。
9、针对某些特征,比如previous impressions,为什么要进行开方和平方处理后,当作三个特征输入模型?
这是很简单有效的工程经验,引入了特征的非线性。从YouTube这篇文章的效果反馈来看,提升了其模型的离线准确度。
10、为什么ranking model不采用经典的logistic regression当作输出层,而是采用了weighted logistic regression?
在第7点中,我们已经知道模型采用了expected watch time per impression作为优化目标,所以如果简单使用LR就无法引入正样本的watch time信息。因此采用weighted LR,将watch time作为正样本的weight,在线上serving中使用e(Wx+b)做预测可以直接得到expected watch time的近似。
Research Objective
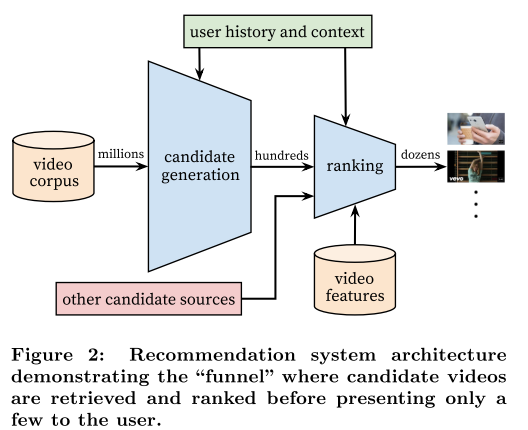
Problem Statement
Recommending YouTube videos is extremely challenging from three major perspectives:
- _Scale _handling YouTube’s massive user base and corpus.
- Freshness _should be responsive enough to model newly uploaded content as well as the latest actions taken by the user. Balancing new content and well-established videos can be understood from an _exploration/exploitation perspective.
- Noise
Stage 1: CANDIDATE GENERATION
Recommendation as Classification
Accurately classifying a specific video watch  at time
at time  among millions of videos
among millions of videos  (classes) from a corpus
(classes) from a corpus  based on a user
based on a user  and context
and context  ,
,
where  represents a high-dimensional “embedding” of the user, context pair and
represents a high-dimensional “embedding” of the user, context pair and  represent embeddings of each candidate video. User completing a video is a positive example.
represent embeddings of each candidate video. User completing a video is a positive example.
Efficient Extreme Multiclass
To train such a model with millions of classes, we rely on a technique to sample negative classes from the background distribution (“candidate sampling”) and then correct for this sampling via importance weighting.
参考论文: On Using Very Large Target Vocabulary for Neural Machine Translation
参考资料: What is Candidate Sampling
除了Sampled Softmax外,已有的其他解决方法主要有:
- 利用其它的方法,去逼近softmax的概率,比如:基于noise-contrastive estimation (NCE)的方法,类似于word2vec中skip-gram的negative sampling
- Hierarchical Softmax
At serving time, calibrated likelihoods from the softmax output layer are not needed at serving time, the scoring problem reduces to a nearest neighbor search in the dot product space for which general purpose libraries can be used.
参考论文:T. Liu, A. W. Moore, A. Gray, and K. Yang. An investigation of practical approximate nearest neighbor algorithms. pages 825–832. MIT Press, 2004.
_
Model Architecture
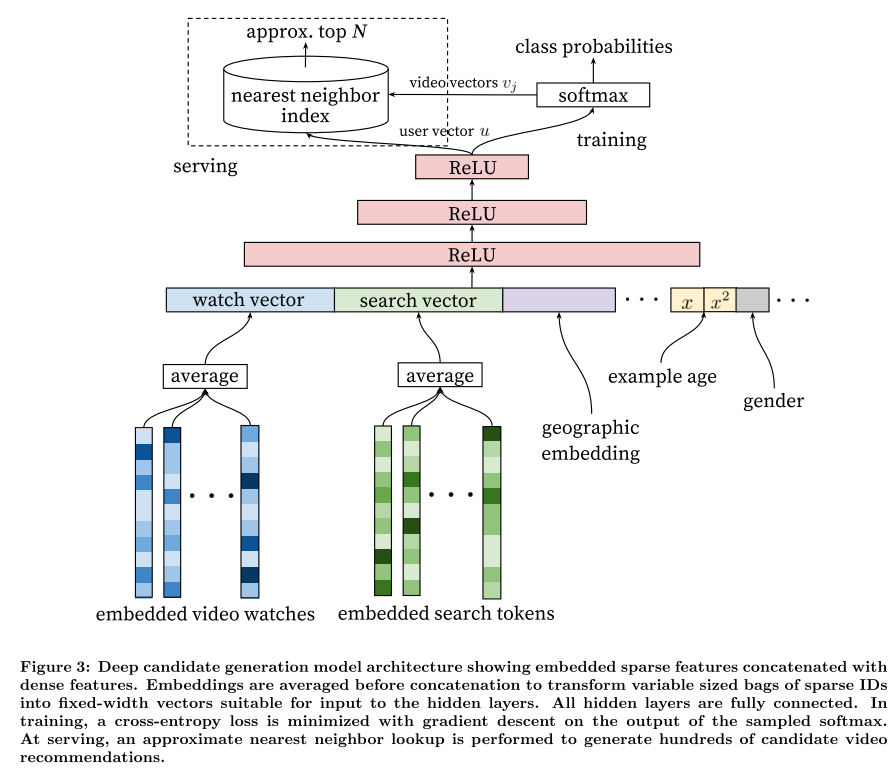
Features:
- Watch history is represented by a variable-length sequence of sparse video IDs which is mapped to a dense vector representation via the embeddings (we learn high dimensional embeddings for each video in a fixed vocabulary)
- Search history is treated similarly to watch history - each query is tokenized into unigrams and bigrams and each token is embedded
- Demographic features are important for providing priors so that the recommendations behave reasonably for new users. The user’s geographic region and device are embedded and concatenated.
- Simple binary and continuous features such as the user’s gender, logged-in state and age are input directly into the network as real values normalized to [0, 1].
Example Age: Feed the age of the training example as a feature during training due to the distribution of video popularity is highly non-stationary but the multinomial distribution over the corpus produced by our recommender will reflect the average watch likelihood in the training window of several weeks (removes an inherent bias towards the past). At serving time, this feature is set to zero (or slightly negative) to reflect that the model is making predictions at the very end of the training window. (the example age is expressed as
 where
where  is the maximum observed time in the training data).
is the maximum observed time in the training data).
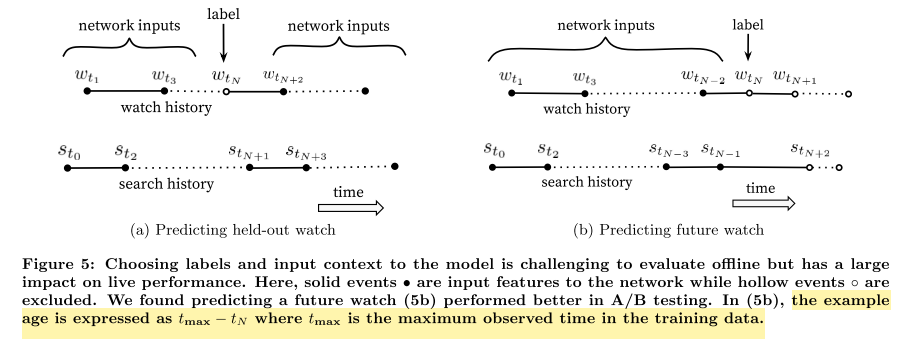
Label and Context Selection:
Training examples are generated from all YouTube watches (even those embedded on other sites) rather than just watches on the recommendations we produce. Otherwise, it would be very difficult for new content to surface and the recommender would be overly biased towards exploitation. If users are discovering videos through means other than our recommendations, we want to be able to quickly propagate this discovery to others via collaborative filtering.
- Generate a fixed number of training examples per user, effectively weighting our users equally in the loss function. This prevented a small cohort of highly active users from dominating the loss.
- Withhold (隐瞒) information from the classifier _in order to prevent the model from exploiting the structure of the site and overfitting the surrogate problem. e.g., given user’s last query “taylor swift”, classifier given this information will predict that the most likely videos to be watched are those which appear on the corresponding search results page for “taylor swift”, this is not what we want. **_By discarding sequence information and representing search queries with an unordered bag of tokens, the classifier is no longer directly aware of the origin of the label.**
- Episodic series are usually watched sequentially and users often discover artists in a genre beginning with the most broadly popular before focusing on smaller niches. We therefore found much better performance predicting the user’s next watch, rather than predicting a randomly held-out watch. Many collaborative filtering systems implicitly choose the labels and context by holding out a random item and predicting it from other items in the user’s history (5a). This leaks future information and ignores any asymmetric consumption patterns. In contrast, we “rollback” a user’s history by choosing a random watch and only input actions the user took before the held-out label watch (5b).
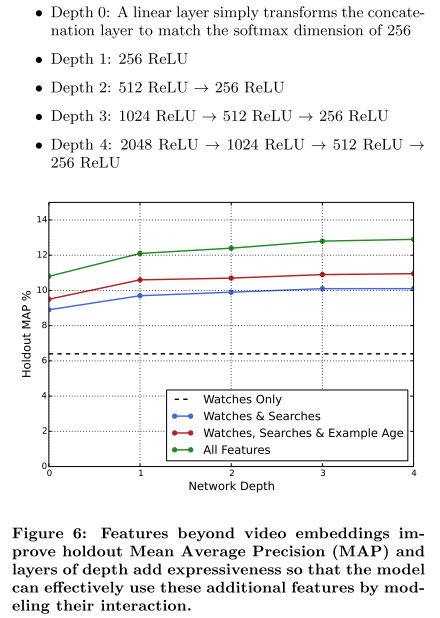
Experiments with Features and Depth
Stage 2: RANKING
During ranking, we have access to many more features describing the video and the user’s relationship to the video because only a few hundred videos are being scored rather than the millions scored in candidate generation. Ranking is also crucial for ensembling different candidate sources whose scores are not directly comparable.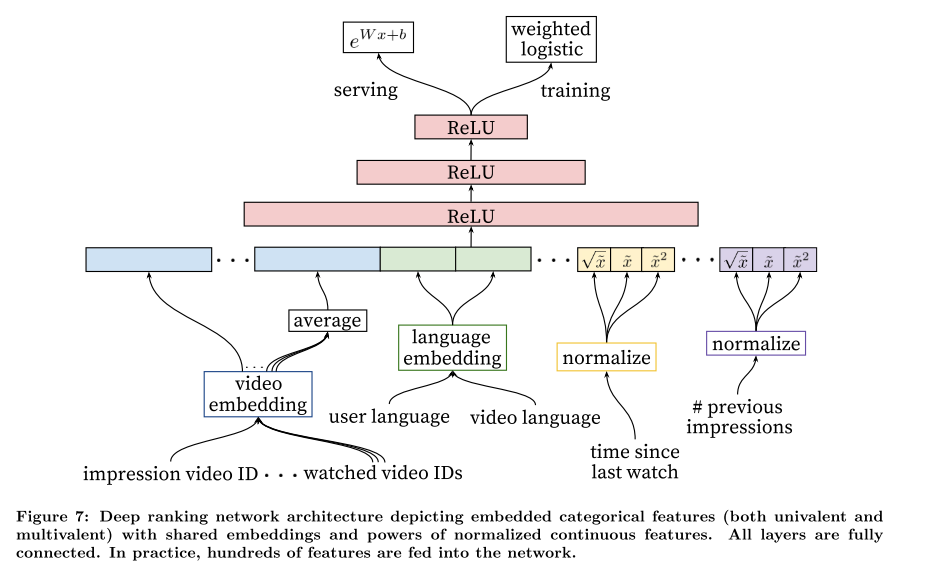
Feature Representation
Feature Engineering
- The most important signals are those that describe a user’s previous interaction with the item itself and other similar items, matching others’ experience in ranking ads. 参考资料:X. He, J. Pan, O. Jin, T. Xu, B. Liu, T. Xu, Y. Shi, A. Atallah, R. Herbrich, S. Bowers, and J. Q. n. Candela. Practical lessons from predicting clicks on ads at facebook. In Proceedings of the Eighth International Workshop on Data Mining for Online Advertising, ADKDD’14, pages 5:1–5:9, New York, NY, USA, 2014. ACM._ e.g, _user’s past history with the channel that uploaded the video being scored - howmany videos has the user watched from this channel? When was the last time the user watched a video on this topic(例如自上次观看同channel视频的时间)? These continuous features describing past user actions on related items are particularly powerful because they generalize well across disparate items.
- Propagate information from candidate generation into ranking in the form of features, e.g. which sources nominated this video candidate? What scores did they assign?
- Features describing the frequency of past video impressions are also critical for introducing “churn” in recommendations (successive requests do not return identical lists). If a user was recently recommended a video but did not watch it then the model will naturally demote this impression on the next page load.
Embedding Categorical Features
- Use embeddings to map sparse categorical features to dense representations suitable for neural networks. Each unique ID space (“vocabulary”) has a separate learned embedding with dimension that increases approximately proportional to the logarithm of the number of unique values.
- Very large cardinality ID spaces (e.g. video IDs or search query terms) are truncated by including only the top N after sorting based on their frequency in clicked impressions. Out-of-vocabulary values are simply mapped to the zero embedding.
- As in candidate generation, multivalent categorical feature embeddings are averaged before being fed in to the network.
- Categorical features in the same ID space also share underlying emeddings. For example, there exists a single global embedding of video IDs that many distinct features use (video ID of the impression, last video ID watched by the user, video ID that “seeded” the recommendation, etc.).
- Sharing embeddings is important for improving generalization, speeding up training and reducing memory requirements.
Normalizing Continuous Features
Proper normalization of continuous features was critical for convergence because neural networks are notoriously sensitive to the scaling and distribution of their inputs.
A continuous feature  with distribution
with distribution  is transformed to
is transformed to  by scaling the values such that the feature is equally distributed in
by scaling the values such that the feature is equally distributed in  using the cumulative distribution,
using the cumulative distribution,  . This integral is approximated with linear interpolation on the quantiles of the feature values computed in a single pass over the data before training begins.
. This integral is approximated with linear interpolation on the quantiles of the feature values computed in a single pass over the data before training begins.
In addition to the raw normalized feature , we also input powers  and
and  , giving the network more expressive power by allowing it to easily form super- and sub-linear functions of the feature. Feeding powers of continuous features was found to improve offline accuracy.
, giving the network more expressive power by allowing it to easily form super- and sub-linear functions of the feature. Feeding powers of continuous features was found to improve offline accuracy.
Modeling Expected Watch Time
Our goal is to predict expected watch time given training examples that are either positive (the video impression was clicked) or negative (the impression was not clicked). Positive examples are annotated with the amount of time the user spent watching the video. To predict expected watch time we use the technique of weighted logistic regression, which was developed for this purpose.
Odds (发生比或者机会比):
Odds是一件事情发生和不发生的比值。
如果对Odds取自然对数,再让 等于一个线性回归函数,那么就得到了下面的等式:
等于一个线性回归函数,那么就得到了下面的等式:
逻辑回归由上式转变得来:
那么再对 做一个转换,两边取自然底数:
做一个转换,两边取自然底数:
由于是Weighted LR算法,
由于在推荐场景中,用户打开一个视频的频率 往往很小,上式简化为:
往往很小,上式简化为:
因此YouTube采用 这一指数形式预测的就是曝光这个视频时,用户观看这个视频的时长的期望,利用该指标排序后再进行推荐,是完全符合YouTube的推荐场景和以观看时长为优化目标的设定的。
这一指数形式预测的就是曝光这个视频时,用户观看这个视频的时长的期望,利用该指标排序后再进行推荐,是完全符合YouTube的推荐场景和以观看时长为优化目标的设定的。
Experiments with Hidden Layers
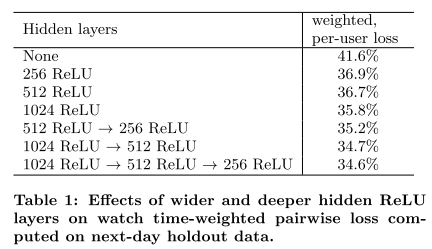
Notes
Reference
https://zhuanlan.zhihu.com/p/61827629
https://zhuanlan.zhihu.com/p/52504407

若有收获,就点个赞吧
0 人点赞
