Title
Wide & Deep Learning for Recommender Systems
Summary
Present Wide & Deep learning framework to combine the strengths of wide linear model’s memorization and deep neural networks’ generalization.
Research Objective
Present the Wide & Deep learning framework to achieve both memorization and generalization in one model, by jointly training a linear model component and a neural network component.
Problem Statement
- liner models with cross-product feature transformation
- pros
- can memorize “exception rules” with fewer parameters (generalize well and make less relevant recommendations)
- cons
- do not generalize to query-item feature paris that have not appeared in the training data
- need manual feature engineering
- pros
- emdedding based models e.g., factorization machines, deep neural networks
- pros
- can generalize to previously unseen query-item feature paris by learning a low-dimensional dense embedding vector for each query and item feature, with less burden of feature engineering
- cons
- dense embeddings will lead to nonzero predictions for all query-item pairs, and thus can over-generalize and make less relevant recommendations
- pros
Method(s)
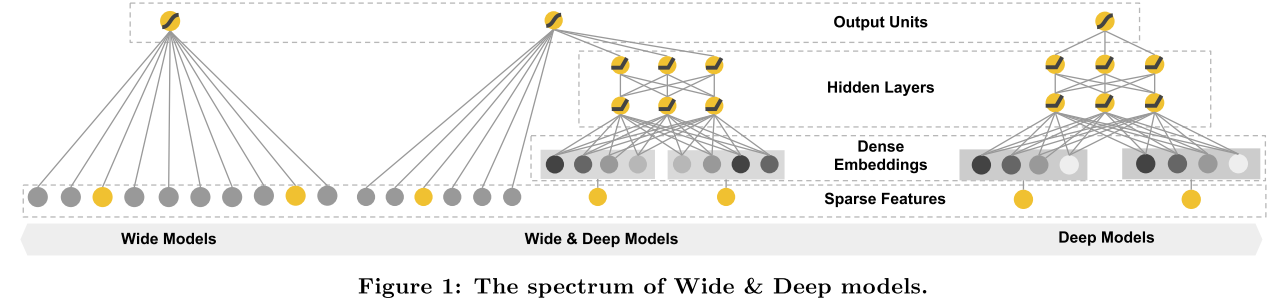
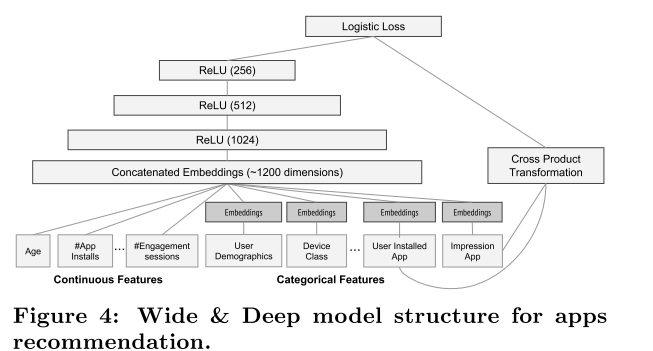
The Wide Component

where x is a vector of d features. One of the most important transformations is the cross-product transformation.cross-product transformation
 where
where  is a boolean variable that is
is a boolean variable that is  if the i-th feature is part of the k-th transformation
if the i-th feature is part of the k-th transformation  , and
, and  otherwise.
For binary features, a cross-product transformation (e.g.,
“AND(gender=female, language=en)”) is if and only if the
constituent features (“gender=female” and “language=en”)
are all , and otherwise.
otherwise.
For binary features, a cross-product transformation (e.g.,
“AND(gender=female, language=en)”) is if and only if the
constituent features (“gender=female” and “language=en”)
are all , and otherwise.The Deep Component
High-dimensional categorical features are first converted into a low-dimensional and dense real-valued vector, usually on the order of  to
to  .
.
- Joint Training
For a logistic regression, the model predictions is
where  is the binary class label,
is the binary class label,  is cross product transformations of the original features
is cross product transformations of the original features  ,
,  is the neural network’s final activation.
is the neural network’s final activation.
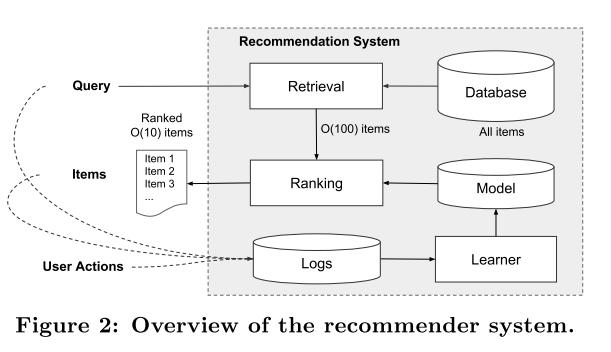
Evaluation
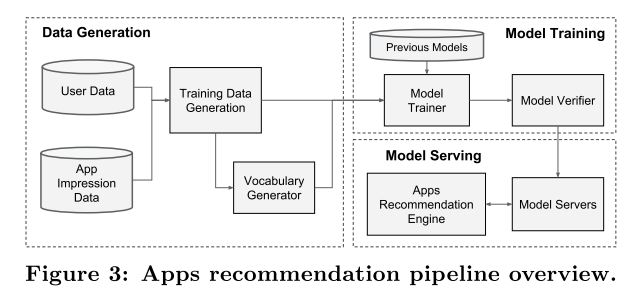
- Data Generation
Continues real-valued features are normalized to  by mapping a feature value to its cumulative distribution function
by mapping a feature value to its cumulative distribution function  , divided into
, divided into  quantiles. The normalized value is
quantiles. The normalized value is  for values in the i-th quantiles.
for values in the i-th quantiles.
- App Acquisition
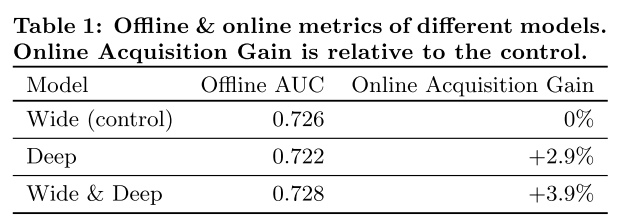
- Serving Performance

Conclusion
Memorization and generalization are both important for
recommender systems.
Wide linear models can effectively memorize sparse feature interactions using cross-product feature transformations, while deep neural networks can generalize to previously unseen feature interactions through low-dimensional embeddings.
Notes(optional)
Reference(optional)

若有收获,就点个赞吧
0 人点赞
