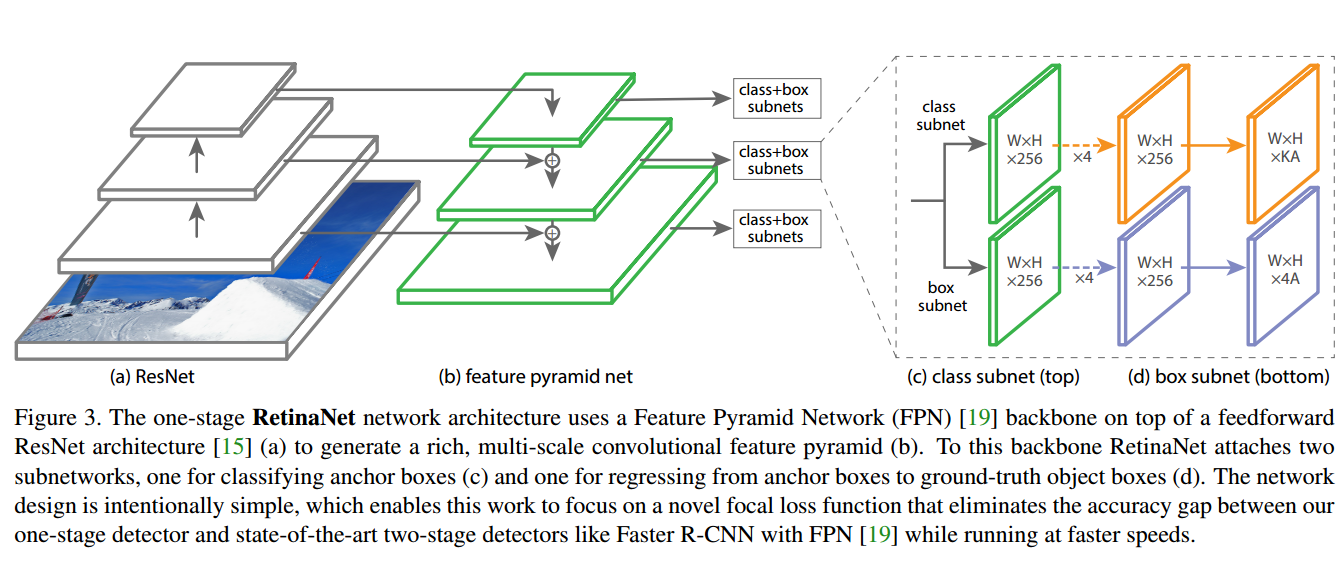
Feature Pyramid Network Backbone:
作者用了Feature Pyramid Network,FPN作为Retina的Backbone。FPN提出标准的有top-down pathway上下通道和lateral connections横向连接的卷积网络,所以网络从单分辨率的图像中构建了一个丰富、多尺度特征金字塔。从上图的(a)(b)可以看出来。
作者在ResNet的顶部构建FPN,用P3到P7层构建了金字塔。(第  层分辨率是第一层的
层分辨率是第一层的  )。只用最后一层的特征的话AP很低。
)。只用最后一层的特征的话AP很低。
CVPR 现场提问:>
1. 不同深度的 feature map 为什么可以经过 upsample 后直接相加?A:作者解释说这个原因在于我们做了 end-to-end 的 training,因为> 不同层的参数不是固定的,不同层同时给监督做 end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。>
2. 为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid) 对于小物体检测提升明显?(RPN 步骤 AR 从 30.5 到 44.9,Fast RCNN 步骤 AP 从 24.9 到 33.9)A:对于小物体,一方面它提高了小目标的分辨率信息;另一方面,如图中的挎包一样,从上到下传递过来的更全局的情景信息可以更准确判断挎包的存在及位置。

- 如果不考虑时间情况下,image pyramid 是否可能会比 feature pyramid 的性能更高?A:作者觉得经过精细调整训练是可能的,但是 image pyramid 主要的问题在于时间和空间占用太大,而 feature pyramid 可以在几乎不增加额外计算量情况下解决多尺度检测问题。
Anchors:
作者用了translation-invariant anchor boxes 平移不变锚与RPN的变体相似。这个anchor在金字塔层P3到P7有相应的  到
到  的区域。在每个金字塔层,作者用的长宽比是{
的区域。在每个金字塔层,作者用的长宽比是{  }。在每层,对于三个长宽比的anchor,加了anchor的形状的{
}。在每层,对于三个长宽比的anchor,加了anchor的形状的{  }的anchor。这能够增加AP。对于每层,有A=9个anchor,穿过这些层,它们可以覆盖32-813个输入图片中的像素。每个Anchor都是K个分类目标的one-hot向量(K是目标类别数)和4个box regression目标。作者设定anchor的方式是与ground-truth 的intersection-over-union (IoU) 阈值0.5,与背景IOU
}的anchor。这能够增加AP。对于每层,有A=9个anchor,穿过这些层,它们可以覆盖32-813个输入图片中的像素。每个Anchor都是K个分类目标的one-hot向量(K是目标类别数)和4个box regression目标。作者设定anchor的方式是与ground-truth 的intersection-over-union (IoU) 阈值0.5,与背景IOU  。所有的anchor都被设定为一个box,在预测向量的对应的类位置设1,其他的设为0。如果没有被设定,那么
。所有的anchor都被设定为一个box,在预测向量的对应的类位置设1,其他的设为0。如果没有被设定,那么  ,它是在训练时候被忽略的。Box regression targets是计算出来的每个anchor和它设定的object box的偏移量,如果没有设定那么忽略。
,它是在训练时候被忽略的。Box regression targets是计算出来的每个anchor和它设定的object box的偏移量,如果没有设定那么忽略。
Classification Subnet:**
分类子网络在每个空间位置,为A个anchor和K个类别,预测object presence的概率。这个子网络是小的FCN(全卷积网络),与FPN中的每层相接;这个子网络的参数在整个金字塔的层间共享。设计方法是:如果一个从金字塔某个层里来的feature map是C个通道,子网络使用 四个 的卷积层,C个滤波器,每个都接着ReLU激活函数;接下来用
的卷积层,C个滤波器,每个都接着ReLU激活函数;接下来用  的卷积层,有
的卷积层,有  个滤波器。最后用sigmoid激活函数对于每个空间位置,输出
个滤波器。最后用sigmoid激活函数对于每个空间位置,输出  个binary预测。作者用实验中
个binary预测。作者用实验中 
 。
。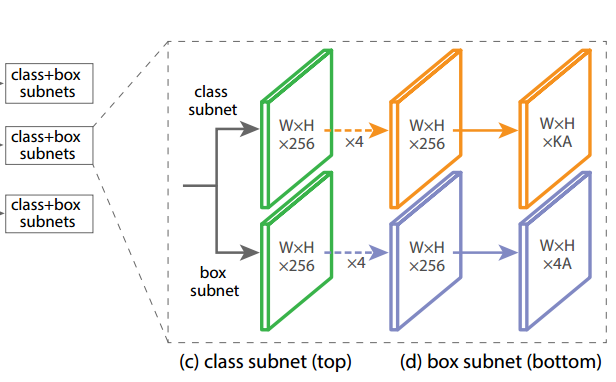
与RPN对比,作者的object classification子网络更深,只用  卷积,且不和box regression子网络共享参数。作者发现这种higer-level设计决定比超参数的特定值要重要。
卷积,且不和box regression子网络共享参数。作者发现这种higer-level设计决定比超参数的特定值要重要。
Box Regression Subnet:
与object classification子网络平行,作者在金字塔每个层都接到一个小的FCN上,意图回归每个anchor box对邻近ground truth object的偏移量。回归子网络的设计和分类相同,不同的是它为每个空间位置输出4A个线性输出。对于每个空间位置的A个anchor,4个输出预测anchor和ground-truth box的相对偏移。与现在大多数工作不同的是,作者用了一个class-agnostic bounding box regressor,这样能用更少的参数更高效。Object classification和bounding box regression两个网络共享一个网络结构,但是分别用不同的参数。
Inference:
RetinaNet的inference涉及把图片简单地在网络中前向传播。为了提升速度,作者只在每个FPN,从1k个top-scoring预测中提取box预测(在置信度阈值0.05处理之后)。多个层来的Top prediction聚在一起然后用NMS(非极大值抑制)以0.5为阈值。
Initialization:**
作者在ResNet-50-FPN和ResNet-101-FPN的backbone上面做实验。基础模型是在ImageNet1K上面预训练的。除了最后一层,RetinaNet的子网络都是初始化为bias b=0和权值weight用高斯初始化  。classification子网络的最后一层的conv层,作者的bias初始化为
。classification子网络的最后一层的conv层,作者的bias初始化为  其中
其中  表示每个anchor在开始训练的时候应该被标记为背景的置信度
表示每个anchor在开始训练的时候应该被标记为背景的置信度  。作者用
。作者用  在所有的实验中。这样初始化能够防止大的数量的背景anchor在第一次迭代的时候产生大的不稳定的损失值。
在所有的实验中。这样初始化能够防止大的数量的背景anchor在第一次迭代的时候产生大的不稳定的损失值。
根据sigmoid推导:

Optimization:
RetinaNet是用SGD训练的。作者用了同步的SGD在8个GPU上面,每个minibatch16张图,每个GPU2张图。所有的模型都是训练90K迭代的,初始学习率是0.01(会在60k被除以10,以及在80K除以10)。作者只用图像的横向翻转作为唯一的数据增广方式。权值衰减0.0001以及动量0.9。训练的损失是focal loss和标准的smooth L1 loss作为box回归。

若有收获,就点个赞吧
0 人点赞
