框架
基于RNN文字识别算法主要有两个框架: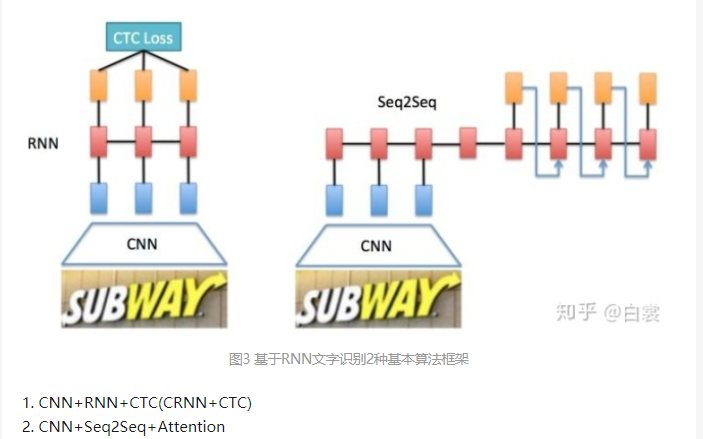
- CNN+RNN+CTC(CRNN+CTC)
- CNN+Seq2Seq+Attention
CNN+RNN+CTC(CRNN+CTC)
Label:字符集合+Blank_labelCNN+Seq2Seq+Attention
Label:字符集合+、 、 (填补部分不计入loss)
https://github.com/koibiki/CRNN-ATTENTION/blob/master/net/net.pyCTC
训练时候每张样本图片都需要标记出每个字符在图片中的位置,再通过CNN感受野对齐到Feature map的每一列获取该列输出对应的Label才能进行训练。
在实际情况中,标记这种对齐样本非常困难(除了标记字符,还要标记每个字符的位置),工作量非常大。另外,由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。
所以CTC提出一种对不需要对齐的Loss计算方法,用于训练网络,被广泛应用于文本行识别和语音识别中。
Blank符号
如果要进行  的26个英文字符识别,考虑到有的位置没有字符,定义插入blank的字符集合:
的26个英文字符识别,考虑到有的位置没有字符,定义插入blank的字符集合:

其中blank表示当前列对应的图像位置没有字符(下文以 符号表示blank)。
符号表示blank)。
关于 变换
变换
定义变换  如下(原文是大写的
如下(原文是大写的  ,没这个符号):
,没这个符号):
其中  是上述加入blank的长度为
是上述加入blank的长度为  的字符集合,经过
的字符集合,经过  变换后得到原始
变换后得到原始  ,显然对于
,显然对于 的最大长度有
的最大长度有  。
。
举例说明,当  时:
时:



对于字符间有blank符号的则不合并:
当获得LSTM输出 后进行
后进行 变换,即可获得输出结果。显然
变换,即可获得输出结果。显然  变换不是单对单映射,例如对于不同的
变换不是单对单映射,例如对于不同的 都可获得英文单词state。同时
都可获得英文单词state。同时  成立。
成立。
那么CTC怎么做?
对于LSTM给定输入  的情况下,输出为
的情况下,输出为  的概率为:
的概率为:
其中  代表所有经过
代表所有经过  变换后是
变换后是  的路径
的路径  。
。
其中,对于任意一条路径  有:
有:
注意这里的  中的
中的  ,下标
,下标  表示
表示  路径的每一个时刻;而上面
路径的每一个时刻;而上面  的下标表示不同的路径。两个下标含义不同注意区分。
的下标表示不同的路径。两个下标含义不同注意区分。
*注意上式  成立有条件,此项不做进一步讨论,有兴趣的读者请自行研究。
成立有条件,此项不做进一步讨论,有兴趣的读者请自行研究。
如对于  的路径
的路径  来说:
来说:

实际情况中一般手工设置  ,所以有非常多条
,所以有非常多条  路径,即
路径,即  非常大,无法逐条求和直接计算
非常大,无法逐条求和直接计算  。所以需要一种快速计算方法。
。所以需要一种快速计算方法。
CTC的训练目标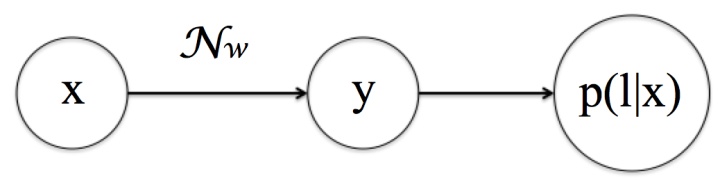 图14
图14
CTC的训练过程,本质上是通过梯度  调整LSTM的参数
调整LSTM的参数  ,使得对于输入样本为
,使得对于输入样本为  时使得
时使得  取得最大。
取得最大。
例如下面图14的训练样本,目标都是使得  时的输出
时的输出  变大。
变大。
图14
CTC借用了HMM的“向前—向后”(forward-backward)算法来计算 
要计算  ,由于有blank的存在,定义路径
,由于有blank的存在,定义路径  为在路径
为在路径  每两个元素以及头尾插入blank。那么对于任意的
每两个元素以及头尾插入blank。那么对于任意的  都有
都有  (其中
(其中  )。如:
)。如:

显然  ,其中
,其中  是路径的最大长度,如上述例子中
是路径的最大长度,如上述例子中  。
。
定义所有经  变换后结果是
变换后结果是  且在
且在  时刻结果为
时刻结果为  (记为
(记为 )的路径集合为
)的路径集合为  。
。
求导:
注意上式中第二项与  无关,所以:
无关,所以:
而上述  就是恰好与概率
就是恰好与概率  相关的路径,即
相关的路径,即  时刻都经过
时刻都经过  (
( )。
)。
举例说明,还是看上面的例子  (这里的下标
(这里的下标  代表不同的路径):
代表不同的路径):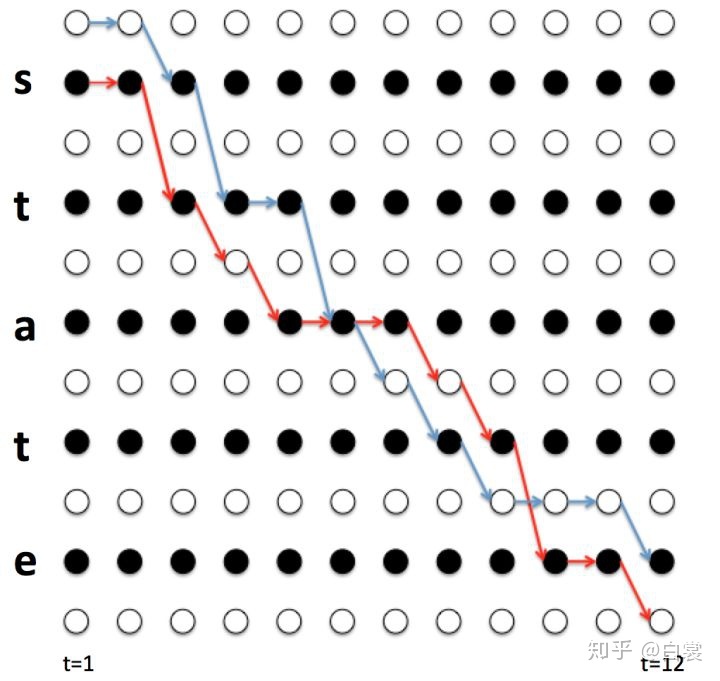 图15
图15
蓝色路径  :
:

红色路径  :
:

还有  没有画出来。
没有画出来。
而  在
在  时恰好都经过
时恰好都经过  (此处下标代表路径
(此处下标代表路径  的
的  时刻的字符)。所有类似于
时刻的字符)。所有类似于  经过
经过  变换后结果是
变换后结果是  且在
且在  的路径集合表示为
的路径集合表示为  。
。
观察  。记
。记  蓝色为
蓝色为  ,
,  红色路径为
红色路径为  ,
,  可以表示:
可以表示:

那么  可以表示为:
可以表示为:

计算:
为了观察规律,单独计算  。
。




不妨令:

那么 可以表示为:
可以表示为:
推广一下,所有经过  变换为
变换为  且
且  的路径(即
的路径(即  )可以写成如下形式:
)可以写成如下形式:
进一步推广,所有经过  变换为
变换为  且
且  的路径(即
的路径(即  )也都可以写作:
)也都可以写作:
所以,定义前向递推概率和  :
:
对于一个长度为  的路径
的路径  ,其中
,其中  代表该路径前
代表该路径前  个字符,
个字符,  代表后
代表后  个字符。
个字符。
其中  表示前
表示前  个字符
个字符  经过
经过  变换为的
变换为的  的前半段子路径。
的前半段子路径。  代表了
代表了  时刻经过
时刻经过  的路径概率中
的路径概率中  概率之和,即前向递推概率和。
概率之和,即前向递推概率和。
由于当  时路径只能从blank或
时路径只能从blank或  开始,所以
开始,所以  有如下性质:
有如下性质:


如上面的例子中  ,
,  ,
,  。对于所有
。对于所有  路径,当
路径,当  时只能从blank和
时只能从blank和  字符开始。
字符开始。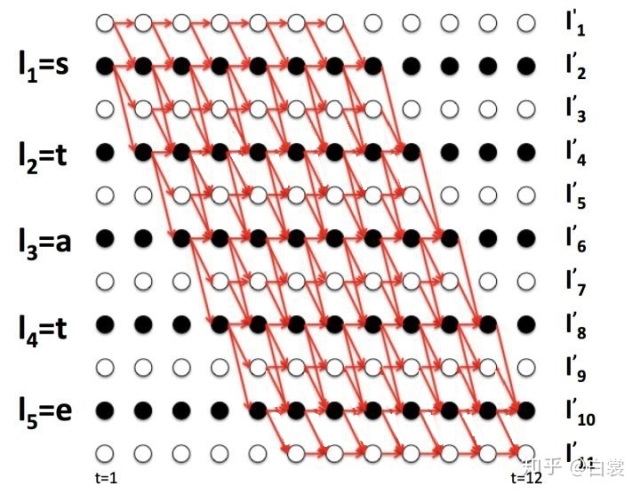 图16
图16
图16是  时经过压缩路径后能够变为
时经过压缩路径后能够变为  的所有路径
的所有路径  。观察图15会发现对于
。观察图15会发现对于  有如下递推关系:
有如下递推关系:
也就是说,如果  时刻是字符
时刻是字符  ,那么
,那么  时刻只可能是字符
时刻只可能是字符  三选一,否则经过
三选一,否则经过  变换后无法压缩成
变换后无法压缩成  。
。
那么更一般的:
同理,定义反向递推概率和  :
:
其中  表示后
表示后  个字符
个字符  经过
经过  变换为的
变换为的  的后半段子路径。
的后半段子路径。  代表了
代表了  时刻经过
时刻经过  的路径概率中
的路径概率中  概率之和,即反向递推概率和。
概率之和,即反向递推概率和。
由于当  时路径只能以blank或
时路径只能以blank或  结束,所以有如下性质:
结束,所以有如下性质:


如上面的例子中  ,
,  ,
,  ,
,  。对于所有
。对于所有  路径,当
路径,当  时只能以
时只能以  (blank字符)或
(blank字符)或  字符结束。
字符结束。
观察图15会发现对于  有如下递推关系
有如下递推关系
与  同理,对于
同理,对于  有如下递推关系:
有如下递推关系:
那么forward和backward相乘有:
或:
注意,  可以通过图16的关系对应,如
可以通过图16的关系对应,如  ,
, 。
。
对比  :
:
可以得到  与forward和backward递推公式之间的关系:
与forward和backward递推公式之间的关系:
* 为什么有上式  成立呢?
成立呢?
回到图15,为了方便分析,假设只有  共4条在
共4条在  时刻经过字符
时刻经过字符  且
且  变换为
变换为  的路径,即 :
的路径,即 :
那么此时(注意虽然表示路径用  加法,但是由于
加法,但是由于  和
和  两件独立事情同时发生,所以
两件独立事情同时发生,所以  路径的概率
路径的概率  是乘法):
是乘法):
则有: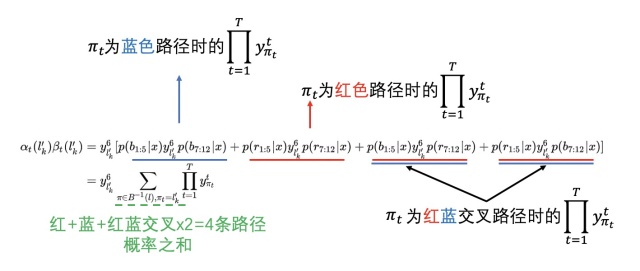
训练CTC
对于LSTM,有训练集合  ,其中
,其中  是图片经过CNN计算获得的Feature map,
是图片经过CNN计算获得的Feature map,  是图片对应的OCR字符label(label里面没有blank字符)。
是图片对应的OCR字符label(label里面没有blank字符)。
现在我们要做的事情就是:通过梯度 调整LSTM的参数
调整LSTM的参数 ,使得对于输入样本为
,使得对于输入样本为 时有
时有  取得最大。所以如何计算梯度才是核心。
取得最大。所以如何计算梯度才是核心。
单独来看CTC输入(即LSTM输出)  矩阵中的某一个值
矩阵中的某一个值  (注意
(注意  与
与  含义相同,都是在
含义相同,都是在  时
时  的概率):
的概率):
上式中的  是通过递推计算的常数,任何时候都可以通过递推快速获得,那么即可快速计算梯度
是通过递推计算的常数,任何时候都可以通过递推快速获得,那么即可快速计算梯度  ,之后梯度上升算法你懂的。
,之后梯度上升算法你懂的。
CTC编程接口
在Tensorflow中官方实现了CTC接口:
tf.nn.ctc_loss(labels,inputs,sequence_length,preprocess_collapse_repeated=False,ctc_merge_repeated=True,ignore_longer_outputs_than_inputs=False,time_major=True)
在Pytorch中需要使用针对框架编译的warp-ctc:https://github.com/SeanNaren/warp-ctc
2020.4更新,目前Pytorch已经有CTC接口:
torch.nn.CTCLoss(blank=0,reduction='mean',zero_infinity=False)
CTC总结
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。CTC特点:
- 引入blank字符,解决有些位置没有字符的问题
- 通过递推,快速计算梯度
看到这里你也应该大致了解MFCC+CTC在语音识别中的应用了(图17来源)。
图17 MFCC+CTC在语音识别中的应用
CRNN+CTC总结
这篇文章的核心,就是将CNN/LSTM/CTC三种方法结合:
- 首先CNN提取图像卷积特征
- 然后LSTM进一步提取图像卷积特征中的序列特征
- 最后引入CTC解决训练时字符无法对齐的问题
即提供了一种end2end文字图片识别算法,也算是方向的简单入门。
特别说明
一般情况下对一张图像中的文字进行识别需要以下步骤
- 定位文稿中的图片,表格,文字区域,区分文字段落(版面分析)
- 进行文本行识别(识别)
- 使用NLP相关算法对文字识别结果进行矫正(后处理)

若有收获,就点个赞吧
0 人点赞
