看到标题你是不是感到很熟悉,是面试中问过别人,还是看过很多面试题这个出现几率还是很高的,它对是你对浏览器渲染机制的以及相关知识的全面的一个考察,但是很少有同学能够很好的回答好这个问题。
**
一旦问这个问题的话,我觉得肯定是一个非常深的问题了,无论从深度还是广度上,要真的答好这个题目,或者梳理清楚的话,挺难的,毕竟一个非常综合性的问题,我作为一个刚刚入门的小白,只能梳理部分知识,更深的知识可以去看看参考链接。
那么我们就开始吧,假设你输入的内容是👇[https://baidu.com](https://baidu.com)
网络请求
1. 构建请求
首先,浏览器构建「请求行」信息(如下所示),构建好后,浏览器准备发起网络请求👇GET / HTTP1.1
GET是请求方法,路径就是根路径,HTTP协议版本1.1
2. 查找缓存
在真正发起网络请求之前,浏览器会先在浏览器缓存中查询是否有要请求的文件。
先检查强缓存,如果命中的话直接使用,否则进入下一步,强缓存的知识点,上面👆梳理过了。
3. DNS解析
输入的域名的话,我们需要根据域名去获取对应的ip地址。 这个过程需要依赖一个服务系统,叫做是DNS域名解析, 从查找到获取到具体IP的过程叫做是DNS解析。
关于DNS篇,可以看看阮一峰的网络日志
首先,浏览器提供了DNS数据缓存功能,如果一个域名已经解析过了,那么就会把解析的结果缓存下来,下次查找的话,直接去缓存中找,不需要结果DNS解析。
「解析过程总结如下」👇
- 「首先查看是否有对应的域名缓存,有的话直接用缓存的ip访问」
ipconfig /displaydns
// 输入这个命令就可以查看对应的电脑中是否有缓存
- 「如果缓存中没有,则去查找hosts文件」 一般在
c:\windows\system32\drivers\etc\hosts - 如果hosts文件里没找到想解析的域名,则将「域名发往自己配置的dns服务器」,也叫「本地dns服务器」。
ipconfig/all
通过这个命令可以查看自己的本地dns服务器
如果「本地dns服务器有相应域名的记录」,则返回记录。
电脑的dns服务器一般是各大运营商如电信联通提供的,或者像180.76.76.76,223.5.5.5,4个114等知名dns服务商提供的,本身缓存了大量的常见域名的ip,所以常见的网站,都是有记录的。不需要找根服务器。
如果电脑自己的服务器没有记录,会去找根服务器。根服务器全球只要13组,回去找其中之一,找了根服务器后,「根服务器会根据请求的域名,返回对应的“顶级域名服务器”」,如:
- 「顶级域服务器收到请求,会返回二级域服务器的地址」
- 比如一个网址是
www.xxx.edu.cn,则顶级域名服务器再转发给负责.edu.cn域的二级服务器
- 比如一个网址是
- 「以此类推,最终会发到负责锁查询域名的,最精确的那台dns,可以得到查询结果。」
- 最后一步,「本地dns服务器,把最终的解析结果,返回给客户端,对客户端来讲,只是一去一回的事,客户端并不知道本地dns服务器经过了千山万水。」
建立TCP链接
我们所了解的就是👉Chrome 在同一个域名下要求同时最多只能有 6 个 TCP 连接,超过 6 个的话剩下的请求就得等待。
那么我们假设不需要等待,我们进入了TCP连接的建立阶段。
建立TCP连接经历下面三个阶段:
- 通过「三次握手」建立客户端和服务器之间的连接。
- 进行数据传输。
- 断开连接的阶段。数据传输完成,现在要断开连接了,通过「四次挥手」来断开连接。
从上面看得出来,TCP 连接通过什么手段来保证数据传输的可靠性,一是三次握手确认连接,二是数据包校验保证数据到达接收方,三是通过四次挥手断开连接。
深入理解的话,可以看看对应的文章,掘金上面很多文章都有深入了解,这里就不梳理了。
发送HTTP请求
TCP连接完成后,接下来就可以与服务器通信了,也就是我们经常说的发送HTTP请求。
发送HTTP请求的话,需要携带三样东西:「请求行」,「请求头」,「请求体」。
我们看看大概是是什么样子的吧👇
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3Accept-Encoding: gzip, deflate, brAccept-Language: zh-CN,zh;q=0.9Cache-Control: no-cacheConnection: keep-aliveCookie: /* 省略cookie信息 */Host: juejin.imPragma: no-cacheUpgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36
最后就是请求体,请求体的话只有在POST请求场景下存在,常见的就是表单提交
网络响应
HTTP 请求到达服务器,服务器进行对应的处理。最后要把数据传给浏览器,也就是通常我们说的返回网络响应。
跟请求部分类似,网络响应具有三个部分:「响应行」、「响应头」和「响应体」。
响应行类似下面这样👇HTTP/1.1 200 OK
对应的响应头数据是怎么样的呢?我们来举个例子看看👇
Access-Control-Max-Age: 86400Cache-control: privateConnection: closeContent-Encoding: gzipContent-Type: text/html;charset=utf-8Date: Wed, 22 Jul 2020 13:24:49 GMTVary: Accept-EncodingSet-Cookie: ab={}; path=/; expires=Thu, 22 Jul 2021 13:24:49 GMT; secure; httponlyTransfer-Encoding: chunked
接下来,我们数据拿到了,你认为就会断开TCP连接吗?
这个的看响应头中的Connection字段。上面的字段值为close,那么就会断开,一般情况下,HTTP1.1版本的话,通常请求头会包含「Connection: Keep-Alive」表示建立了持久连接,这样TCP连接会一直保持,之后请求统一站点的资源会复用这个连接。
上面的情况就会断开TCP连接,请求-响应流程结束。
到这里的话,网络请求就告一段落了,接下来的内容就是渲染流程了👇
渲染阶段
较为专业的术语总结为以下阶段:
- 构建DOM树
- 样式计算
- 布局阶段
- 分层
- 绘制
- 分块
- 光栅化
- 合成
渲染流程
首先要了解的概念:
- 渲染引擎:它是浏览器最核心的部分是 “Rendering Engine”,不过我们一般习惯将之称为 “浏览器内核”
- 渲染引擎主要包括的线程:
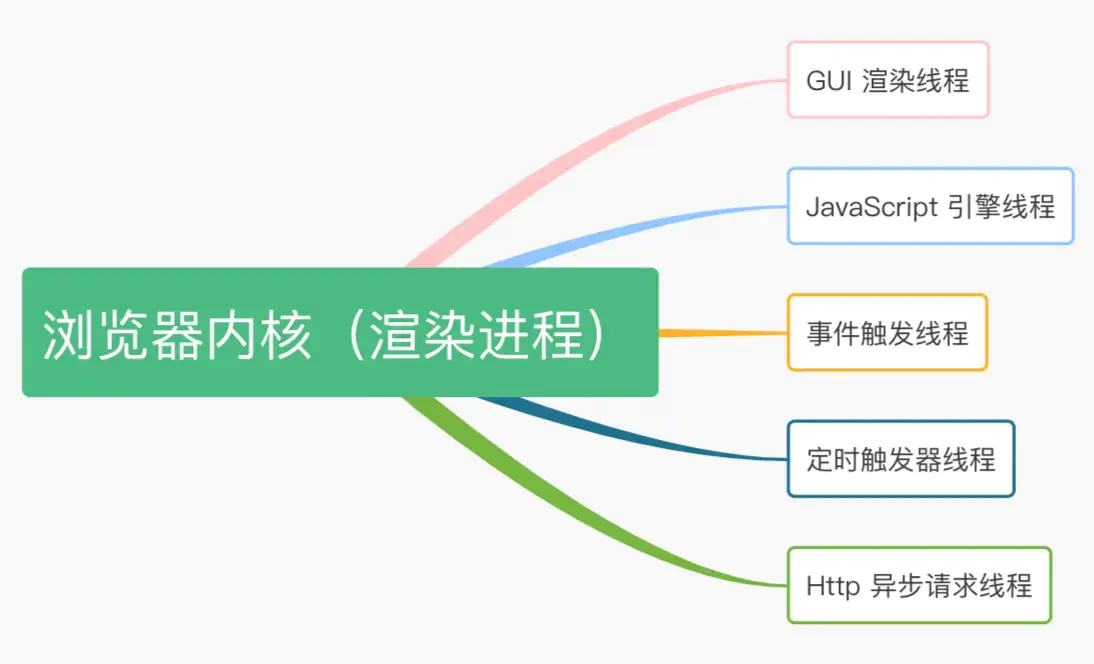
- 各个线程主要职责
- GUI渲染线程:GUI 渲染线程负责渲染浏览器界面,解析 HTML,CSS,构建 DOM 树和 RenderObject 树,布局和绘制等。当界面需要重绘(Repaint)或由于某种操作引发回流(Reflow)时,该线程就会执行。
- JavaScript引擎线程: JavaScript 引擎线程主要负责解析 JavaScript 脚本并运行相关代码。 JavaScript 引擎在一个Tab页(Renderer 进程)中无论什么时候都只有一个 JavaScript 线程在运行 JavaScript 程序。需要提起一点就是,GUI线程与JavaScript引擎线程是互斥的,这也是就是为什么JavaScript操作时间过长,会造成页面渲染不连贯,导致页面出现阻塞的原理。
- 事件触发线程:当一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待 JavaScript 引擎的处理。 通常JavaScript引擎是单线程的,所以这些事件都会排队等待JS执行。
- 定时器触发器: 我们日常使用的setInterval 和 setTimeout 就在该线程中,原因可能就是:由于JS引擎是单线程的,如果处于阻塞线程状态就会影响记时的准确,所以需要通过单独的线程来记时并触发响应的事件这样子更为合理。
- Http请求线程: 在 XMLHttpRequest 在连接后是通过浏览器新开一个线程请求,这个线程就Http请求线程,它 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件放到 JavaScript 引擎的处理队列中等待处理。
以上来自阿宝哥总结:你不知道的 Web Workers (上)[7.8K 字 | 多图预警]
有了上述的概念,对接下我们讲渲染流水线会有所帮助
简略版的渲染机制
很久之前就把浏览器工作原理读完了,看了很多博客,文章,当时简简单单的梳理一些内容,如下👇
简略版渲染机制一般分为以下几个步骤
- 处理 HTML 并构建 DOM 树。
- 处理 CSS 构建 CSSOM 树。
- 将 DOM 与 CSSOM 合并成一个渲染树。
- 根据渲染树来布局,计算每个节点的位置。
- 调用 GPU 绘制,合成图层,显示在屏幕上。
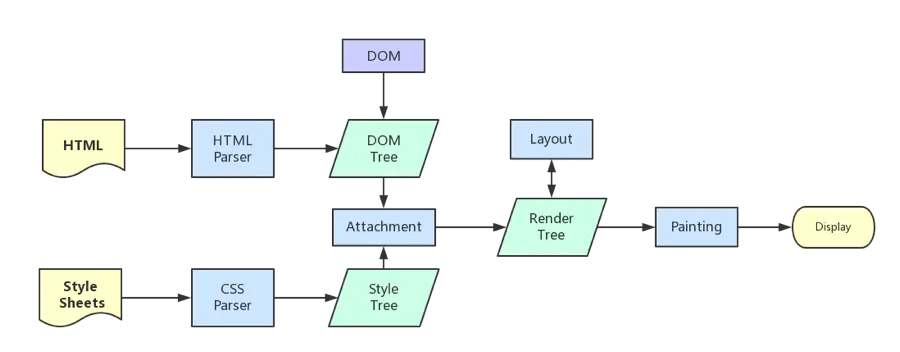
接下来大概就是这么说:
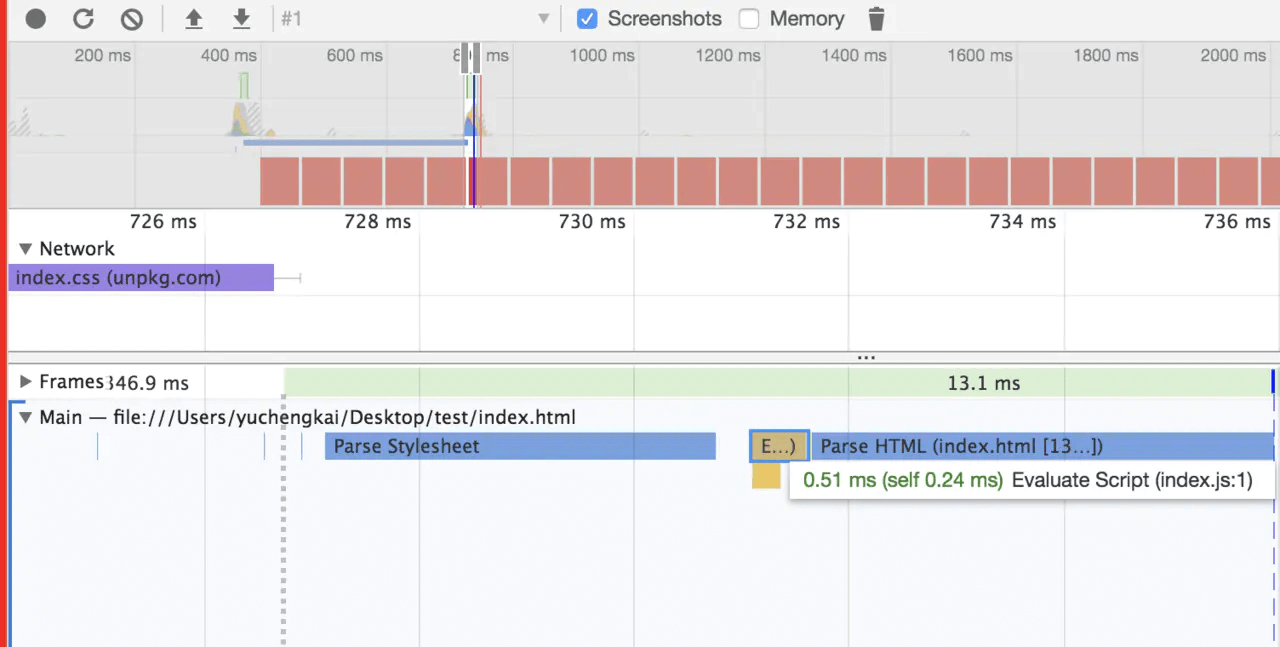
在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM 树构建完成。并且构建 CSSOM 树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的 CSS 选择器,执行速度越慢。
当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM。
说完这些,记下来就讲几个面试常常会提起的,会问你的知识点👇
Load 和 DOMContentLoaded 区别
Load 事件触发代表页面中的 DOM,CSS,JS,图片已经全部加载完毕。
DOMContentLoaded 事件触发代表初始的 HTML 被完全加载和解析,不需要等待 CSS,JS,图片加载。
图层
一般来说,可以把普通文档流看成一个图层。特定的属性可以生成一个新的图层。不同的图层渲染互不影响,所以对于某些频繁需要渲染的建议单独生成一个新图层,提高性能。但也不能生成过多的图层,会引起反作用。
通过以下几个常用属性可以生成新图层
- 3D 变换:
translate3d、translateZ will-changevideo、iframe标签- 通过动画实现的
opacity动画转换 -
重绘(Repaint)和回流(Reflow)
重绘和回流是渲染步骤中的一小节,但是这两个步骤对于性能影响很大。
重绘是当节点需要更改外观而不会影响布局的,比如改变
color就叫称为重绘- 回流是布局或者几何属性需要改变就称为回流。
回流必定会发生重绘,重绘不一定会引发回流。回流所需的成本比重绘高的多,改变深层次的节点很可能导致父节点的一系列回流。
所以以下几个动作可能会导致性能问题:
- 改变 window 大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
很多人不知道的是,重绘和回流其实和 Event loop 有关。
- 当 Event loop 执行完 Microtasks 后,会判断 document 是否需要更新。因为浏览器是 60Hz 的刷新率,每 16ms 才会更新一次。
- 然后判断是否有
resize或者scroll,有的话会去触发事件,所以resize和scroll事件也是至少 16ms 才会触发一次,并且自带节流功能。 - 判断是否触发了 media query
- 更新动画并且发送事件
- 判断是否有全屏操作事件
- 执行
requestAnimationFrame回调 - 执行
IntersectionObserver回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好 - 更新界面
- 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行
requestIdleCallback回调。
以上内容来自于 HTML 文档
减少重绘和回流
使用
translate替代top<div class="test"></div><style>.test {position: absolute;top: 10px;width: 100px;height: 100px;background: red;}</style><script>setTimeout(() => {// 引起回流document.querySelector('.test').style.top = '100px'}, 1000)</script>复制代码
使用
visibility替换display: none,因为前者只会引起重绘,后者会引发回流(改变了布局)- 把 DOM 离线后修改,比如:先把 DOM 给
display:none(有一次 Reflow),然后你修改100次,然后再把它显示出来 不要把 DOM 结点的属性值放在一个循环里当成循环里的变量
for(let i = 0; i < 1000; i++) {// 获取 offsetTop 会导致回流,因为需要去获取正确的值console.log(document.querySelector('.test').style.offsetTop)}复制代码
不要使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局
- 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用
requestAnimationFrame - CSS 选择符从右往左匹配查找,避免 DOM 深度过深
- 将频繁运行的动画变为图层,图层能够阻止该节点回流影响别的元素。比如对于
video标签,浏览器会自动将该节点变为图层。
详细版的渲染机制
较为专业的术语总结为以下阶段:
- 构建DOM树
- 样式计算
- 布局阶段
- 分层
- 绘制
- 分块
- 光栅化
- 合成
你可以想象一下,从0,1字节流到最后页面展现在你面前,这里面渲染机制肯定很复杂,所以渲染模块把执行过程中化为很多的子阶段,渲染引擎从网络进程拿到字节流数据后,经过这些子阶段的处理,最后输出像素,这个过程可以称为渲染流水线 ,我们从一张图上来看👇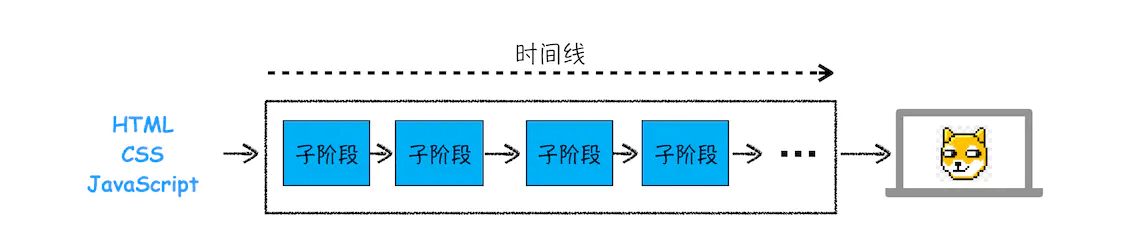
那接下来就从每个阶段来梳理一下大致过程。
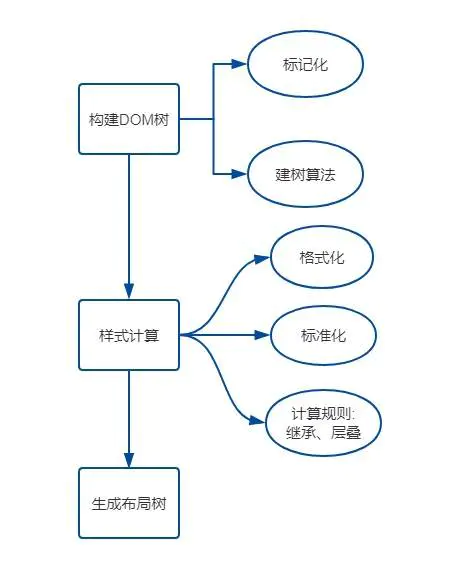
构建DOM树
这个过程主要工作就是讲HTML内容转换为浏览器DOM树结构
- 字节→字符→令牌→节点→对象模型(DOM)
文档对象模型(DOM)
<html><head><meta name="viewport" content="width=device-width,initial-scale=1"><link href="style.css" rel="stylesheet"><title>Critical Path</title></head><body><p>Hello <span>web performance</span> students!</p><div><img src="awesome-photo.jpg"></div></body></html>复制代码
我们先看看数据是怎么样转换的👇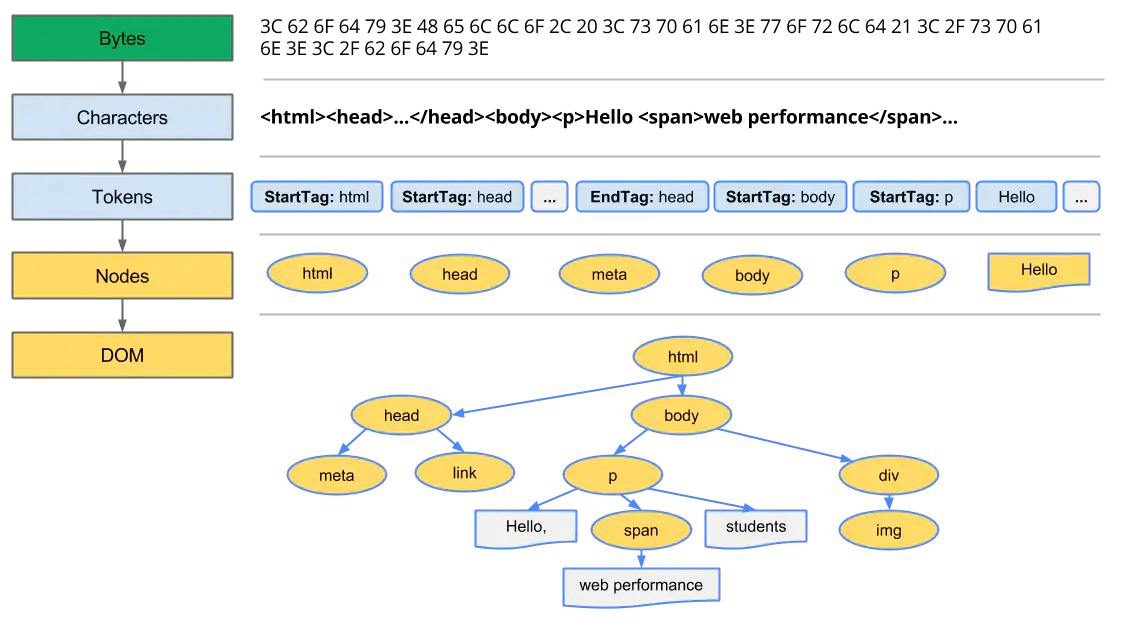
大概过程:
- 转换:浏览器从磁盘或网络读取 HTML 的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成各个字符。
- 令牌化:浏览器将字符串转换成 W3C HTML5 标准规定的各种令牌,例如,“”、“”,以及其他尖括号内的字符串。每个令牌都具有特殊含义和一组规则。
- 词法分析:发出的令牌转换成定义其属性和规则的“对象”。
- DOM构建:最后,由于 HTML 标记定义不同标记之间的关系(一些标记包含在其他标记内),创建的对象链接在一个树数据结构内,此结构也会捕获原始标记中定义的父项-子项关系:HTML 对象是 body 对象的父项,body 是 paragraph 对象的父项,依此类推。
样式计算
这个子阶段主要有三个步骤
- 格式化样式表
- 标准化样式表
- 计算每个DOM节点具体样式
格式化样式表
我们拿到的也就是0,1字节流数据,浏览器无法直接去识别的,所以渲染引擎收到CSS文本数据后,会执行一个操作,转换为浏览器可以理解的结构-styleSheets
如果你很想了解这个格式化的过程,可以好好去研究下,不同的浏览器可能在CSS格式化过程中会有所不同,在这里就不展开篇幅了。
通过浏览器的控制台document.styleSheets可以来查看这个最终结果。通过JavaScript可以完成查询和修改功能,或者说这个阶段为后面的样式操作提供基石。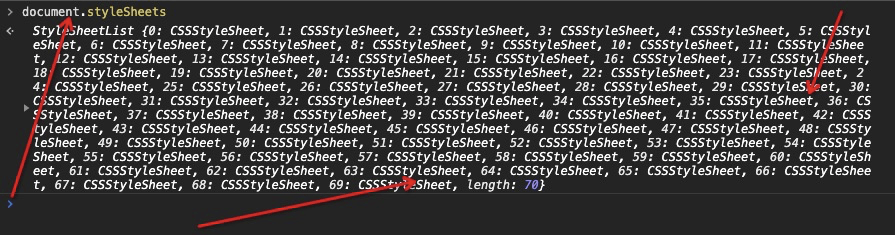
标准化样式表
什么是标准化样式表呢?先看一段CSS文本👇
有些时候,我们写CSS 样式的时候,会写body { font-size: 2em }p {color:blue;}span {display: none}div {font-weight: bold}div p {color:green;}div {color:red; }复制代码
font-size:2em;color:red;font-weight:bold,像这些数值并不容易被渲染引擎所理解,因此需要在计算样式之前将它们标准化,如em->px,red->rgba(255,0,0,0),bold->700等等。
上面的代码标准后属性值是什么样子呢👇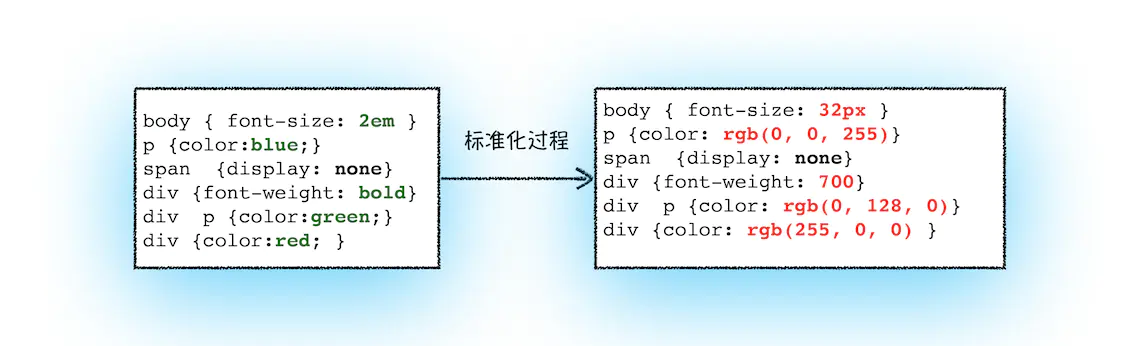
计算每个DOM节点具体样式
通过格式化和标准化,接下来就是计算每个节点具体样式信息了。
计算规则:继承和层叠继承:每个子节点会默认去继承父节点的样式,如果父节点中找不到,就会采用浏览器默认的样式,也叫UserAgent样式。层叠:样式层叠,是CSS一个基本特征,它定义如何合并来自多个源的属性值的算法。某种意义上,它处于核心地位,具体的层叠规则属于深入 CSS 语言的范畴,这里就补展开篇幅说了。
不过值得注意的是,在计算完样式之后,所有的样式值会被挂在到window.getComputedStyle当中,也就是可以通过JS来获取计算后的样式,非常方便。
这个阶段,完成了DOM节点中每个元素的具体样式,计算过程中要遵循CSS的继承和层叠两条规则,最终输出的内容是每个节点DOM的样式,被保存在ComputedStyle中。
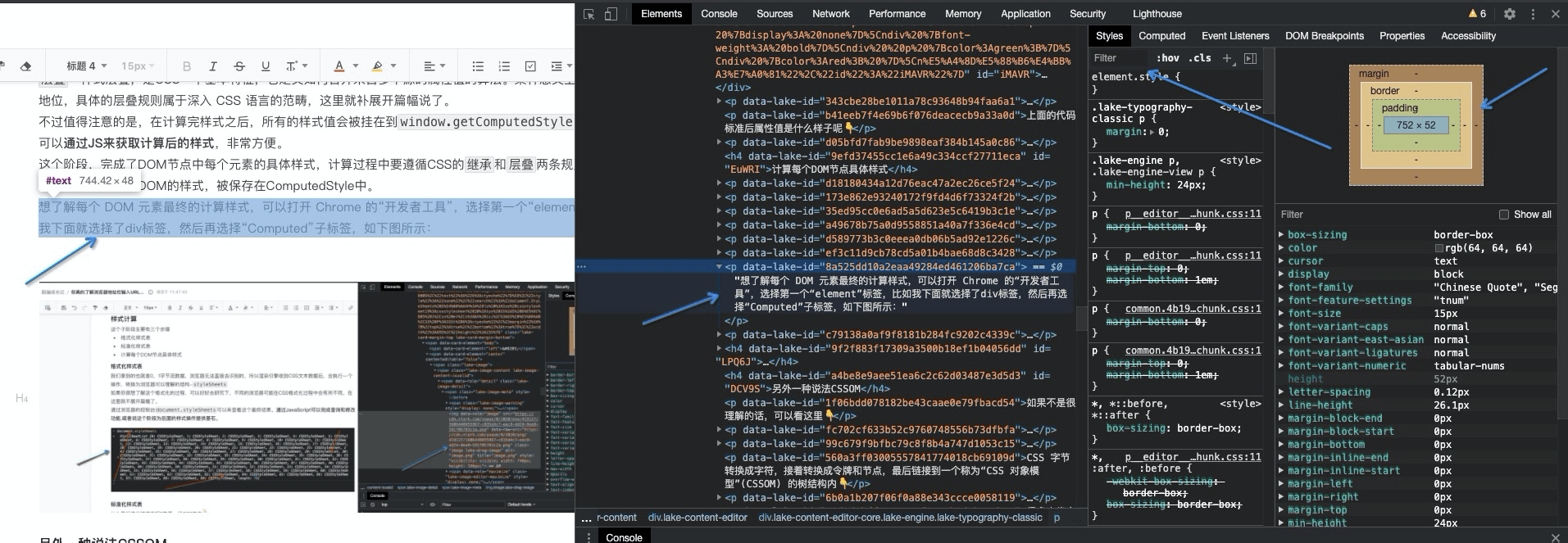
想了解每个 DOM 元素最终的计算样式,可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,比如我下面就选择了div标签,然后再选择“Computed”子标签,如下图所示:
另外一种说法CSSOM
如果不是很理解的话,可以看这里👇
跟处理HTML一样,我们需要更具CSS两个规则:继承和层叠转换成某种浏览器能理解和处理的东西,处理过程类似处理HTML,如上图☝
CSS 字节转换成字符,接着转换成令牌和节点,最后链接到一个称为“CSS 对象模型”(CSSOM) 的树结构内👇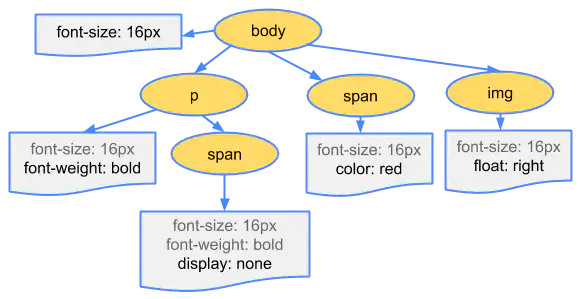
很多人肯定看这个很熟悉,确实,很多博客都是基于CSSOM说法来讲的,我要说的是:
和DOM不一样,源码中并没有CSSOM这个词,所以很多文章说的CSSOM应该就是styleSheets,当然了这个styleSheets我们可以打印出来的
很多文章说法是渲染树也是16年前的说法,现在代码重构了,我们可以把LayoutTree看成是渲染树,不过它们之间还是有些区别的。
生成布局树
上述过程已经完成DOM树(DOM树)构建,以及样式计算(DOM样式),接下来就是要通过浏览器的布局系统确定元素位置,也就是生成一颗布局树(Layout Tree),之前说法叫 渲染树。
创建布局树
- 在DOM树上不可见的元素,head元素,meta元素等,以及使用display:none属性的元素,最后都不会出现在布局树上,所以浏览器布局系统需要额外去构建一棵只包含可见元素布局树。
- 我们直接结合图来看看这个布局树构建过程:
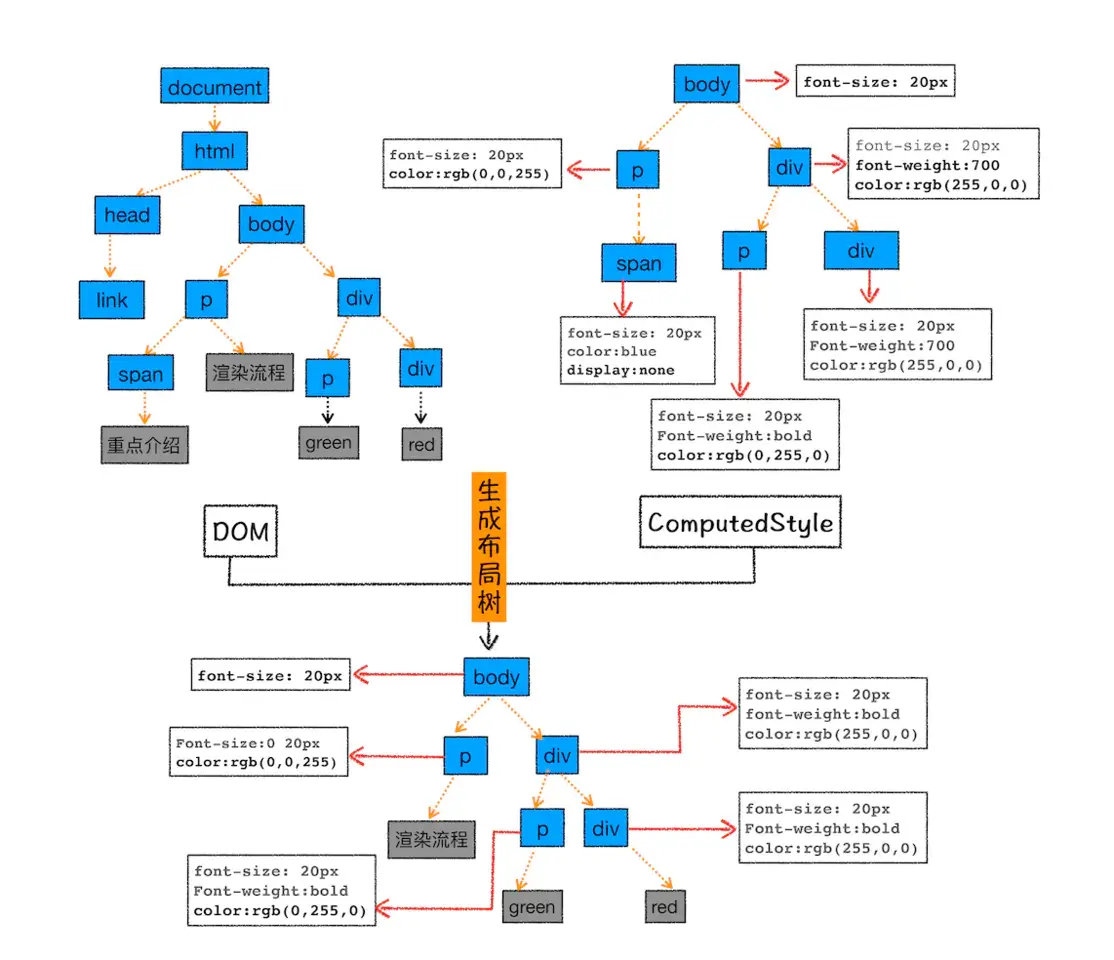 为了构建布局树,浏览器布局系统大体上完成了下面这些工作:
为了构建布局树,浏览器布局系统大体上完成了下面这些工作:
- 遍历DOM树可见节点,并把这些节点加到布局树中
对于不可见的节点,head,meta标签等都会被忽略。对于body.p.span 这个元素,它的属性包含display:none,所以这个元素没有被包含进布局树。
布局计算
接下来就是要计算布局树节点的坐标位置,布局的计算过程非常复杂,张开介绍的话,会显得文章过于臃肿,大多数情况下,我们只需要知道它所做的工作是什么,想知道它是如何做的话,可以看看以下两篇文章👇
人人FED团队的文章-从Chrome源码看浏览器如何layout布局
梳理前三个阶段
分层
生成图层树(Layer Tree)
- 拥有层叠上下文属性的元素会被提升为单独一层
- 需要裁剪(clip)的地方也会创建图层
- 图层绘制
首先需要知道的就是,浏览器在构建完布局树后,还需要进行一系列操作,这样子可能考虑到一些复杂的场景,比如一些些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,还有比如是含有层叠上下文如何控制显示和隐藏等情况。
生成图层树
你最终看到的页面,就是由这些图层一起叠加构成的,它们按照一定的顺序叠加在一起,就形成了最终的页面。
浏览器的页面实际上被分成了很多图层,这些图层叠加后合成了最终的页面。
我们来看看图层与布局树之间关系,如下图👇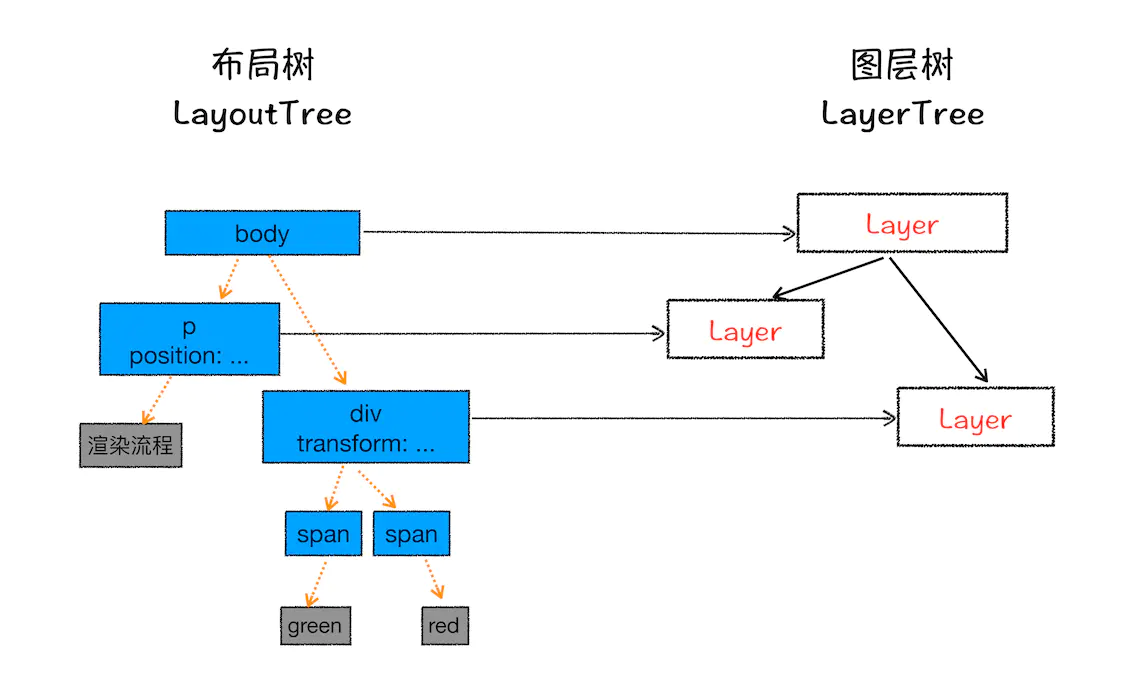
通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。
那什么情况下,渲染引擎会为特定的节点创建新图层呢?
有两种情况需要分别讨论,一种是显式合成,一种是隐式合成。
显式合成
一、 拥有层叠上下文的节点。
层叠上下文也基本上是有一些特定的CSS属性创建的,一般有以下情况:
- HTML根元素本身就具有层叠上下文。
- 普通元素设置position不为static并且设置了z-index属性,会产生层叠上下文。
- 元素的 opacity 值不是 1
- 元素的 transform 值不是 none
- 元素的 filter 值不是 none
- 元素的 isolation 值是isolate
- will-change指定的属性值为上面任意一个。(will-change的作用后面会详细介绍)
二、需要剪裁(clip)的地方。
比如一个标签很小,5050像素,你在里面放了非常多的文字,那么超出的文字部分就需要被剪裁。当然如果出现了滚动条,那么滚动条也会被单独提升为一个图层,如下图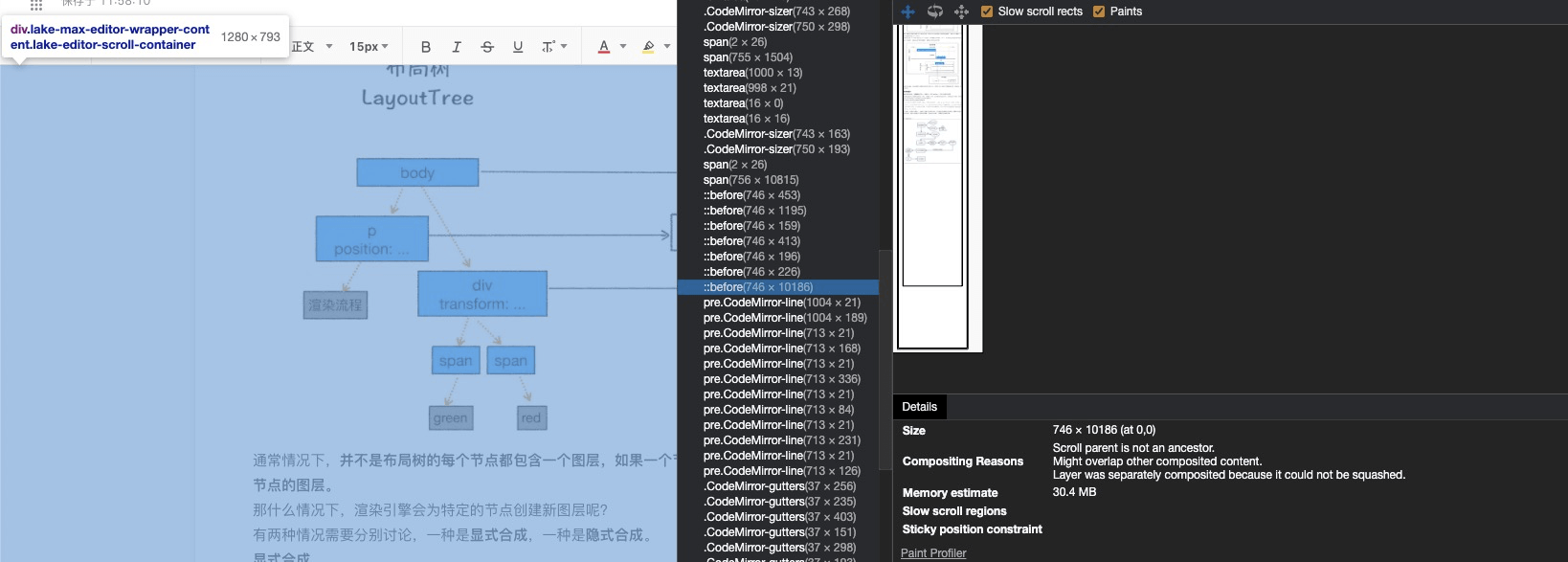
数字1箭头指向的地方,可以看看,可能效果不是很明显,大家可以自己打开这个Layers探索下。
元素有了层叠上下文的属性或者需要被剪裁,满足其中任意一点,就会被提升成为单独一层。
隐式合成
这是一种什么样的情况呢,通俗意义上来说,就是z-index比较低的节点会提升为一个单独的途图层,那么层叠等级比它高的节点都会成为一个独立的图层。
浏览器渲染流程&Composite(渲染层合并)简单总结
*缺点: 根据上面的文章来说,在一个大型的项目中,一个z-index比较低的节点被提升为单独图层后,层叠在它上面的元素统统都会提升为单独的图层,我们知道,上千个图层,会增大内存的压力,有时候会让页面崩溃。这就是层爆炸
绘制
完成了图层的构建,接下来要做的工作就是图层的绘制了。图层的绘制跟我们日常的绘制一样,每次都会把一个复杂的图层拆分为很小的绘制指令,然后再按照这些指令的顺序组成一个绘制列表,类似于下图👇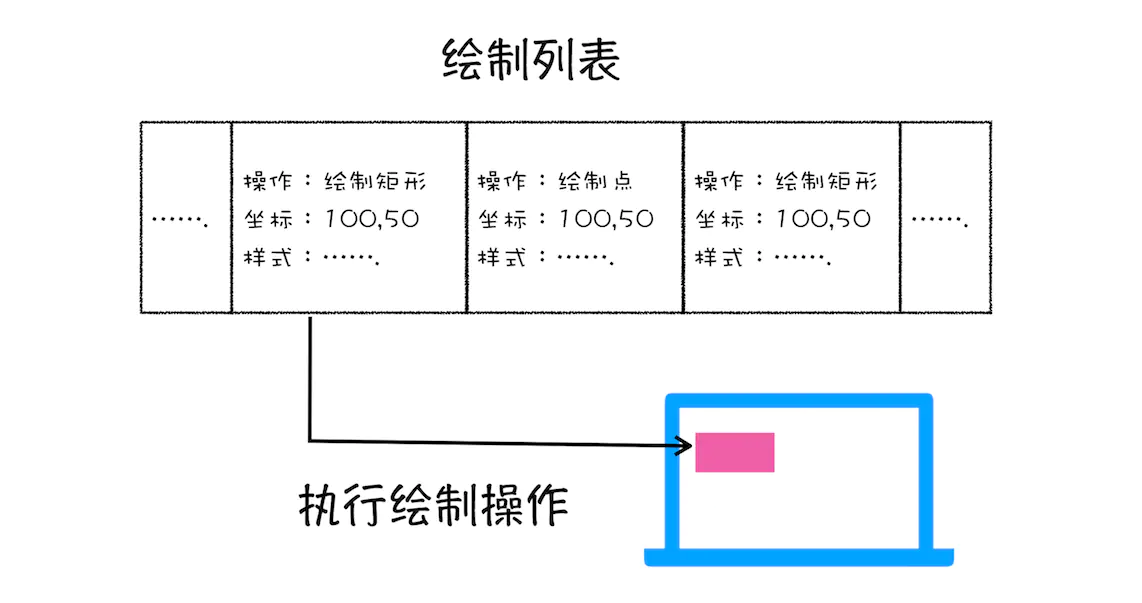
从图中可以看出,绘制列表中的指令其实非常简单,就是让其执行一个简单的绘制操作,比如绘制粉色矩形或者黑色的线等。而绘制一个元素通常需要好几条绘制指令,因为每个元素的背景、前景、边框都需要单独的指令去绘制。
在图层绘制中,每个图层的绘制会拆分成很多小的指令,然后再把这些指令按照顺序组成一个待绘制的列表。具体的指令你可以打开控制台选择layers然后展开document,点击paint profiler即可查看到绘制流程。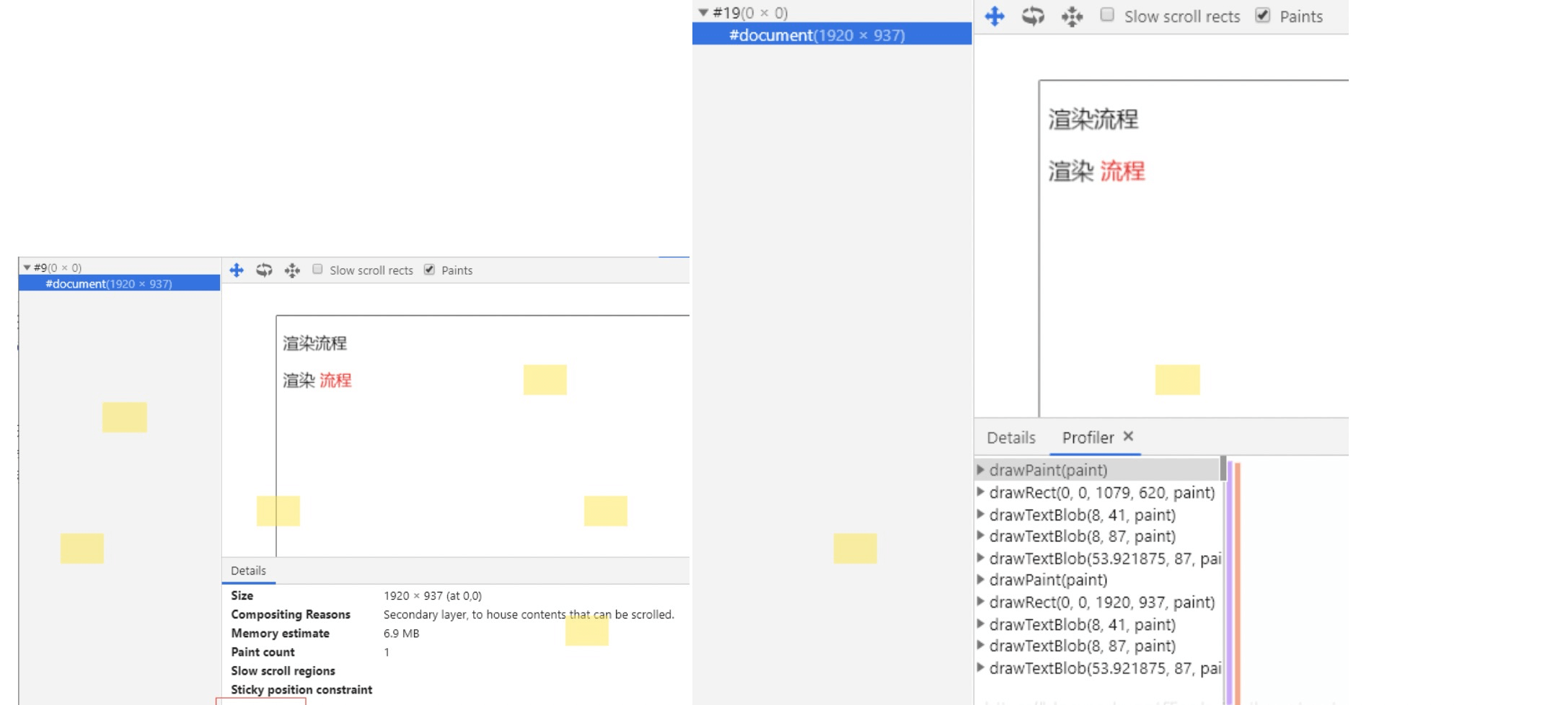
大家可以在 Chrome 开发者工具中在设置栏中展开 more tools, 然后选择Layers面板,就能看到下面的绘制列表: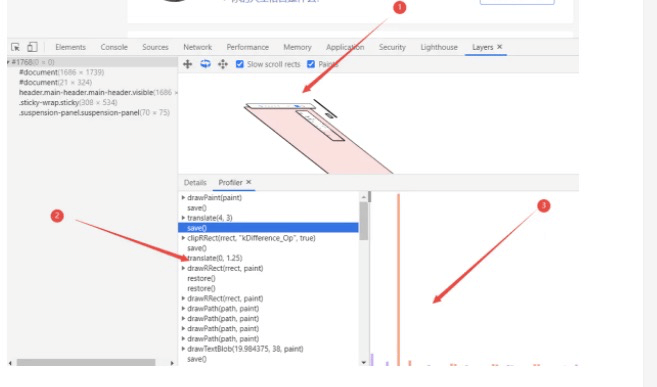
在该图中,箭头2指向的区域 就是 document 的绘制列表,箭头3指向的拖动区域 中的进度条可以重现列表的绘制过程。
当然了,绘制图层的操作在渲染进程中有着专门的线程,这个线程叫做合成线程。
分块
- 接下来我们就要开始绘制操作了,实际上在渲染进程中绘制操作是由专门的线程来完成的,这个线程叫合成线程。
绘制列表准备好了之后,渲染进程的主线程会给
合成线程发送commit消息,把绘制列表提交给合成线程。接下来就是合成线程一展宏图的时候啦。你想呀,有时候,你的图层很大,或者说你的页面需要使用滚动条,然后页面的内容太多,多的无法想象,这个时候需要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
基于上面的原因,合成线程会讲图层划分为图块(tile)
- 这些块的大小一般不会特别大,通常是 256 256 或者 512 512 这个规格。这样可以大大加速页面的首屏展示。
首屏渲染加速可以这么理解:
因为后面图块(非视口内的图块)数据要进入 GPU 内存,考虑到浏览器内存上传到 GPU 内存的操作比较慢,即使是绘制一部分图块,也可能会耗费大量时间。针对这个问题,Chrome 采用了一个策略: 在首次合成图块时只采用一个低分辨率的图片,这样首屏展示的时候只是展示出低分辨率的图片,这个时候继续进行合成操作,当正常的图块内容绘制完毕后,会将当前低分辨率的图块内容替换。这也是 Chrome 底层优化首屏加载速度的一个手段。
光栅化
接着上面的步骤,有了图块之后,合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。
- 图块是栅格化执行的最小单位
- 渲染进程中专门维护了一个栅格化线程池,专门负责把图块转换为位图数据
- 合成线程会选择视口附近的图块(tile),把它交给栅格化线程池生成位图
- 生成位图的过程实际上都会使用 GPU 进行加速,生成的位图最后发送给
合成线程
运行方式如下👇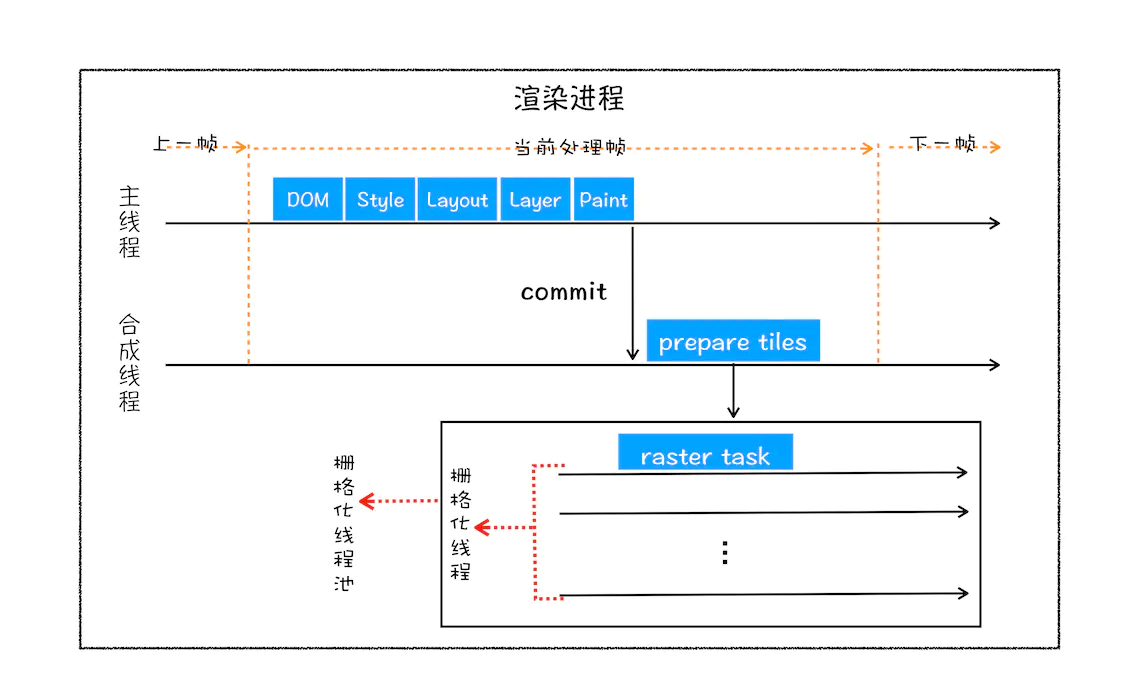
通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
相信你还记得,GPU 操作是运行在 GPU 进程中,如果栅格化操作使用了 GPU,那么最终生成位图的操作是在 GPU 中完成的,这就涉及到了跨进程操作。具体形式你可以参考下图: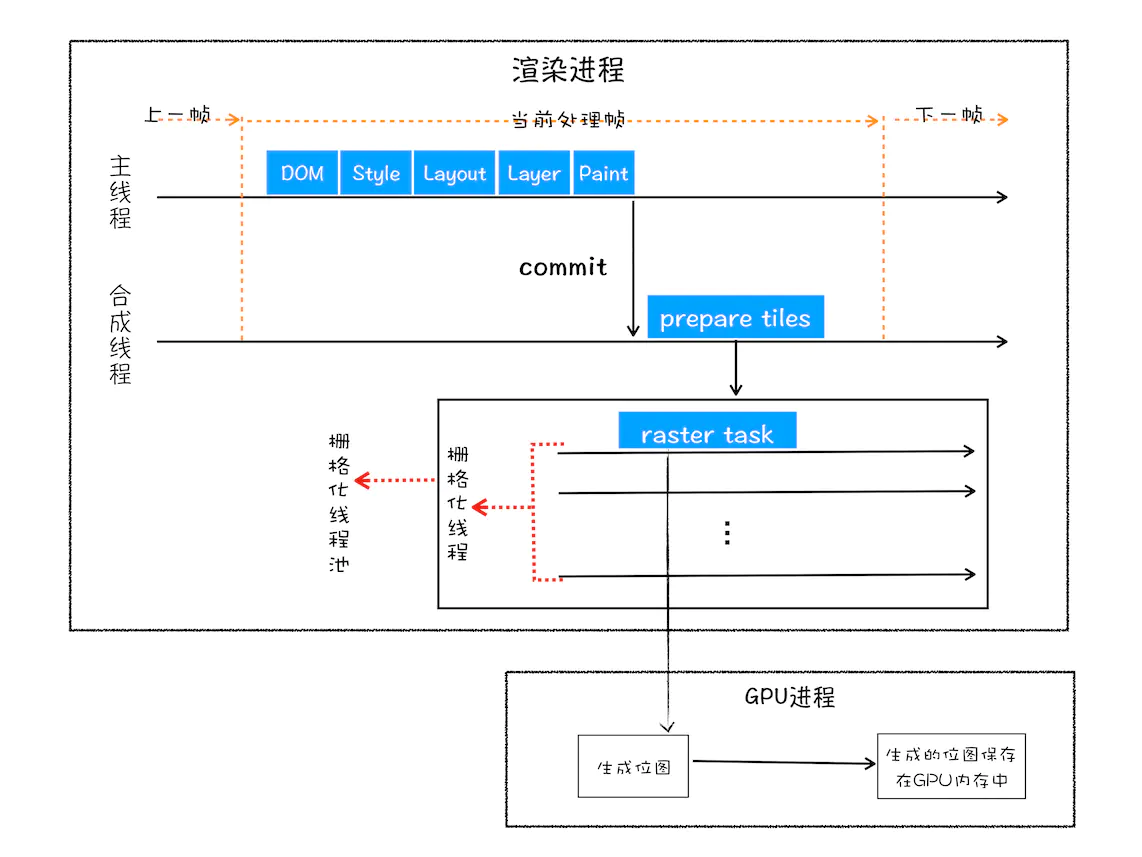
从图中可以看出,渲染进程把生成图块的指令发送给 GPU,然后在 GPU 中执行生成图块的位图,并保存在 GPU 的内存中。
合成和显示
栅格化操作完成后,合成线程会生成一个绘制命令,即”DrawQuad”,并发送给浏览器进程。
浏览器进程中的viz组件接收到这个命令,根据这个命令,把页面内容绘制到内存,也就是生成了页面,然后把这部分内存发送给显卡,那你肯定对显卡的原理很好奇。
看了某博主对显示器显示图像的原理解释:
无论是 PC 显示器还是手机屏幕,都有一个固定的刷新频率,一般是 60 HZ,即 60 帧,也就是一秒更新 60 张图片,一张图片停留的时间约为 16.7 ms。而每次更新的图片都来自显卡的前缓冲区。而显卡接收到浏览器进程传来的页面后,会合成相应的图像,并将图像保存到后缓冲区,然后系统自动将
前缓冲区和后缓冲区对换位置,如此循环更新。
这个时候,心中就有点概念了,比如某个动画大量占用内存时,浏览器生成图像的时候会变慢,图像传送给显卡就会不及时,而显示器还是以不变的频率刷新,因此会出现卡顿,也就是明显的掉帧现象。
用一张图来总结👇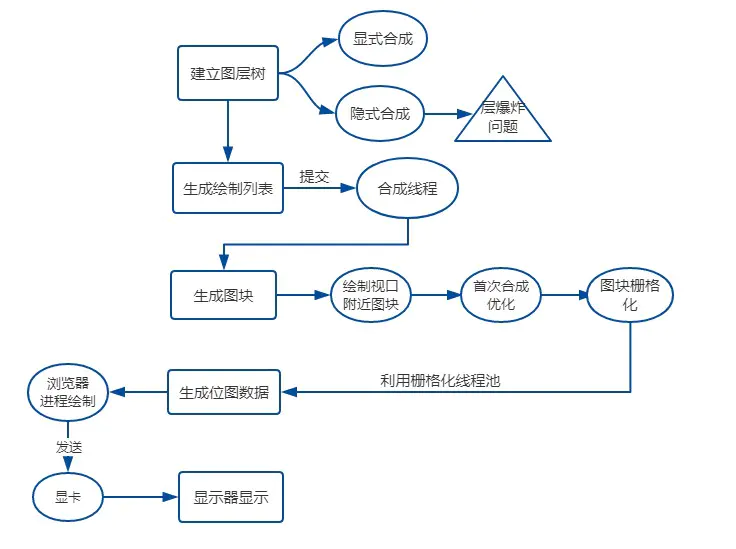
我们把上面整个的渲染流水线,用一张图片更直观的表示👇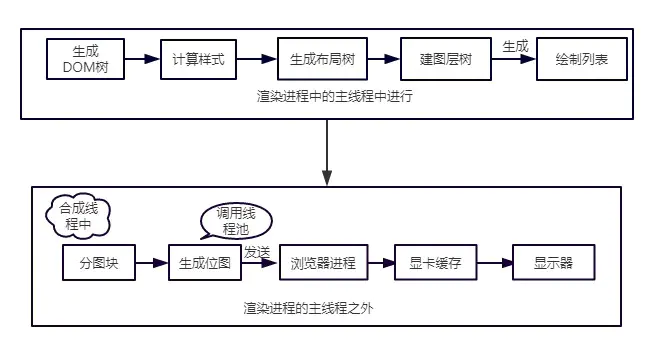
回流-重绘-合成
更新视图三种方式
- 一个 DOM 元素的几何属性变化,常见的几何属性有
width、height、padding、margin、left、top、border等等, 这个很好理解。 - 使 DOM 节点发生
增减或者移动。 - 读写
offset族、scroll族和client族属性的时候,浏览器为了获取这些值,需要进行回流操作。 - 调用
window.getComputedStyle方法。
一些常用且会导致回流的属性和方法:
clientWidth、clientHeight、clientTop、clientLeftoffsetWidth、offsetHeight、offsetTop、offsetLeftscrollWidth、scrollHeight、scrollTop、scrollLeftscrollIntoView()、scrollIntoViewIfNeeded()getComputedStyle()getBoundingClientRect()scrollTo()
依照上面的渲染流水线,触发回流的时候,如果 DOM 结构发生改变,则重新渲染 DOM 树,然后将后面的流程(包括主线程之外的任务)全部走一遍。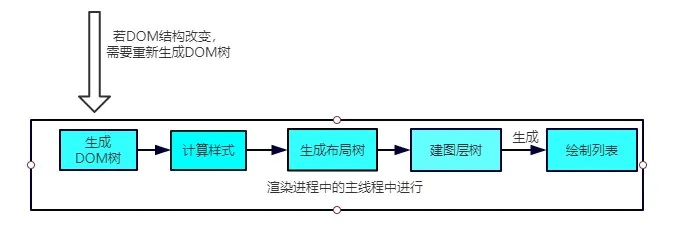
重绘
当页面中元素样式的改变并不影响它在文档流中的位置时(例如:color、background-color、visibility等),浏览器会将新样式赋予给元素并重新绘制它,这个过程称为重绘。
根据概念,我们知道由于没有导致 DOM 几何属性的变化,因此元素的位置信息不需要更新,从而省去布局的过程,流程如下:
跳过了布局树和建图层树,直接去绘制列表,然后在去分块,生成位图等一系列操作。
可以看到,重绘不一定导致回流,但回流一定发生了重绘。
合成
还有一种情况:就是更改了一个既不要布局也不要绘制的属性,那么渲染引擎会跳过布局和绘制,直接执行后续的合成操作,这个过程就叫合成。
举个例子:比如使用CSS的transform来实现动画效果,避免了回流跟重绘,直接在非主线程中执行合成动画操作。显然这样子的效率更高,毕竟这个是在非主线程上合成的,没有占用主线程资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。
利用这一点好处:
- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
提升合成层的最好方式是使用 CSS 的 will-change 属性
GPU加速原因
比如利用 CSS3 的transform、opacity、filter这些属性就可以实现合成的效果,也就是大家常说的GPU加速。
- 在合成的情况下,直接跳过布局和绘制流程,进入
非主线程处理部分,即直接交给合成线程处理。 - 充分发挥
GPU优势,合成线程生成位图的过程中会调用线程池,并在其中使用GPU进行加速生成,而GPU 是擅长处理位图数据的。 - 没有占用主线程的资源,即使主线程卡住了,效果依然流畅展示。

若有收获,就点个赞吧
0 人点赞
