什么是BOM和DOM?
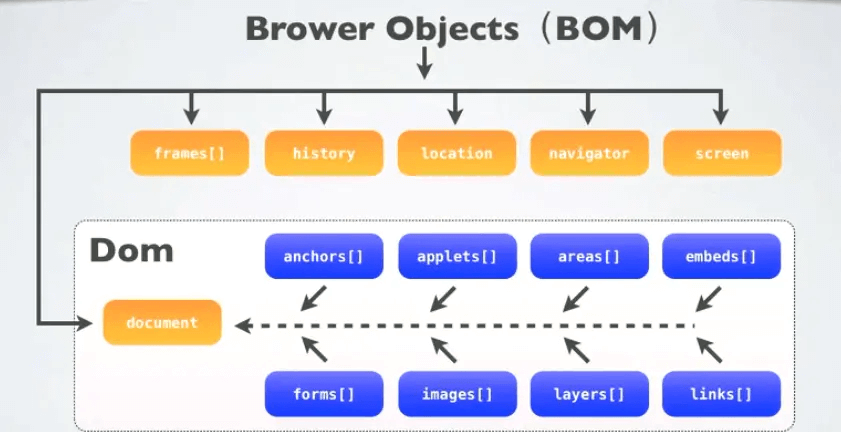
BOM:
browser object model (浏览器对象模型),将 web 页面与到脚本或编程语言连接起来。通常是指 JavaScript,但将 HTML、SVG 或 XML 文档建模为对象并不是 JavaScript 语言的一部分。DOM模型用一个逻辑树来表示一个文档,树的每个分支的终点都是一个节点(node),每个节点都包含着对象(objects)。DOM的方法(methods)让你可以用特定方式操作这个树,用这些方法你可以改变文档的结构、样式或者内容。节点可以关联上事件处理器,一旦某一事件被触发了,那些事件处理器就会被执行。
API
- window 对象, 所有的浏览器都支持,表示浏览器窗口, 最高层的对象, 下面的都可以不要 window 前缀
.innerHeight 窗口内部高度,包括滚动条
.innerWidth 窗口内部宽度,包括滚动条
.open() 打开新窗口
.close() 关闭当前窗口
.moveTo(x,y) 把窗口左上角移动到指定坐标
.resiezeTo(width,height) 窗口调整到指定大小 - window.Screen对象 可以不要window 前缀, 包含有关屏幕的信息
.availWidth 可用的屏幕宽度
.availHeight 可用的屏幕高度 - window.Location 对象 可以不要window 前缀, 获取当前页面的地址URL, 并把浏览器重定向到新的页面
.assign(url): 加载URL 指定的新的HTML 文档, 就相当于一个链接,跳转到指定的url,当前页面会转为新页面内容,可以点击后退返回上一个页面。
.replace(url): 通过加载 URL 指定的文档来替换当前文档 ,这个方法是替换当前窗口页面,前后两个页面共用一个窗口,所以是没有后退返回上一页的 - window.History 可以不要后缀, 获取浏览器历史 ,为了 保护用户隐私,对js访问该对象的方法进行了限制
.back()
.forward()
.go() - window.navigator 对象 可以不要window 前缀, 包含有关访问者浏览器的信息,注意navigator 对象的信息具有误导性,因为它的数据可以被修改
- window.document
弹窗
三种:警告框,确认框,提示框
- window.alert() 可去掉window
- confirm()
-
计时
setInterval() 间隔指定的毫秒数,不停的执行指定的代码
- setTimeout() 指定毫秒数后执行指定代码
- clearInterval()
- clearTimeout()
Cookie
Cookie 用于存储web页面的用户信息, 请求web 页面时, 该页面的cookie 会被添加 到请求中,服务器通过这种方式获取
键值对方式存储
JavaScript 使用document.cookie属性来创建,读取,及删除cookie
document.cookie 将以字符串的方式返回所有的 cookie,类型格式: cookie1=value; cookie2=value; cookie3=value;document.cookie="username=Gavin; expires=Thu, 18 Dec 2043 12:00:00 GMT; path=/";expires 设置过期时间, 默认下,cookie 在浏览器关闭时删除, path 告诉浏览器cookie 的路径, 默认情况下, cookie属于当前页面
document.cookie 属性并不是一个普通的文本字符串DOM:
document object model (文档对象模型) ,It is a standard defined byW3C (World Wide Web Consortium),it‘s a programming interface (API) for representing and interacting with HTML, XHTML and XML documents. It organize the elements of the document in tree structure (DOM tree) and in the DOM tree, all elements of the document are defined as objects (tree nodes) which have properties and methods.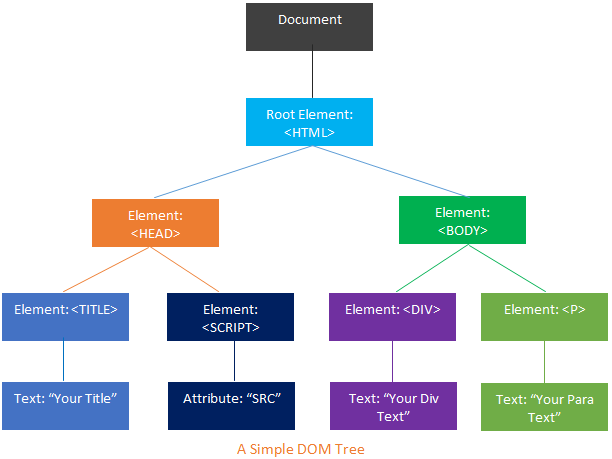

DOM接口
HTML 接口AttrCharacterDataChildNodeCommentCustomEventDocumentDocumentFragmentDocumentTypeDOMErrorDOMExceptionDOMImplementationDOMStringDOMTimeStampDOMSettableTokenListDOMStringListDOMTokenListElementEventEventTargetHTMLCollectionMutationObserverMutationRecordNodeNodeFilterNodeIteratorNodeListParentNodeProcessingInstruction (en-US)Promise (en-US)PromiseResolver (en-US)RangeTextTreeWalkerURLWindowWorkerXMLDocument
其他接口(Canvas)SVG接口
SVG数据类型接口
SVG路径段接口
SMIL 相关接口
其他SVG接口
1、DOM选择器(方法类操作)
(1) document 代表整个文档
document 是一个对象,这个对象上边有一些属性和方法,单独的 document 就代表的是整个文档在 js 里的显示形式,我们现在所说的整个文档最顶级的标签看上 去好像是 html 标签,但是如果在 html 标签外边再套一个标签的话,这个标签就是 document,就是说 document 才是真正的代表整个文档,html 只是他下面的一个根标签。(2)id 选择器
这个选择器和 css 里边讲的极其类似,比如说你在 html 里边写上一个123,然后在 js 里 var div = document.getElementById(“only”)(3)标签选择器
比如说你在 HTML 里边写一个123,然后在 js 里 var div = document.getElementsByTagName(“div”)
注意:document.getElementsByTagName(““),里边可以写 ,和通配符一样,选中了所有标签(4)class选择器
他和这个标签选择器差不多,选出来也是一组,你先123, 然后 var div = document.getElementsByClassName(“demo”)[0],此时访问 div 就得 到123。
注意:class 选择器在 ie8 和 ie8 以下的浏览器中没有,但是新版本是可以的, 所以在 js 里,class 选择器并没有标签选择器那么常用,标签选择器 getElementsByTagName 在任意一个浏览器里都好使。(5)name选择器
比如,然后 var input = document.getElementsByName(“abc”)[0], 访问 input 就得到。需注意这个 name 属性只对部分元素生效,如 表单、表单元素、img 等,name 选择器很少用。(6)css选择器
css 选择器能让我们在 js 里选择元素的时候和 css 里一样灵活,比如说:
然后在 js 里写上 var strong = document.querySelector(“div span strong”);括号 里写的东西就和 css 里选择标签的方法是一样的,此时访问 strong 就得到 ,这选的是一个,还有一个 var strong = document.querySelectorAll(“div span strong”);他选出来是一组,你再访问 strong 就得到 NodeList[strong]<div><strong></strong></div><div><span><strong></strong></span></div>
注意:在 ie7 及以下的版本没有,这个对我们并没有什么影响,还有一个致命的问题,就是 这个 querySelector 和 querySelectorAll 选出来的东西不是实时的,在用法上就及其受局限,除非极特殊情况,你就想选他的副本保存起来才会用这个,否则的话我 们不用。2、遍历节点树(非方法类操作)
(1)parentNode:父节点
比如说:
现在访问 strong.parentNode 就是他的父节点,得到<div><span></span><strong></strong><em></em></div><script type="text/javascript">var strong = document.getElementsByTagName("strong")[0];</script>
…,继续 strong.parentNode.parentNode 就是 div 的父亲,即…,继续就是 body 的父级,即…, 再就是 HTML 的父级,即 #document,再继续就得到 null,这就说明 document 就到顶层了,他是顶层的父级节点,代表整个文档。(2)childNodes 子节点们
遍历的是节点树,并不是只有元素节点算节点,节点的类型有很多,它包括文本节点、元素节点、属性节点、注释节点 等
比如:
访问 div.childNodes 就得到 odeList(7)[text, comment, text, strong, text, span, text],可见他有七个节点:依次是文本节点、注释节点、文本节点、元素节点、 文本节点、元素节点、文本节点。(空格文本和文本和回车文本都写在一起,就是一个文本 节点)<div><!-- this is comment! --><strong></strong><span></span></div><script type="text/javascript">var div = document.getElementsByTagName("div")[0];</script>
(3)firstChild/lastChild 第一个子节点/最后一个子节点
例如上边的,现在 div.firstChild 就是文本 123 和回车,div.lastChild 就是#text, 还是文本节点,只不过是空的,他就那样显示了。(4)nextSibling/previousSibling 后一个兄弟节点/前一个兄弟节点
还是上边的,var strong = document.getElementsByTagName(“strong”)[0];,然后 strong.nextSibling 就得到#text3、遍历元素节点树
这几种方法只遍历的是元素节点,其他的都不掺杂了。比如说:<div> 123<!-- this is comment! --><strong></strong><span></span></div>
(1)parentElement 元素父节点
在 js 里 var div = document.getElementsByTagName(“div”)[0]; 然 后 div .parentElement 他 的 元 素 父 节 点 就 是 … , 然 后 div.parentElement.parentElement,就是 body 的元素父节点,即…, 再父节点就是 null,因为 document 不叫 元素节点,他自称为一个节点,所以 parentNode 和 parentElement 的区别就在于有没有document。(2)children 元素子节点
现在 div.children 就得到 HTMLCollection(2)[strong,span],只有两个。(3)childElementCount === children.length 元素子节点的个数
比如说 div.childElementCount 就得到 2,你 div.children.length 也是 2,两者用法一样(4)firstElementChild/lastElementChild 第一个元素子节点/最后一个元素子节 点
现在 div.firstElementChild 就是,div.lastElementChild 就是 。(5)nextElementSibling/previousElementSibling 后一个兄弟元素节点/前一个兄 弟元素节点
strong.nextElementSibling 就得到
备注:以上遍历节点树的方法所有浏览器都兼容,但是遍历元素节点树的方法除 children 以外,ie9 及以下的浏览器都不兼容。4、节点的四个属性
<div>123<!-- this is comment! --><strong></strong><span></span><em></em><i></i><b></b></div><script type="text/javascript">var strong = document.getElementsByTagName("strong")[0];</script>
(1)nodeName 元素的标签名,只读
var div = document.getElementsByTagName(“div”)[0];
你访问 document.nodeName 就得到 “#document”,
访问 div.firstChild.nodeName,他是一个文本节点,就得到”#text”,
继续 div.childNodes[1].nodeName,第二个子节点是注释,就得到”#comment”, div.childNodes[3].nodeName 是元素节点,就得到”STRONG”。返回的是一个字符串, 只读就是只能读取不能写入,比如说我把 div.childNodes[3].nodeName = “abc”,再 访问的话还是”STRONG”。
(2)nodeValue text节点或comment节点的文本内容,可读写
这个属性只有文本节点和注释节点才有,
访问 div.childNodes[0].nodeValue 就得到 文本的回车和 123,这个可以改,你 div.childNodes[0].nodeValue = “234”,
再访问 的话就是”234”,再比如访问 div.childNodes[1].nodeValue 就得到” this is comment! “,如果 div.childNodes[1].nodeValue = “ that is comment! “,再访问 div.childNodes[1]就是<! — that is comment! —>。
(3)nodeType 该节点的类型,只读
比如说现在有一个节点,我也不知道里边是什么节点,就有他来分辨,每一个节点都 有这个 nodeType 属性,你调用他返回的是一个具体的值:
元素节点是 1,
属性节点是 2,
文本节点是 3,
注释节点是 8,
document 节点是 9,
DocumentFragment(文档碎片节点)是 11
现在 document.nodeType 就是 9,div.childNodes[1].nodeType 第二个是 注释节点就返回 8,div.childNodes[0].nodeType 文本节点返回 3, div.childNodes[3].nodeType 元素节点就是 1。
练习题
还是上边的例子,现在封装一个方法,要求返回 div 的直接子元素节点,但是 不允许用 children。
function retElementChild(node) {var temp = {length: 0,push: Array.prototype.push,splice: Array.prototype.splice},child = node.childNodes, len = child.length;for (var i = 0; i < len; i++) {if (child[i].nodeType === 1) {temp.push(child[i]);}}return temp;}
(4)attributes 元素节点的属性集合
这个属性就是访问元素的属性节点的,
<div id="only" class="demo"></div>//然后继续把 div 选出来:var div = document.getElementsByTagName("div")[0];//现 在 div.attributes 就得到 NamedNodeMap{0: id, 1: class, id: id, class: class, length: 2},//访问 div.attributes[0]就得到 id="only",//访问 div.attributes[1]就 是 class="demo"。div.attributes[1].nodeType // 就得到 2. 你也可以把他的属性名和属性值都取出来,div.attributes[0].name // 就得到"id",div.attributes[0].value // 就得到"only"。
5、节点的一个方法 Node.hasChildNodes()
这个方法就是判断这个元素有没有子节点,现在 div.hasChildNodes()就返回 true, 因为空格回车文本也算文本节点,除非
的话, 访问 div.hasChildNodes()是 false,中间啥都没有(属性节点不算,他是 div 自己的, 不能算子节点)才能返回 false。DOM 继承树及基本操作
DOM继承树
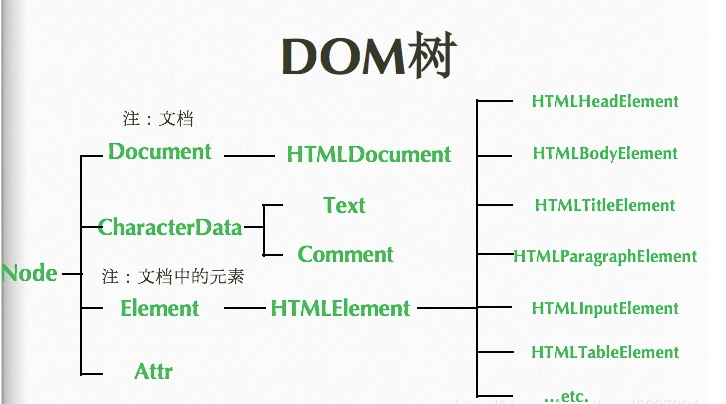
- 首先我们知道 document 代表的是整个文档,访问就得到#document,但是我访问 Document 就得到ƒ Document() { [native code] },是一个构造函数。假如说你给 Document 的原型上加一些属 性的话,比如 Document.prototype.abc = “abc”,那么 document 就能继承他的属性, 你访问 document.abc 就得到”abc”,上边的结构树就表示这一系列继承的关系。
- 第二个 CharacterData 下边有 Text 和 Comment,这就说明文本节点能用的属性和 方法全部继承自 Text.prototype,注释节点的方法则全部继承自 Comment.prototype, 然后一层一层向上继承。
- 第三个最长,Element 下边有一个 HTMLElement(那下边就肯定还有一个 XMLElement, 只不过没写),然后在下边有一堆东西,最后还没写完,但是你会发现那一堆东西都是 一些标签能用的一些属性和方法
- 现在 document. proto得到 HTMLDocument{…},
document. proto. proto就得到 Document{…},
document. proto. proto. proto得到 Node{…},
document. proto. proto. proto. proto得到 EventTarget{…}
document. proto. proto. proto. proto. proto就得到 Object{}.
这就说明 DOM 对象最终也继承自 Object.prototype,比如你访问 document.toString() 就得到”[object HTMLDocument]”,这个 Object.prototype 是所有对象原型链上的终端。DOM 结构树的应用
- getElementById 方法定义在 Document.prototype 上,即 Element 节点上不能使用
- getElementsByName 方法定义在 HTMLDocument.prototype 上,即非 html 中的 document 不能使用(xml 的 document 和 Element 不能用)。
- getElementsByTagName 方法定义在 Document.prototype 和 Element.prototype 上。
解释:这个方法在两个地方都定义了,就都能用,比如说
<div><span>1</span></div><span></span><script type="text/javascript">var div = document.getElementsByTagName('div')[0];var span = div.getElementsByTagName("span")[0];</script>
- HTMLDocument.prototype 定义了一些常用的属性,body,head,分别指代 HTML 文 档中的和标签。
解释:要选 head 标签或者 body 标签的话就直接 document.head 或者 document.body 就可以了。 - Document.prototype 上定义了 documentElement 属性,指代文档的根元素,在 HTML 文档中,他总是指代元素。
- getElementsByClassName、querySelectorAll、querySelector 这几个方法在 Document.prototype 和 Element.prototype 类中均有定义。
练习题1:遍历元素节点树(在原型链上编程)
<body><div><span><em></em><strong><em><a href=""></a></em></strong></span><p></p></div><span></span><script type="text/javascript">var div = document.getElementsByTagName('div')[0];Element.prototype.retChildElements = function () {var child = this.childNodes,len = child.length;for (var i = 0; i < len; i++) {if (child[i].nodeType === 1) {console.log(child[i]);}}}</script></body>
练习题2:封装函数,返回元素 a 的第 n 层祖先元素节点
<body><div><span><strong><em><a href=""></a></em></strong></span></div><script type="text/javascript">var a = document.getElementsByTagName('a')[0];function retParent(elem, n) {while (elem && n) {elem = elem.parentElement;n--;}return elem;}</script></body>
练习题3:编辑函数,封装 myChildren 功能,解决以前部分浏览器的兼容性问题。
<body><div><b></b>蜡笔小新<!-- this is comment --><strong><span><i></i></span></strong></div><script type="text/javascript">Element.prototype.myChildren = function () {var child = this.childNodes;var len = child.length;var arr = [];for (var i = 0; i < len; i++) {if (child[i].nodeType == 1) {arr.push(child[i]);}}return arr;}var div = document.getElementsByTagName("div")[0];</script></body>
练习题4:自己封装 hasChildren()方法,不可用 children 属性。
<body><div><b></b>蜡笔小新<!-- this is comment --><strong><span><i></i></span></strong></div><script type="text/javascript">Element.prototype.hasChildren = function () {var child = this.childNodes;var len = child.length;for (var i = 0; i < len; i++) {if (child[i].nodeType == 1) {return true;}}return false;}var div = document.getElementsByTagName("div")[0];</script></body>
练习题5:封装函数,返回元素 e 的第 n 个兄弟元素节点,n 为正,返回后面的兄弟元素 节点,n 为负,返回前面的,n 为 0,返回自己。
<body><div><span></span><p></p> <strong></strong><!-- this is comment --> <i></i><address></address></div><script type="text/javascript">function retSibling(e, n) {while (e && n) {if (n > 0) {if (e.nextElementSibling) {e = e.nextElementSibling;} else {for (e = e.nextSibling; e && e.nodeType != 1; e =e.nextSibling);}n--;} else {if (e.previousElementSibling) {e = e.previousElementSibling;} else {for (e = e.previousSibling; e && e.nodeType != 1; e = e.previousSibling);}n++;}}return e;}var strong = document.getElementsByTagName("strong")[0];</script></body>
DOM基本操作
上边讲的所有方法都是查看操作,下边讲其他的几个操作。
(1)增
- 创建元素节点(即创建标签):document.createElement()
- 创建文本节点:document.createTextNode()
- 创建注释节点:document.createComment()
- 创建文档碎片节点:document.createDocumentFragment()
(2)插
- appendChild():每个元素都有 appendChild 方法,这个方法就跟 push 方法一样。
注意:appendChild 进行的是剪切操作 - 父级.insertBefore(a, b):父级调用,里边传两个参数,意思是在 b 之前插入 a
(3)删
<body><div><span></span><strong></strong><i></i></div><script type="text/javascript">var div = document.getElementsByTagName("div")[0];var span = document.getElementsByTagName("span")[0];var strong = document.getElementsByTagName("strong")[0];var i = document.getElementsByTagName("i")[0];</script></body>
- parentNode.removeChild(a) 父级删除自己的子节点
div.removeChild(i)后其实是把 i 标签剪切出来了,比如说上边的代码刷新后 var ii = div.removeChild(i), 你在访问 ii 就是。 - a.remove()
比如上边代码刷新后 i.remove();strong.remove();div 里边就只剩下 span 了,remove 是真正的删除,删掉后就啥都没有了。
(4)替换
- parentNode.replaceChild(new, origin):这个也是父级调用,里边传入两个参数,第一个是 new 就是新的,第二个是目标
Element 节点的一些属性
(1)innerHTML
这个属性可以改变 html 里的内容,这个 innerHTML 取得是 HTML 结构,是可读写的,所以你写进去什么东西他都会识别成 HTML 结构。
(2)innerText
这个赋值的话里边的东西就全部被覆盖了,所以在用这个方法的时候需要谨慎, 如果标签底下有其他子标签,最好在赋值的时候不要用这个。
还有这个 innerText 老 版本的火狐浏览器不兼容,当时火狐有一个属性 textContent 和这个作用是一样的,但是火狐这个方法老版本的 ie 不好使(都是老版本的兼容性问题,现在的新版本不存 在不兼容的)。Element 节点的一些方法
<body><div></div><script type="text/javascript">var div = document.getElementsByTagName("div")[0];</script></body>
(1)元素.setAttribute() 添加属性
现在 div.setAttribute(“class”,”demo”),括号里第一个是属性名,第二个是属性值, 在访问 div 就得到
(2)元素.getAttribute() 查看属性
接着上边的,现在 div.getAttribute(“id”)就得到”only”,div.getAttribute(“class”) 就得到”demo”。
有了这些操作,就更灵活了,比如说我在 css 里定义了一个 class 样式,然后可以再 js 里动态的添加 class 属性,让这个样式作用在对应的元素上。
练习题1:封装函数 insertAfter(),功能类似 insertBefore(). 提示:可忽略老版本浏览器,直接在 Element.prototype 上编程。
<body><div><span></span><i></i><b></b> <strong></strong></div><script type="text/javascript">var div = document.getElementsByTagName("div")[0];var b = document.getElementsByTagName("b")[0];var strong = document.getElementsByTagName("strong")[0];Element.prototype.insertAfter = function (targetNode, afterNode) {var beforeNode = afterNode.nextElementSibling;if (beforeNode == null) {this.appendChild(targetNode);} else {this.insertBefore(targetNode, beforeNode);}}var p = document.createElement("p");</script></body>
练习题2:将目标节点的内部节点逆序
<body><div><span></span> <i></i><b></b> <strong></strong></div><script type="text/javascript">var div = document.getElementsByTagName("div")[0];Element.prototype.inversElement = function () {var len = this.children.length;for (var i = len - 1; i >= 0; i--) {this.appendChild(this.children[i]);}}</script></body>
获取窗口属性、获取 DOM 尺寸、脚本化 CSS
查看滚动条的滚动距离
- 标准方法 : window.pageXOffset window.pageYOffset
但是以上两种方法 ie8 及 ie8 以下浏览器不兼容,这些浏览器提供了两种方法:
- document.body.scrollLeft(和 window.pageXOffset 效果一样)
document.body.scrollTop(和 window.pageYOffset 效果一样) - document.documentElement.scrollLeft
document.documentElement.scrollTop
注意:以上两种方法兼容性比较混乱,就是 ie8 及 ie8 以下的浏览器有的浏览器版本第一个 方法好使,有的版本第二个方法好使,但是任何一个浏览器版本只要一种方法好使, 返回的有值,另一种不好使的方法返回的一定是 0,所以咱们在 ie8 及 ie8 以下的浏览 器不管哪个版本直接把两个值相加就行了。
练习题:封装兼容性方法,求滚动条滚动距离 getScrollOffset()
function getScrollOffset() {if (window.pageXOffset) {return {x: window.pageXOffset,y: window.pageYOffset}} else {return {x: document.body.scrollLeft + document.documentElement.scrollLeft,y: document.body.scrollTop + document.documentElement.scrollTop}}}
查看可视区窗口尺寸
可视区窗口就是咱们编写的 html 文档能看到的部分,不包括菜单栏、地址栏和控制台。
- 标准方法:window.innerWidth window.innerHeight
注意:以上两个方法还是 ie8 及 ie8 以下版本不兼容。这些浏览器版本提供了 两种方法,一种是在标准模式下用的,一种是在怪异模式下用的。
备注:什么是怪异模式?比如说在很久以前 ie7 还没有诞生,我写了一个页面,语法 全部用的是 ie6 的语法,但是一年之后 ie7 诞生了,人们都开始用新的浏览器,那么 我之前写的那个页面的部分语法就不能用了,因为有冲突,重写的话又太浪费时间, 后来人们研究了一种新的渲染模式叫怪异模式,比如说现在我启动了怪异模式,在这 个模式下即使人们用的是 ie7 浏览器,他也能根据 ie6 的语法把这个页面渲染出来, 这个怪异模式也叫混杂模式,这个模式一经启动他识别的就不是现在的语法而是之前 的语法,起到了一个向后兼容的作用,兼容之前的语法。那么怎么启用怪异模式?其 实我们在讲 html 的时候他第一行应该是<!DOCTYPE html>,这个我们一直没说,其实 有这一行就是标准模式,要想启动怪异模式,直接把这一行删掉即可。
- 第一种:标准模式下,任意浏览器都能兼容
document.documentElement.clientWidth
document.documentElement.clientHeight - 第二种:适用于怪异模式下的浏览器
document.body.clientWidth
document.body.clientHeight
怎么区分标准模式和怪异模式?
document 上有个属性 compatMode,在标准模式下访问 document.compatMode 得”CSS1Compat”,在怪异模式下访问 document.compatMode 得 “BackCompat”。
练习题:封装兼容性方法,返回浏览器视口尺寸 getViewportOffset()
function getViewportOffset() {if (window.innerWidth) {return {w: window.innerWidth,h: window.innerHeight}} else {if (document.compatMode === "BackCompat") {return {w: document.body.clientWidth,h: document.body.clientHeight}} else {return {w: document.documentElement.clientWidth,h: document.documentElement.clientHeight}}}}
查看元素几何尺寸
- dom.getBoundingClientRect()
返回的是一个对象,对象里边有 left、top、right、bottom 等属性,left 和 top 代表该元素左上角的 X 和 Y 坐标,right 和 buttom 代表元素右下角的 X 和 Y 坐标, 这个方法兼容性很好,但是老版本的 ie 里并没有 height 和 width,所以我们在老版本 的 ie 只能计算来求宽高,而且这个方法返回的结果并不是实时的,比如说我 var box = div. getBoundingClientRect();div.style.width = “200px”,再访问 box 的话里边 的 width 还是 100px,所以他不是实时的。
查看元素的尺寸
dom.offsetWidth dom.offsetHeight
查看元素的位置
-
滚动条滚动
window上有三个方法:
window.scroll()
- window.scrollTo()
- window.scrollBy()
用法都是将 x、y 坐标传入,即实现让滚动条滚动到当前位置。
window.scroll()和 window.scrollTo()两个方法完全一样,兼容性也一样,比如说 window.scroll(0,100)他就能让 y 方向的滚动条滚动到 100 像素这个位置,你继续 window.scroll(0,100)他是不变的,说明他是让滚动条滚动到当前位置。
而 window.scrollBy()是累加滚动当前距离,比如说 window.scrollBy(0,10)他是让滚 动条向下滚动 10 像素,继续 window.scrollBy(0,10)就继续向下滚动 10 像素,继续 window.scrollBy(0,-10)就又向上滚动 10 像素。
练习题:模仿手机阅读器,做一个自动阅读的功能
<body><divstyle="width:100px;height:100px;background-color:orange;color:#fff;font-si ze:40px;font-weight:bold;text-align:center;line-height:100px;position:fixe d;bottom:200px;right:50px;border-radius: 50%;opacity:0.5;">start</div><divstyle="width:100px;height:100px;background-color:#0f0;color:#fff;font-size :40px;font-weight:bold;text-align:center;line-height:100px;position:fixed; bottom:50px;right:50px;border-radius: 50%;opacity:0.5;">stop</div><script type="text/javascript">var start = document.getElementsByTagName("div")[0];var stop = document.getElementsByTagName("div")[1];var timer = 0;var key = true;start.onclick = function () {if (key) {timer = setInterval(function () {window.scrollBy(0, 10);}, 100)}key = false;}stop.onclick = function () {clearInterval(timer);key = true;}</script></body>
脚本化css
读写元素css属性 dom.style
任何一个 dom 元素都会有 style 属性,我们在控制台访问 div.style 得到,这个 dom.style 没有任何兼容性问题,但是注意碰到 float 这样的保留字属性,前边 应该加上 css,如 div.style.cssFloat = “right”。还有就是复合属性(如 border) 最好把他拆解开设置,但是现在写在一起也是可以的,最好把他拆解开。
查询计算样式
- window.getComputedStyle(dom,null)
这个方法需要传入两个参数,第一个是 dom 元素,第二个是 null,返回的也是一个样式表,但是和上边的不一样,style 里读的只是行间里的样式,假如说你在行间没有设置的话他就没有值,但是这个方法返回的属性里即使你没有设置他也是有值的,是默认值,这个方法获取的是当前元素所展示的一切 css 的显示值, 就是假如说你通过多个选择器给一个元素设置了一个属性,那么只有权重最高的那个 起作用,而这个方法获取的只是那个起作用的也就是显示的那个值和一些默认值。这个方法 ie8 及 ie8 以下不兼容。
这个方法第二个参数是干嘛的吗?为啥要传 null 呢?第二个参数传对了,可以获取伪元素的样式
查询样式
- dom.currentStyle (ie 独有的属性)
这个是 ie 独有的属性,他也能返回一个样式表,和 window.getComputedStyle()方法 类似,也是只能读取不能写入,他获取的也是最终展示的那个值,但是他返回的计算 样式的值不是经过转换的绝对值,写啥就展示啥。
练习题:做一个小木块运动。
<body><div style="width:100px;height:100px;background-color:red;position:absolute;"></div><script type="text/javascript">function getStyle(elem, prop) {if (window.getComputedStyle) {return window.getComputedStyle(elem, null)[prop];} else {return elem.currentStyle[prop];}}var div = document.getElementsByTagName("div")[0];var speed = 2;var timer = setInterval(function () {speed += speed / 7;div.style.left = parseInt(getStyle(div, "left")) + speed + "px";if (parseInt(getStyle(div, "left")) > 500) {clearInterval(timer);}}, 10)</script></body>
DOM和BOM的联系
javacsript是通过访问BOM(Browser Object Model)对象来访问、控制、修改客户端(浏览器),由于BOM的window包含了document,window对象的属性和方法是直接可以使用而且被感知的,因此可以直接使用window对象的document属性,通过document属性就可以访问、检索、修改XHTML文档内容与结构。因为document对象又是DOM(Document Object Model)模型的根节点。可以说,BOM包含了DOM(对象),浏览器提供出来给予访问的是BOM对象,从BOM对象再访问到DOM对象,从而js可以操作浏览器以及浏览器读取到的文档

若有收获,就点个赞吧
0 人点赞
