Bayesian Learning
伯努利分布 
抛骰子:

概率可以表示为
假设已有数据集 ,模型是骰子模型,则θ就是参数
,模型是骰子模型,则θ就是参数
- learning:D ——> θ

 这里nk叫做充分统计量。
这里nk叫做充分统计量。
上面的式子就是数据集的似然函数,利用MLE和拉格朗日数乘法来求解参数θ得
如果要求后验分布 需要给参数一个先验分布,一般我们假设θ服从狄利克雷分布。
需要给参数一个先验分布,一般我们假设θ服从狄利克雷分布。 - Inference:θ, x ——> y
文本分类
通常我们先汇总数据集中全部文档的词,形成一个词表,且其中各个词之间相互独立。 这里每一行代表一个文档,
这里每一行代表一个文档, 可以表示词表中第j个词在文档中出现的次数。
可以表示词表中第j个词在文档中出现的次数。
这里我们也可以令 第i篇文档中第j个词是在词表中的索引。这里我们假设词表大小为V,则
第i篇文档中第j个词是在词表中的索引。这里我们假设词表大小为V,则 。
。
文档具有分类标签我们假设
则根据上面的公式 ,整个模型参数个数为(K-1) + K(V-1)
,整个模型参数个数为(K-1) + K(V-1)
MLE
我们可以利用MLE进行求解,这里的充分统计量是:
 表示数据集中第k类文档的数量
表示数据集中第k类文档的数量 表示在第k类文档中,词表中第v个词出现的次数
表示在第k类文档中,词表中第v个词出现的次数
解得:

 这里如果分子为0,那么参数也等于0,但这可能违背了真实情况。这可以利用平滑进行改进,比如+1平滑,保证分子至少为1.
这里如果分子为0,那么参数也等于0,但这可能违背了真实情况。这可以利用平滑进行改进,比如+1平滑,保证分子至少为1.
这里如果我们给参数也加上先验分布,且标签y变成隐变量,那么MLE就没法求解了,需要利用EM求解。
伯努利混合模型(Bernoulli Mixture Model)
先看一个盒子摸球例子:
- A盒子:黑8红2
- B盒子:黑3红7


同理如果有两枚硬币A和B,每次选择一枚硬币抛掷,其概率为 ,硬币正面朝上概率分别为:
,硬币正面朝上概率分别为: 。
。
如果我们已知抛掷的结果是正面朝上,我们可以利用上面盒子例子的公式求来自硬币A或B的概率。
对给定数据集 ,这里我们只有观测结果正面还是反面朝上,标签y(y=A/B)是隐变量,概率图可以表示为
,这里我们只有观测结果正面还是反面朝上,标签y(y=A/B)是隐变量,概率图可以表示为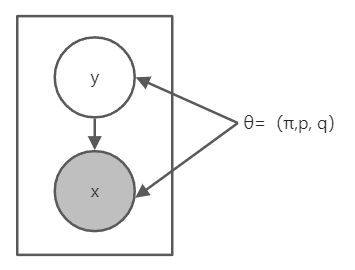


对数似然函数
EM算法
这里由于对数内是一个概率求和,使得利用导数难以求解MLE。
我们引入一个 ,k的值是标签y的可能取值,在这个例子中是0、1。
,k的值是标签y的可能取值,在这个例子中是0、1。
则似然函数可以写成
转换成了对随机变量Yi的函数求期望,由期望的性质

等号成立条件 如果我们能知道θ就能计算此后验概率。
如果我们能知道θ就能计算此后验概率。
随后还需要对θ进行迭代计算。

若有收获,就点个赞吧
0 人点赞
