1.什么是机器学习(Machine Learning)
机器学习是人工智能的一种实现方式。
对机器学习的一种流行的定义是:
一个计算机程序在完成某项任务T的过程中,如果它的性能P,随着经验E而逐步提高,那么我们就说他从E中学习了。
这里机器(Machine)就是一个模型,给它一个输入就会获得我们想要的输出,可以将其抽象为一个函数(function)。例如一个我们最熟悉的线性方程:
y = kx + b,输入一个x就会求出相应的y值。
不过我们数学中一般都是已知k和b,根据来求y。在机器学习中通常我们已知输入(x)和输出(y),希望能找到一对k1和b1,使得对所有x和y均满足y=k1x + b1。
所以所谓的学习(learning)要学的就是一个参数集合 ,学习的过程也可以叫做拟合。
,学习的过程也可以叫做拟合。
常见函数类型:
- 几何函数
例如线性模型 : 这里x并不是必须为一次的。
这里x并不是必须为一次的。 同样是线性的。 在多项式回归中
同样是线性的。 在多项式回归中 
深度学习可以看做是嵌套的复合函数。 - 逻辑函数

决策树模型就是这类函数 - 概率函数
可分为产生式(Generative)和判别式(Discriminate)。- 产生式:对
 进行建模。如朴素贝叶斯、隐马尔可夫模型
进行建模。如朴素贝叶斯、隐马尔可夫模型 - 判别式:学习
 。如 k近邻、SVM等
。如 k近邻、SVM等
- 产生式:对
统计与概率:统计是在已知数据的前提下,进行模型的归纳与推断。这其实就是学习。概率是在已知模型的基础上,对其他样本数据进行预测。
2.机器学习分类
2.1根据数据标记分类
根据数据标记通常将机器学习分为有监督学习、无监督学习和强化学习。
- 有监督学习:有参考标记y
回归、分类、深度学习 - 无监督学习:没有参考标记y
- 聚类(clustering):k-means
- 投影(projection): PCA/SVD/ICA
- P.D.E
强化学习:强化学习的特点有:与环境互动、延迟奖励。最终要学习一个策略函数
 ,当给定一个输入状态时,返回响应的动作。
,当给定一个输入状态时,返回响应的动作。
2.2根据输出空间y分类
分类:y是离散的,例如
 。数字识别
。数字识别- 回归:
 。如房价预测
。如房价预测 - 结构化学习:y很复杂,例如给图片起标题、蛋白质折叠预测。
3.机器学习的模式
ML = LAMBDA = Loss + Algorithm + Model + Big Data + Application
3.1Big Data = Matrix = everything
任何事物都可以抽象成一个向量表示,在数据库中对应的就是一条记录。
例如在学生成绩数据中,一个学生的成绩数据可由向量  来表示。这里每个数都表示一门课的成绩,在机器学习中称为特征值(feature),向量称为特征向量(feature vector)。许多向量叠加在一起组成了矩阵(Matrix)。
来表示。这里每个数都表示一门课的成绩,在机器学习中称为特征值(feature),向量称为特征向量(feature vector)。许多向量叠加在一起组成了矩阵(Matrix)。
将原始数据通过加工处理转化成机器学习可以使用的矩阵的过程,我们叫做特征工程。
特征矩阵我们通常用X表示。其中每一行表示一个样本的特征向量,每一列表示全部样本在对应特征上的取值。 这里X是一个n*d矩阵,表示有n个样本,每个样本有d个特征。通常n > d。
这里X是一个n*d矩阵,表示有n个样本,每个样本有d个特征。通常n > d。
- 关于矩阵的秩(Rank)。若Rank(X) = d。 从列向量角度看,列向量之间线性无关,说明特征没有冗余,降维也不会有更好的效果。
- 关于
 。
。 结果是一个d*d的矩阵,可以认为是特征之间的相关性
结果是一个d*d的矩阵,可以认为是特征之间的相关性 关于
 。
。
 即每个元素都是两个样本特征向量之间的内积。
即每个元素都是两个样本特征向量之间的内积。参数模型:通过固定大小的参数集(与训练样本数独立)概况数据的学习模型称为参数模型。不管你给与一个参数模型多少数据,对于其需要的参数数量都没有影响。
例如:混合高斯模型,线性回归,逻辑回归- 非参数模型:不对样本的总体分布做假设,直接分析样本的一类统计分析方法。
例如:KNN
 ,可得
,可得  可以认为是两个归一化的向量相乘。因此当每个样本特征向量都进行了归一化处理后,可以认为A中的元素表示两个样本向量之间的夹角,可以看做是相似度的度量。
可以认为是两个归一化的向量相乘。因此当每个样本特征向量都进行了归一化处理后,可以认为A中的元素表示两个样本向量之间的夹角,可以看做是相似度的度量。
例如线性回归模型  ,参数集合为
,参数集合为  ,这里参数集合是未知的,是需要通过学习得到的。
,这里参数集合是未知的,是需要通过学习得到的。
3.3 Loss
现在我们已经有了数据与模型,当我们将一个样本x送入模型中,会输出一个预测结果 (我们称为预测值)。这时我们想要知道这个预测结果的可靠性,就需要一个“尺子”来度量,这个“尺子”就是Loss函数。它会告诉我们模型输出结果与样本真实值直接的差距。
(我们称为预测值)。这时我们想要知道这个预测结果的可靠性,就需要一个“尺子”来度量,这个“尺子”就是Loss函数。它会告诉我们模型输出结果与样本真实值直接的差距。
通常我们会用 来表示单个样本真实值与预测值之间的差距。例如最常用的平方差
来表示单个样本真实值与预测值之间的差距。例如最常用的平方差 。
。
而整个样本集合的损失函数我们可以表示为 ,注意这里未知数为参数集合
,注意这里未知数为参数集合 。
。
对我们来说,我们希望的是模型输出的预测值与真实值越接近越好,也就是我们希望损失函数越小越好。上文提到机器学习要学习的就是参数,这里我们的学习目标就是学习一组参数使得损失函数达到最小。即 。
。
3.4 Algorithm
现在有了损失函数,有了学习目标就是让损失降到最低,这需要我们调整模型的参数来降低损失函数。但如何调整参数呢,可以用随机的方式,但这全靠运气了。这就轮到算法登场了,这里我们说的算法其实就是优化方法,其根据损失值来告诉模型应该如何调整参数。
通常我们使用梯度下降(Gradient Desent)方法来调整参数。对一个函数在某点处的梯度表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿梯度方向变化最快。
3.5 Application
所谓应用其实就是将模型应用到生产环境中去执行特定的任务。
流程图: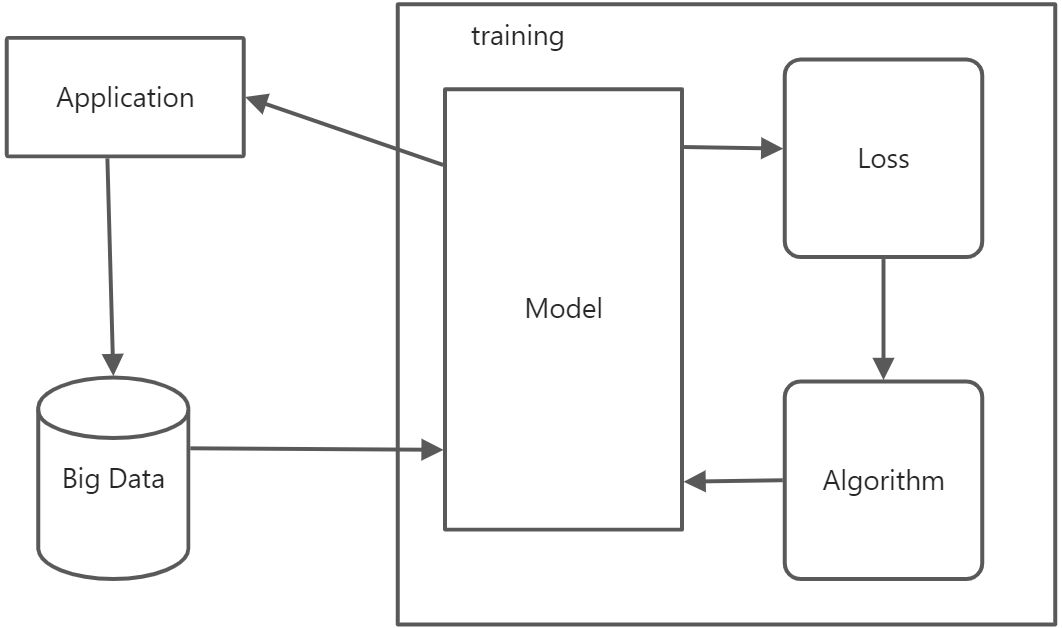
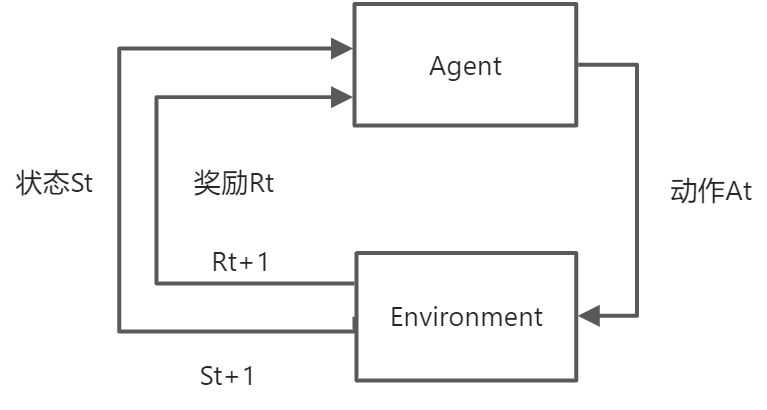
4.强化学习
RL = Model + Value + Policy
强化学习的特点就是Agent会在与environment的交互中进行学习。
- 所谓的Agent其实就是一个函数
 ,输入一个当前状态,输出一个动作At。目标就是通过学习,使得函数能根据状态做出决策使得获得的累积奖励最大。
,输入一个当前状态,输出一个动作At。目标就是通过学习,使得函数能根据状态做出决策使得获得的累积奖励最大。 - Model 就是对环境的建模,主要就是状态转移概率函数及奖励函数。状态的转移可以分为:确定性转移过程和随机性转移过程
- 确定性转移过程:
 ,St+1 是唯一的下一个状态。
,St+1 是唯一的下一个状态。 - 随机性转移过程:

- 确定性转移过程:
奖励函数: R(St, At, St+1),是环境固有的性质,只是跟采取的动作及当前状态相关。这是一个短期收益。
- Value Function:价值函数是在策略π下从某一状态s的长期累积奖励的期望即

- Policy Function: 强化学习的目标是的最终获得一个最优策略函数π(a|s)

若有收获,就点个赞吧
0 人点赞
