1. review
学习与推断
- learning : 给定数据集D,期望获得模型参数θ
inference:已知数据集D,输入x,期望获得对应的输出y, 即求P(y|x, D)
1.1 learning
1.1.1 MLE 最大似然估计
1.1.2 MAP 最大后验估计

取对数后变为
第一项被称为data term, 第二项是regulation term(正则项)可以减少过拟合1.1.3 贝叶斯
1.2 inference
1.2.1 MLE
1.2.2 MAP
1.2.3 贝叶斯

这个积分很难求解,因此一般我们通过采样的方法来求其近似解。
在我们获得了θ的后验分布之后,对θ进行采样得到一个θ序列 则
则
2. logistic regression
这是一个分类器模型,其概率图可以表示如下,这里参数θ也是随机变量,α是超参数。y取值为0或1。
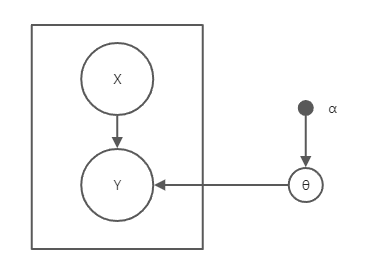
数据集
2.1 MLE:
概率计算可以表达为

将其合并为一个式子
则其对数似然函数为
极大似然估计就是
求解方法有两种:一阶导数为0,
 ,解方程得到解析解,但这里激活函数是个非线性函数,很难解出来
,解方程得到解析解,但这里激活函数是个非线性函数,很难解出来- 梯度上升




 称为激活函数
称为激活函数

现在我们求一下梯度。
- 先看一下激活函数
 的导数
的导数

- 变成矩阵形式就是


2.2 MAP






2.3 Bayesian
3.感知机
感知机是一个二分类模型,本质就是一个线性函数 。其分类规则非常简单,对输入样本x,若加权和大于0,则为正类,小于0为负类。从几何上看w^x+b表示的一个超平面
。其分类规则非常简单,对输入样本x,若加权和大于0,则为正类,小于0为负类。从几何上看w^x+b表示的一个超平面
这里我们要做的就是学习得到一个最佳的参数w和b。根据我们已经学习的训练策略,我们需要一个损失函数。
我们知道点到平面距离公式为 ,故我们可以用误分类的点到超平面的距离来衡量损失,显然越小越好。
,故我们可以用误分类的点到超平面的距离来衡量损失,显然越小越好。
由感知机模型我们知道,输出标签 与加权和是同号的,则误分类点均满足
与加权和是同号的,则误分类点均满足 ,所有误分类点的距离之和为
,所有误分类点的距离之和为 ,分母对我们求极值没有影响,且还增加了求导复杂度,故我们只保留分子部分,则损失函数最终表示为:
,分母对我们求极值没有影响,且还增加了求导复杂度,故我们只保留分子部分,则损失函数最终表示为:
导数为
之后可以使用梯度下降方法求参数。
4.生成式分类模型
对分类问题标签y是离散的。
生成式需要对x和y的联合概率密度p(x,y)建模。 这可以认为是特征x是y的表现,正是因为其类别y才有了对应的特征x。
这可以认为是特征x是y的表现,正是因为其类别y才有了对应的特征x。
这里x有两种情况:连续和离散。
4.1 x是连续值
Model:  这里假设y是伯努利分布参数为p,x服从高斯分布,这里对不同的y,x的高斯分布参数是不同的,假设y=k时参数为
这里假设y是伯努利分布参数为p,x服从高斯分布,这里对不同的y,x的高斯分布参数是不同的,假设y=k时参数为

则似然函数如下,其中参数是


取对数得
如何求θ,假设方差已知
MLE:


Inference:
给定新的x,如何求y?
分别计算P(y=1|x)和P(y=0|x),哪个值大就是哪一类。
假设预测结果为y=1,如果我们将两者相除可得 是一个判决面
是一个判决面
当


若有收获,就点个赞吧
0 人点赞
