马尔科夫决策过程
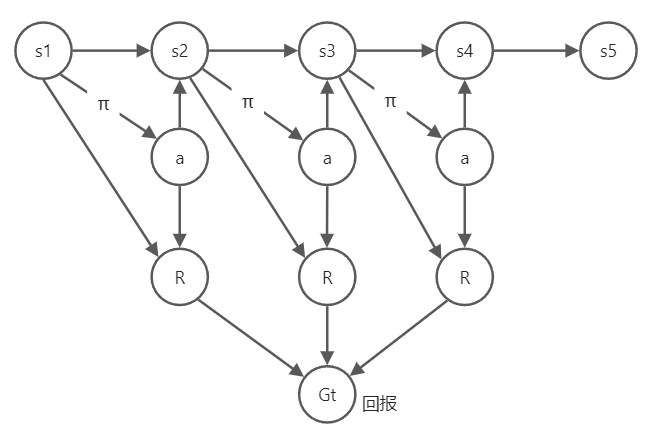
智能体在环境中的一系列决策过程可以表示为一条轨迹即状态、动作、奖励的序列:
对强化学习来说数据就是一系列决策历史 ,数据集D也叫做经验experience
,数据集D也叫做经验experience
回报(return)即累计折扣奖励:
表示从t时刻起到结束所获得的累积折扣奖励。
回报的期望:

上面式子的计算需要已知环境动力学模型。
贝尔曼方程
如何判断一个状态好还是不好,可以使用状态价值函数:
关于全期望公式:
根据全期望公式可知:





用s’表示 ,根据价值函数定义有;
,根据价值函数定义有;


所以
贝尔曼方程的矩阵形式


 解得
解得

动作价值函数Q
这里引入一个Q函数,叫做动态价值函数,其定义在某一个状态采取某一个动作所获得的期望回报
显然根据概率图模型可得:
Q函数的贝尔曼方程





由上面两个式子可以建立V和Q的关联


若有收获,就点个赞吧
0 人点赞
