线性拟合
对一个样本特征矩阵X,其大小为n*d。对不同数据其n与d大小也不同
- n==d ,此时X是一个方阵
- n >> d, 常见的视觉数据集就是这样的
- n << d, 生物数据就是这种情况,此时数据样本在高维空间中稀疏,容易过拟合
关于平方和误差函数,使用矩阵表示
这里我们需要求解的是向量w使得误差函数最小。
我们可以直接让偏导数等于零来求解w
解得 这里需要X列满秩也就是XTX可逆才可以。
这里需要X列满秩也就是XTX可逆才可以。
将w代入线性模型中可得 我们称矩阵H为Hat Matrix
我们称矩阵H为Hat Matrix 其实就是一个坐标变换过程。
其实就是一个坐标变换过程。
最小二乘的几何解释
我们的目标是得到一个系数向量w使平方和误差最小,理想情况是误差为零。
在线性代数中Xw是一个向量,表示的是X列向量的线性组合。若X列满秩则其列向量是其列空间的一个基,其线性组合可以表示列空间中的任何一个向量。
- 若特征矩阵X是一个满秩的方阵,则对应的标签向量y必然存在于X的列空间中,因此一定有w使得y = Xw。
- 若X不是方阵,n > d,则X的列向量张成的是一个Rn 的子空间。此时若y不在此子空间时,y=Xw无解。
此时我们可以考虑投影向量。
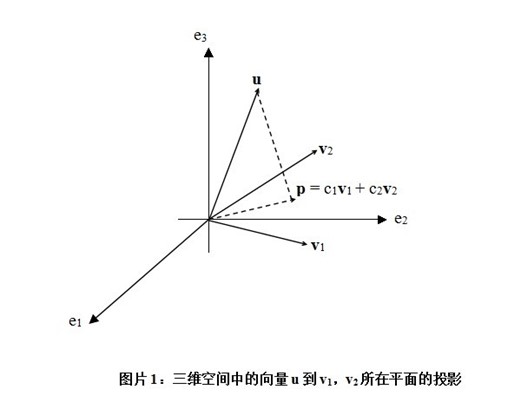
如图所示,向量u是一个三维向量,向量v1,v2张的是一个二维平面,p是u在该二维平面的投影。则向量u-p垂直于二维平面故有
这正好与我们在上面求的w一样,所以最小二乘法的几何意义就是高维空间中的一个向量在低维子空间的投影。
recursive least square
假设我们根据现有数据X,y计算得到了wn,即
此时如果我们获得了新的数据,该如何调整w,如果每次获得新的数据都利用上述公式从头进行计算,那会花费非常多的时间和算力,那么是否有一种方式更好的方法更新w,能否在现有w基础上进行调整获得新的w以避免重复计算。这种方法就是recursive least square 即利用新样本在已有权重下的差值来更新w。
即利用新样本在已有权重下的差值来更新w。
这种随着新数据到来更新w的方式是一种在线学习方式。
核方法
所谓核函数,是通过带入两个低维空间向量的坐标,直接计算出所带入向量经某高维映射后,所得向量的内积值,公式表达为
在我们求得权重向量w后,对任意的样本x(此处为列向量),均有 ,令
,令

可以看做是对x和xi进行坐标变换后比较其相似度,并以此为权值来对每个标签yi进行加权,类似于聚类算法中的近邻算法。
人工智能5种流派
 则
则 这里令方差为1
这里令方差为1 ,根据极大似然原理我们可以求出产生该样本最可能的参数w。
,根据极大似然原理我们可以求出产生该样本最可能的参数w。

若有收获,就点个赞吧
0 人点赞
