1.朴素贝叶斯
1.1原理与模型
概率图模型如下,可以看到X与Y都是可观测的值,并且Y是X的条件。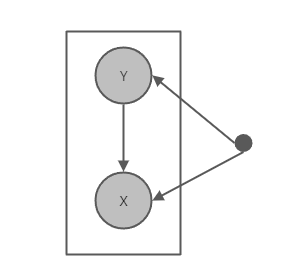
我们要对X,Y的联合概率分布建模。
假设数据为 ,这里样本X,Y取样自某个分布P,其含有参数θ。
,这里样本X,Y取样自某个分布P,其含有参数θ。
求解θ的过程就是学习(learning), 有了θ后,对新的x预测其y的过程叫做预测。比如给定一封邮件判断其是否是垃圾邮件。
预测/推理过程可以表示为: 这里利用了贝叶斯公式。p(y)叫做类先验概率,p(x|y)叫做类条件概率。
这里利用了贝叶斯公式。p(y)叫做类先验概率,p(x|y)叫做类条件概率。
1.1.2 参数的数量
为了计算 ,我们需要知道p(y) 跟 p(x|y)的所有可能,那么一共要求多少种?
,我们需要知道p(y) 跟 p(x|y)的所有可能,那么一共要求多少种?
则一共要计算 ,可以看到当特征维度很大时,要求的参数非常庞大。
,可以看到当特征维度很大时,要求的参数非常庞大。
这里我们简化为x每个维度可能取值也只有0和1,且各维度相互独立。
那么特征分布为 。那么我们要求的参数为
。那么我们要求的参数为 一共是1 + 2*d个参数。
一共是1 + 2*d个参数。
1.1.3 条件独立性

条件独立性是说当Z已知时,X与Y是独立的,即 。
。
我们对各维度的处理就是利用了条件独立性。
1.1.4 朴素贝叶斯原理

1.2 算法
以最简单的情况为例,X和Y均服从伯努利分布,样本之间是独立的,样本的各个特征也是相互独立的。即:


则似然函数为:
取对数化简得:
将似然函数记为 。
。
可以利用导数求解: 这里n1表示yi=1的样本数。
这里n1表示yi=1的样本数。

1.3 例子
这里以垃圾邮件为例。

在上面的计算中看到,若有一个特征在某一类中频率为0,则P(X|y) 计算一定为0。 例如对含有acount的邮件, 一定成立,不管其他词是什么样,则其后验也一定为0。即只要含有acount就是垃圾邮件。这就是Zero-Frequency Problem。
一定成立,不管其他词是什么样,则其后验也一定为0。即只要含有acount就是垃圾邮件。这就是Zero-Frequency Problem。
解决办法:拉普拉斯平滑 这里N是类别数,对应的
这里N是类别数,对应的 这里n是样本总数。
这里n是样本总数。
关于属性缺失
朴素贝叶斯算法能够处理缺失的数据,在算法的建模时和预测时数据的属性都是单独处理的。因此如果一个数据实例缺失了一个属性的数值,在建模时将被忽略,不影响类条件概率的计算,在预测时,计算数据实例是否属于某类的概率时也将忽略缺失属性,不影响最终结果。

若有收获,就点个赞吧
0 人点赞
