
barrier
栅栏函数
- 最直接的作用:控制任务执行顺序,同步
非常重要的一点:栅栏函数只能控制同一并发队列
建立并发队列,异步执行任务,添加栅栏函数
- 执行结果 e -> a -> b -> c -> d,barrier控制了并发队列,a、b一定在c前
- 将栅栏函数队列改为concurrentQueue1,则不控制concurrentQueue队列,执行结果e -> d -> a -> c -> b
```cpp
dispatch_queue_t concurrentQueue = dispatch_queue_create(“cooci”, DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t concurrentQueue1 = dispatch_queue_create("kc", DISPATCH_QUEUE_CONCURRENT);
// dispatch_queue_t concurrentQueue = dispatch_get_global_queue(0, 0); // 这里是可以的额! / 1.异步函数 / dispatch_async(concurrentQueue, ^{ NSLog(@”a”); });
dispatch_async(concurrentQueue, ^{sleep(1);NSLog(@"b");});/* 2. 栅栏函数 */ // - dispatch_barrier_syncdispatch_barrier_async(concurrentQueue, ^{NSLog(@"c");});/* 3. 异步函数 */dispatch_async(concurrentQueue, ^{NSLog(@"d");});// 4NSLog(@"e");
- 将栅栏async改为sync,队列为concurrentQueue,sync阻塞16后流程,执行结果为a -> b -> c -> d -> e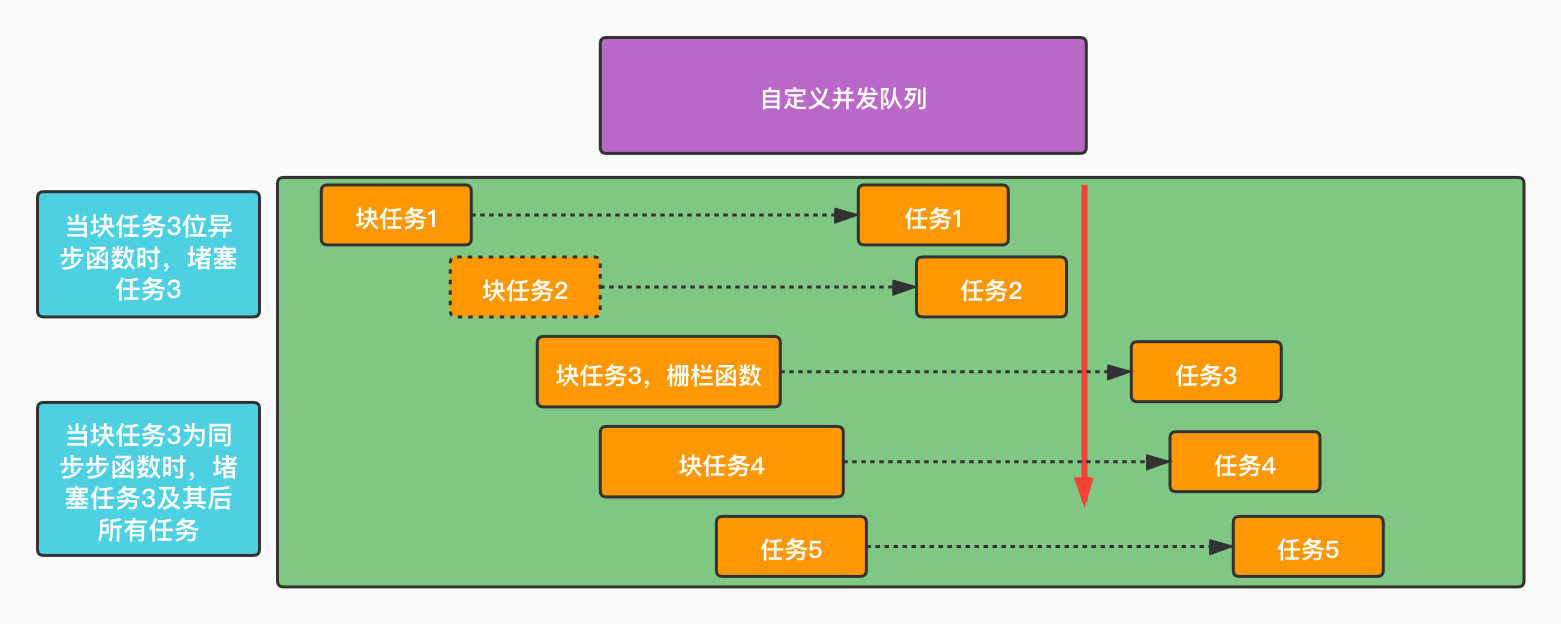- **全局并发队列global_queue,添加barrier无效,全局并发队列不允许添加栅栏函数**<a name="colL0"></a>## 举例2- 当数组操作未添加barrier隔离时,**赋值操作就是每次进行release旧值,retain新值**,在多线程操作下,可能某次release旧值未及时执行,导致下次连续两次release,再retain时**读取了野指针,**进而崩溃,出现读写异常。```cppdispatch_queue_t concurrentQueue = dispatch_queue_create("cc", DISPATCH_QUEUE_CONCURRENT);// dispatch_queue_t concurrentQueue = dispatch_get_global_queue(0, 0);// 多线程 操作marrayfor (int i = 0; i<1000; i++) {dispatch_async(concurrentQueue, ^{NSString *imageName = [NSString stringWithFormat:@"%d.jpg", (i % 10)];NSURL *url = [[NSBundle mainBundle] URLForResource:imageName withExtension:nil];NSData *data = [NSData dataWithContentsOfURL:url];UIImage *image = [UIImage imageWithData:data];// self.mArray 多线程 地址永远是一个// self.mArray 0 - 1 - 2 变化// name = kc getter - setter (retain release)// self.mArray 读 - 写 self.mArray = newaRRAY (1 2)// 多线程 同时 写 1: (1,2) 2: (1,2,3) 3: (1,2,4)// 同一时间对同一片内存空间进行操作 不安全dispatch_barrier_async(concurrentQueue , ^{[self.mArray addObject:image];});});}
源码探索

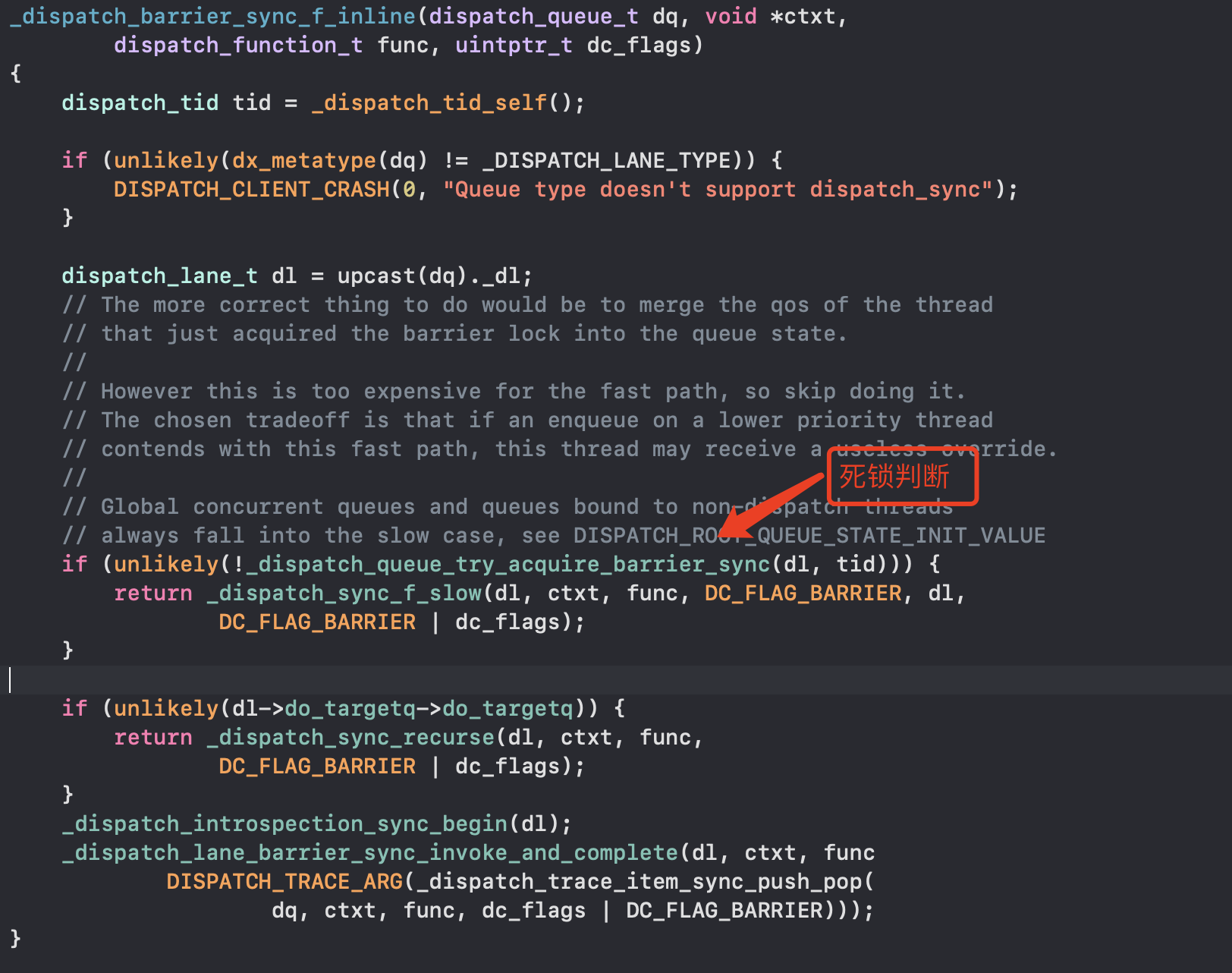
- _dispatch_barrier_sync_f_inline做了哪些事
- 和dispatchsync底层一样,也会有dispatch_sync_f_slow判断,有可能出现死锁情况__DISPATCH_WAIT_FOR_QUEUE函数
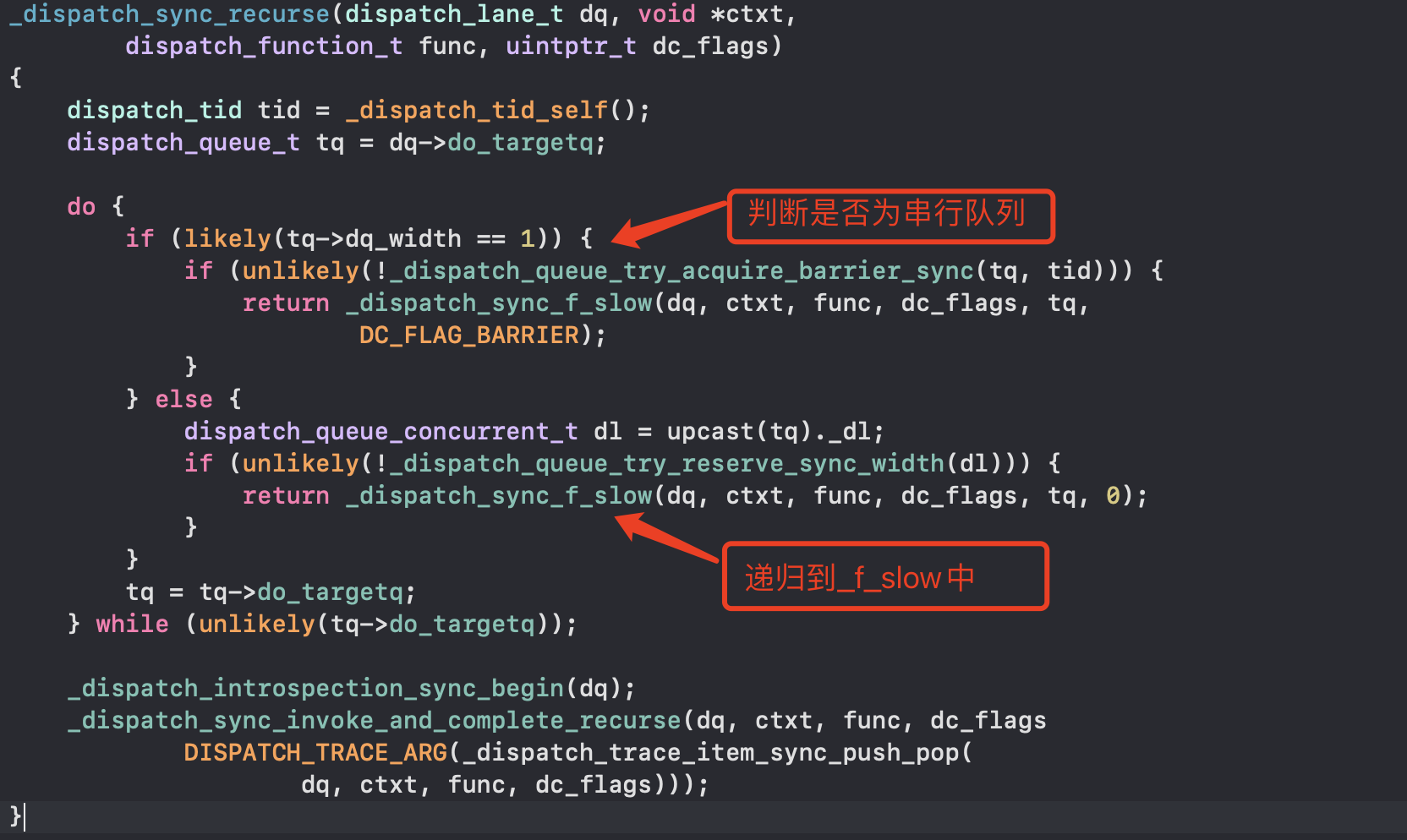
- _dispatch_sync_recurse做了哪些事
- 底层是do while循环,不断的循环递归,相当于block() callout
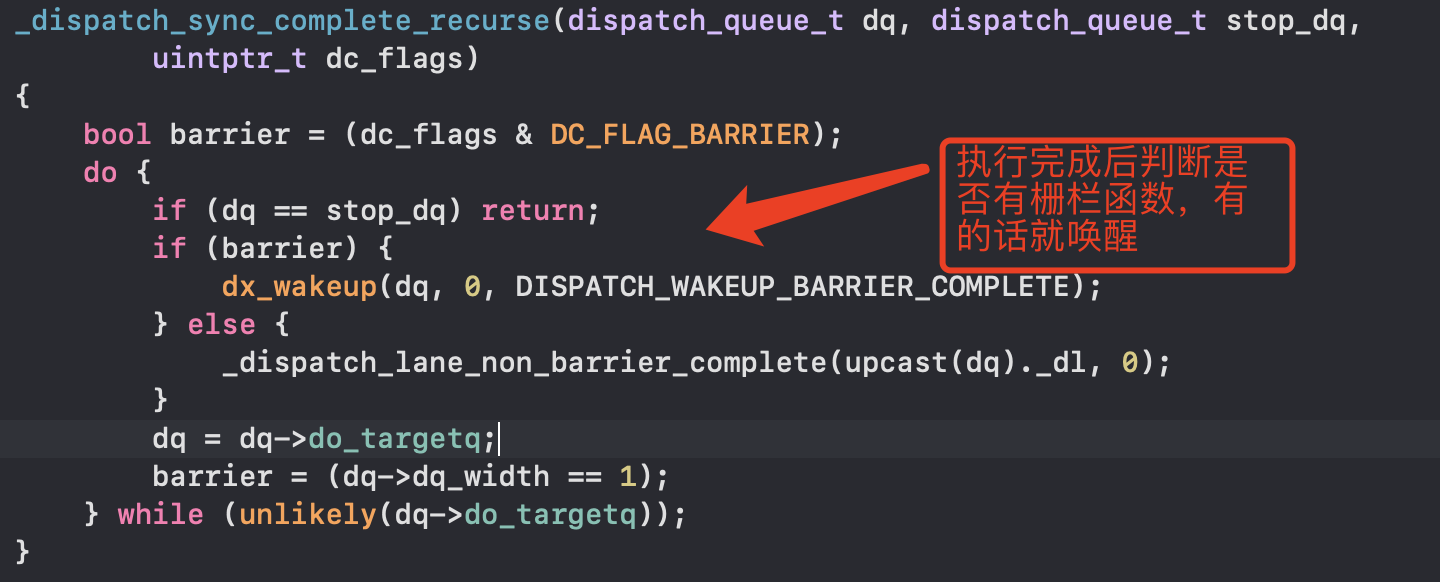
- _dispatch_sync_complete_recurse做了那些事
- dx_wakeup宏定义,赋值不同
- 如果是自定义队列,调用_dispatch_lane_wakeup
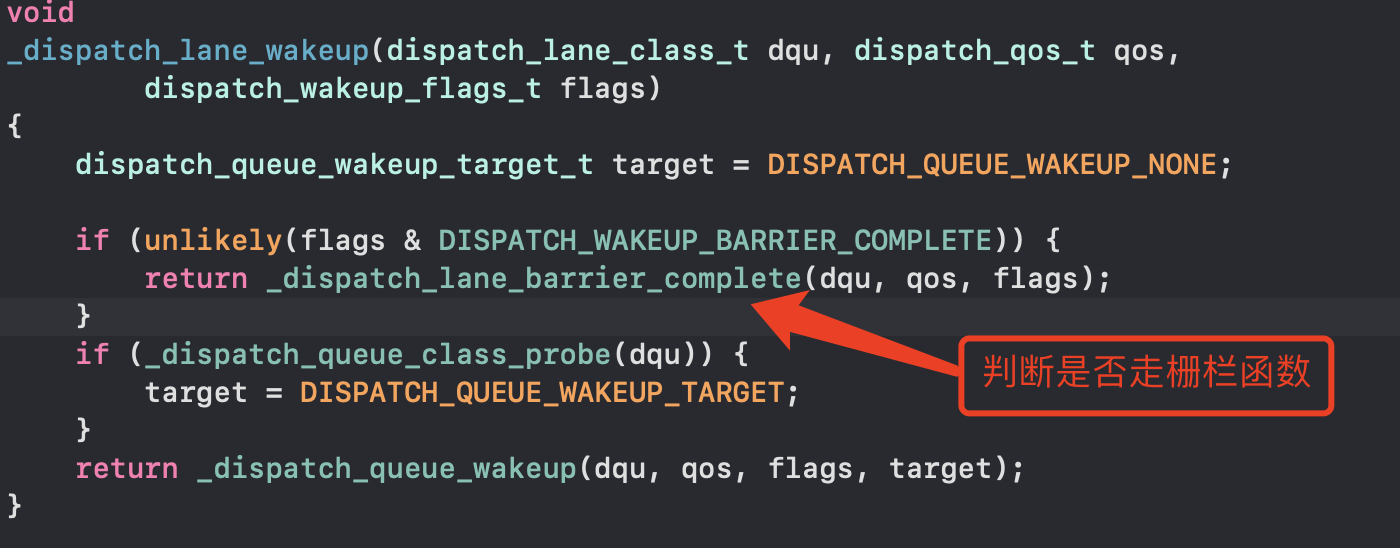
- 如果是全局并发队列,调用_dispatch_root_queue_wakeup

总结
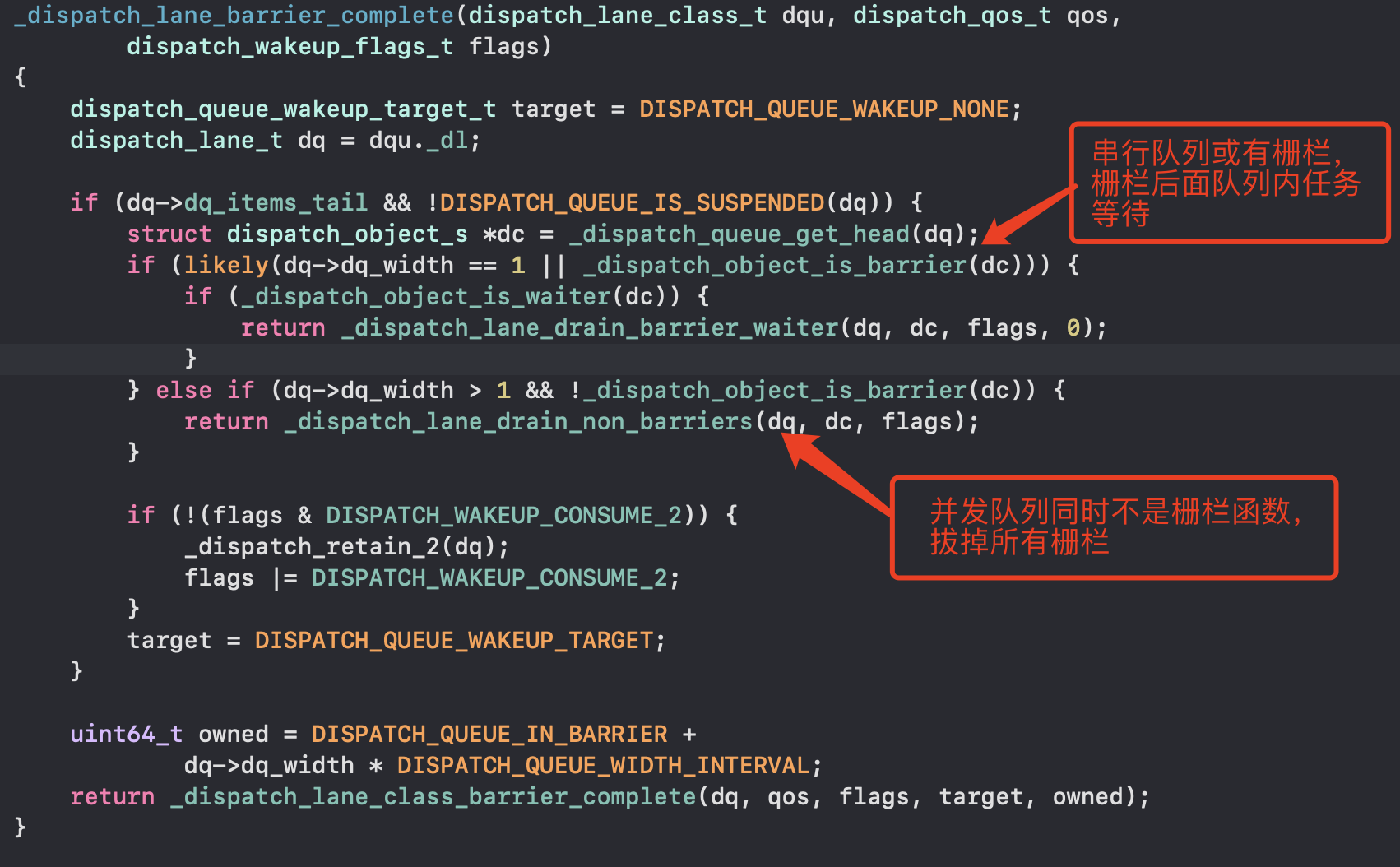
底层是do while循环,会判断队列中的任务是否清空,同时将栅栏函数拔掉,没有任务再calloutBlock
信号量
※以前调度组是封装了信号量,最新版本中则不是,自己又写了一套
dispatch_semaphore_create 创建信号量
- dispatch_semaphore_wait 等待信号量
- dispatch_semaphore_signal 信号量释放
-
举例3
以下代码执行的打印结果为 执行任务1->执行任务2->任务1完成->任务2完成->执行任务3->执行任务4->任务3完成->任务4完成
- 每次执行的任务并发量受信号量大小影响,例如,控制上传、下载数量
- 信号量1代表允许通过1个,通过调整create数量,可以控制队列的最大并发数,应用 -> 一次下载多少个
相当于同步加锁效果
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);dispatch_semaphore_t sem = dispatch_semaphore_create(2);//任务1dispatch_async(queue, ^{dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER); // 等待sleep(2);NSLog(@"执行任务1");NSLog(@"任务1完成");});//任务2dispatch_async(queue, ^{dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);sleep(2);NSLog(@"执行任务2");NSLog(@"任务2完成");dispatch_semaphore_signal(sem); // 发信号});//任务3dispatch_async(queue, ^{dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);sleep(2);NSLog(@"执行任务3");NSLog(@"任务3完成");dispatch_semaphore_signal(sem);});//任务4dispatch_async(queue, ^{dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);sleep(2);NSLog(@"执行任务4");NSLog(@"任务4完成");dispatch_semaphore_signal(sem);});
源码探索
dispatch_semaphore_wait对其sem减1,结果小于0则进入等待,起到一个同步的效果
-
dispatch_semaphore_create
-
dispatch_semaphore_signal
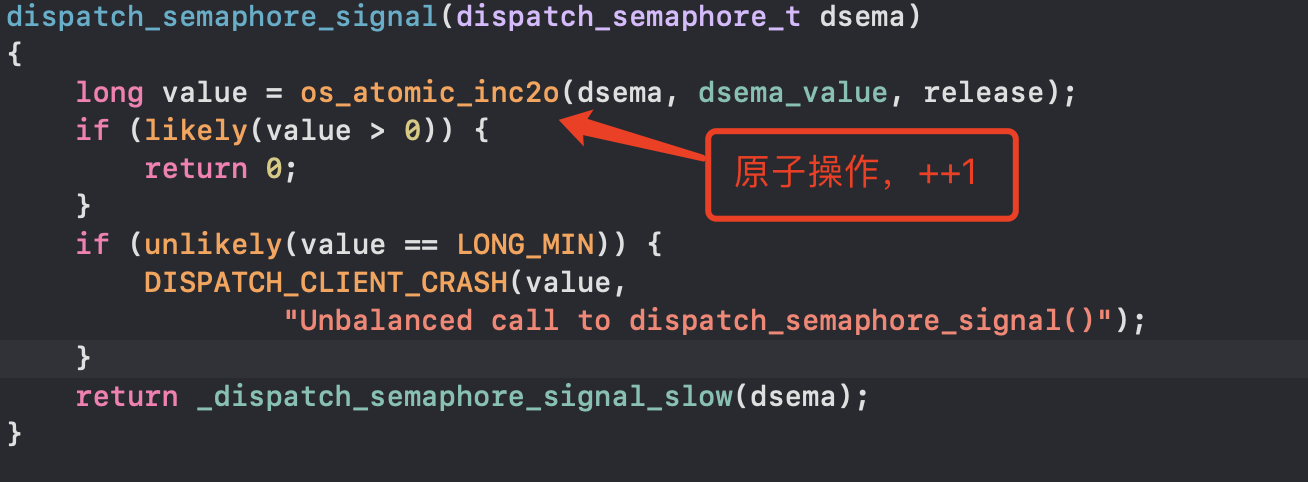
初始为0时,os_atomic_inc2o在原子的信号里进行++操作,如果大于0,则return掉,否则进入_dispatch_semaphore_signal_slow
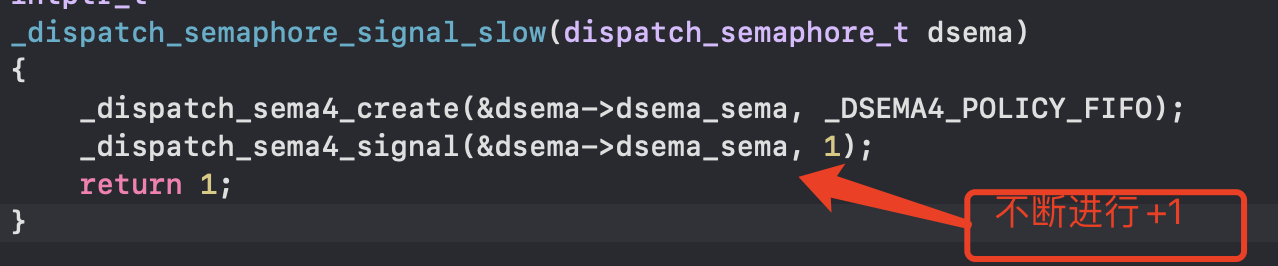
- _dispatch_semaphore_signal_slow,不断自增,返回1
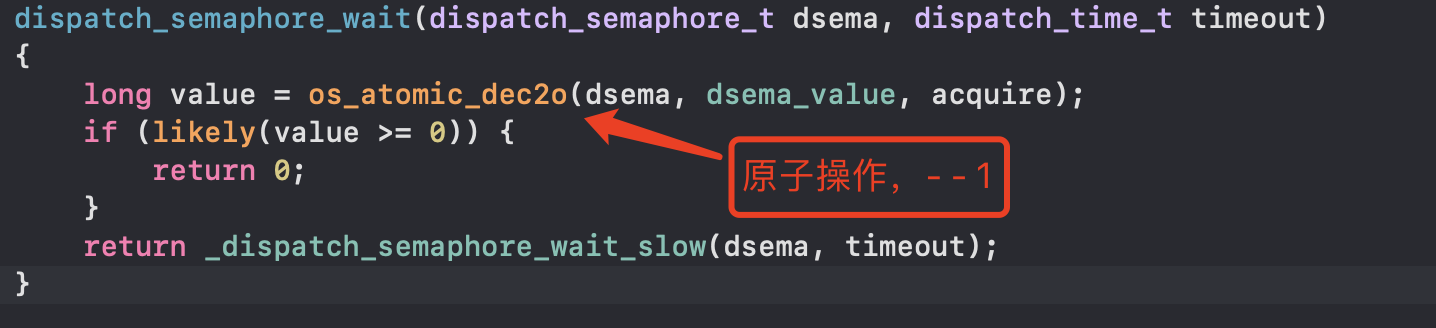
dispatch_semaphore_wait
- 底层本质是do while循环,进入了do while,后面代码就不会执行
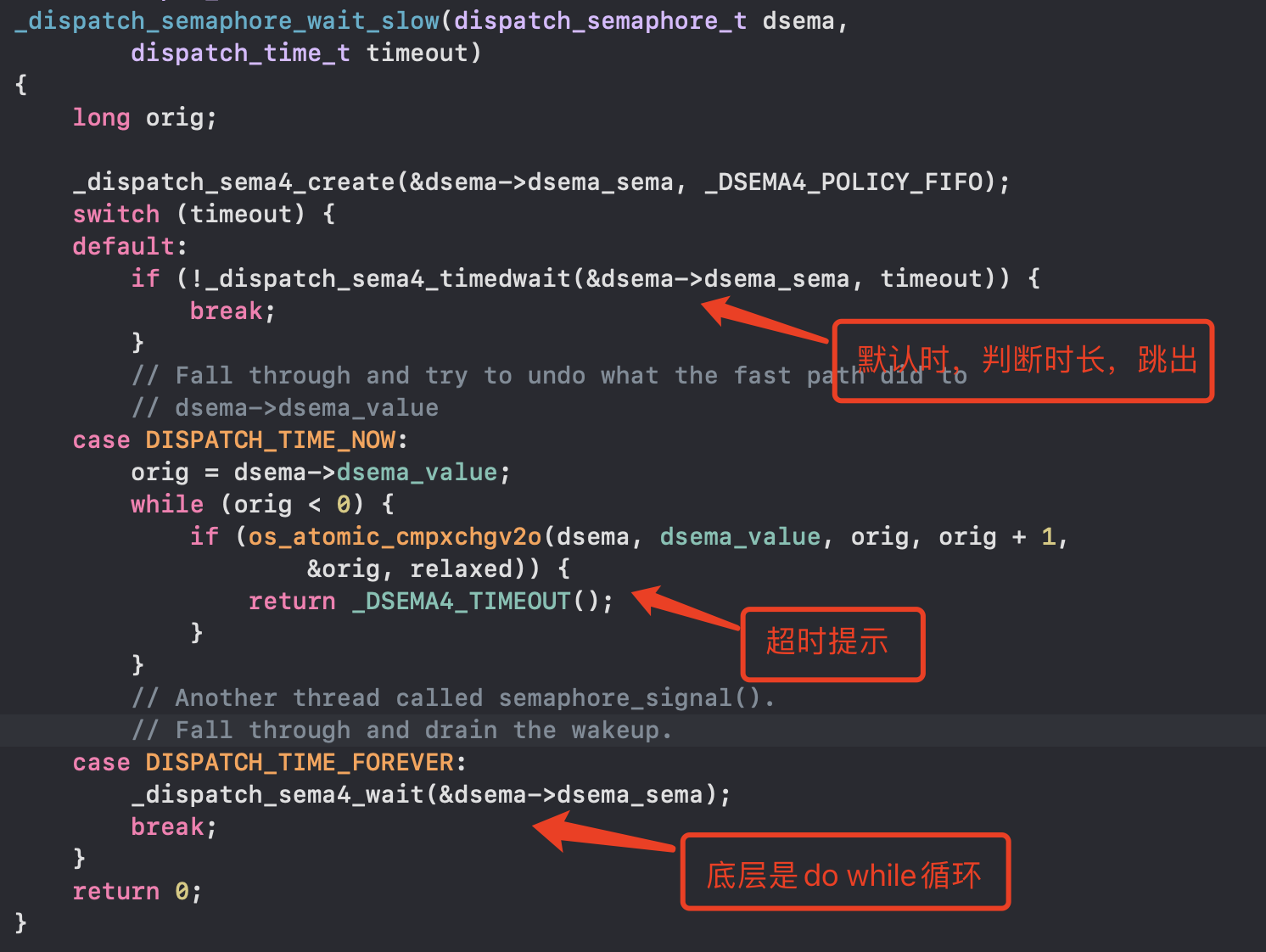
- 初始为0时,进行os_atomic_des2o原子—操作,结果小于0,进入_dispatch_semaphore_wait_slow等待,根据timeout判断等多久
- _dispatch_semaphore_wait_slow等待,根据timeout判断等多久
补充
libdispatch是跨平台库,并不一定有machport,也不支持Mach,进支持posix的平台下,就没有mach port,用的是posix接口sem_wait等完成。sem本质是文件,操作由进程态切系统态后由系统保证文件操作的完整性。XNU下,也就是有Mach内核支持的时候,走的是Mach_sem,调用的是semaphore_wait,需要提供一个mach port完成port name到semaphore文件的转换,XNU是非实时系统,几乎所有需要切内核态的操作都是通过mach port来完成context,结果等的传递。posix下的比如BSD自然不需要mach port,本身semaphore就已经是个文件,不需要转那一步。
任务调度组
源码探索
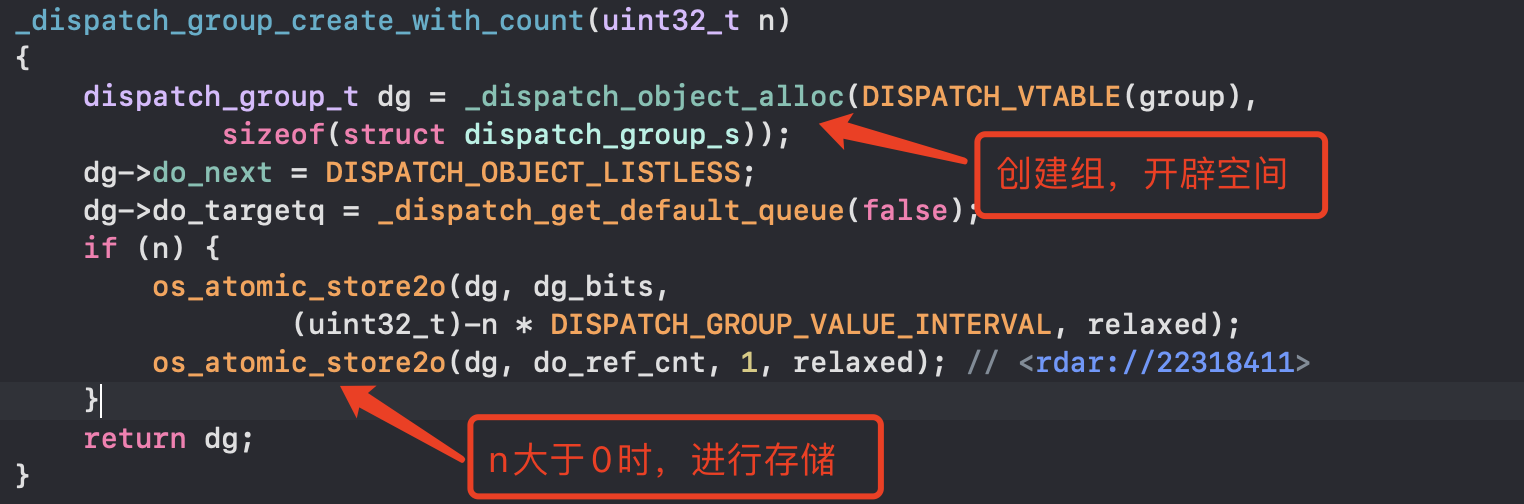
底层dispatch_group_create和_dispatch_group_create_and_enter相似,区别只是传值count不同 ```cpp dispatch_group_create(void) { return _dispatch_group_create_with_count(0); }
_dispatch_group_create_and_enter(void) { return _dispatch_group_create_with_count(1); } ```
- _dispatch_group_create_with_count做了什么
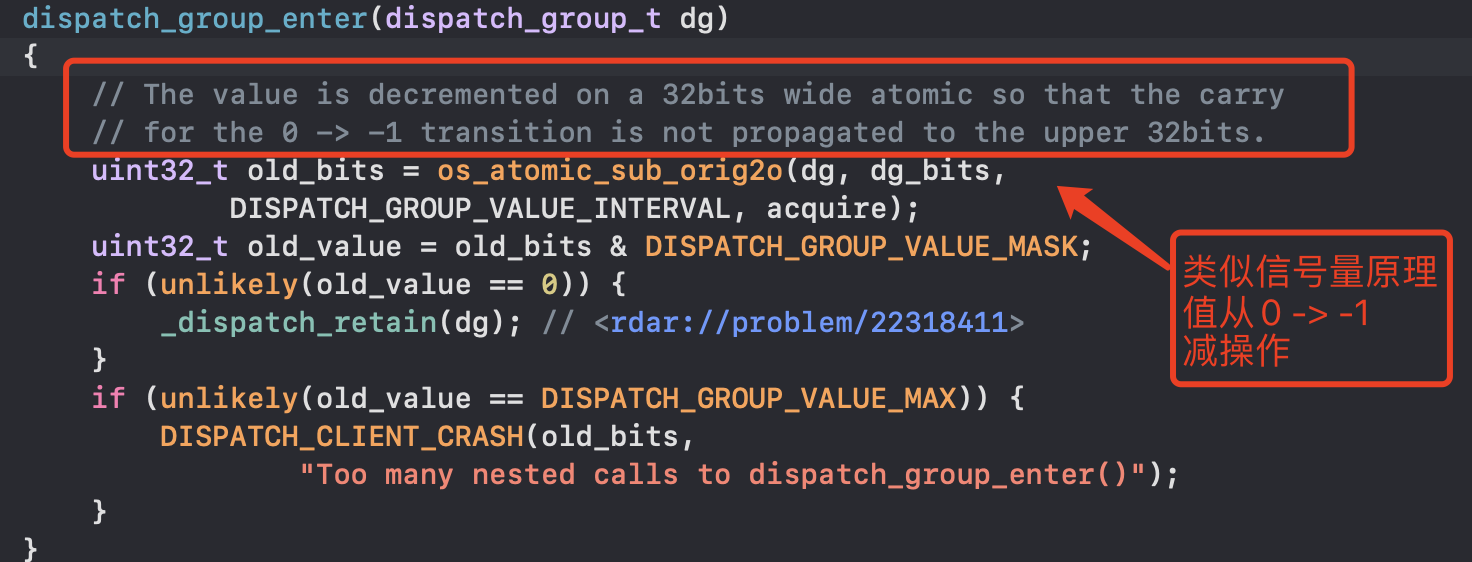
- dispatch_group_enter做了什么 -> 类似信号量,0 -> -1减操作
- dispatch_group_leave做了什么,-1 > 0 类似信号量singal加操作
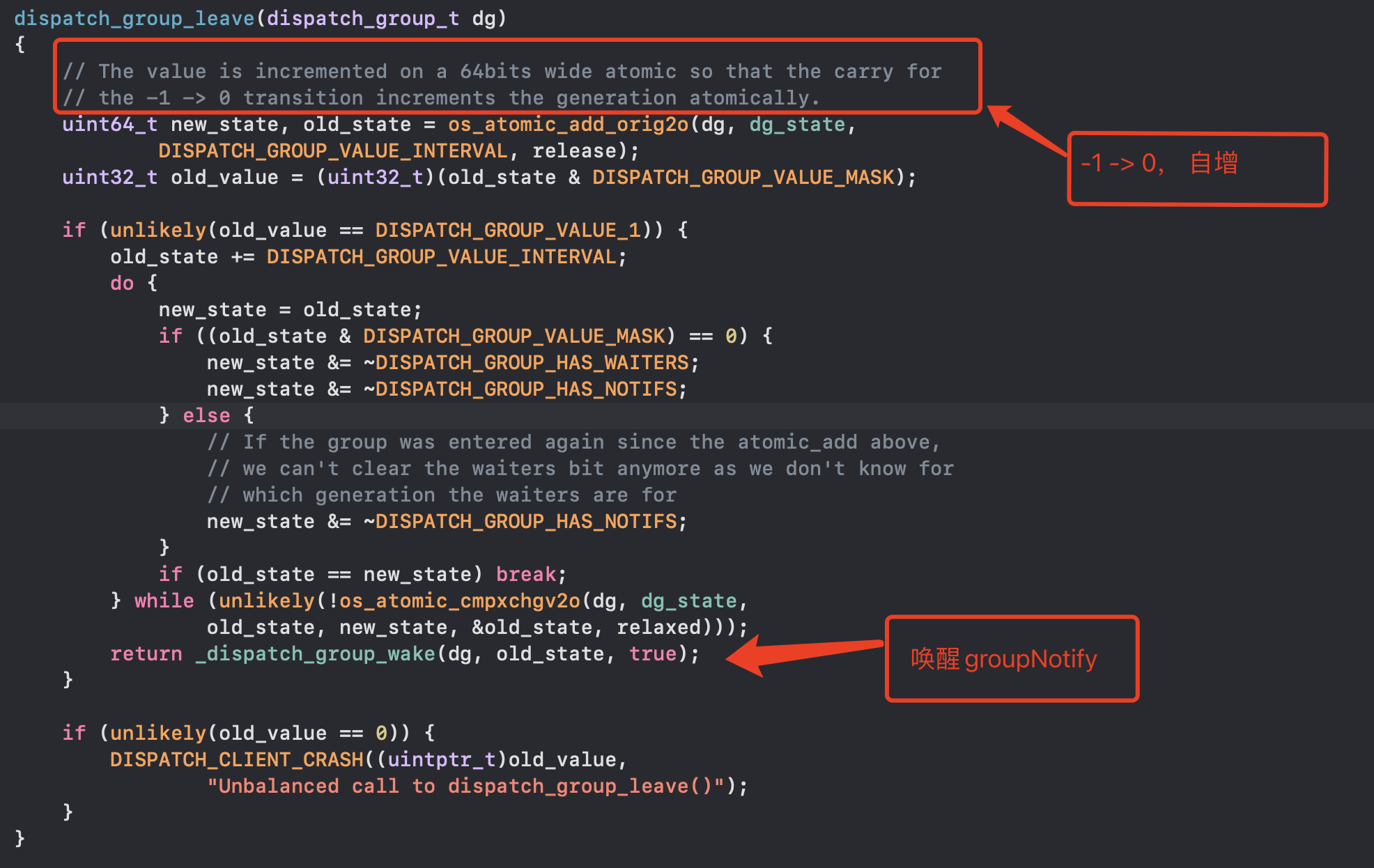
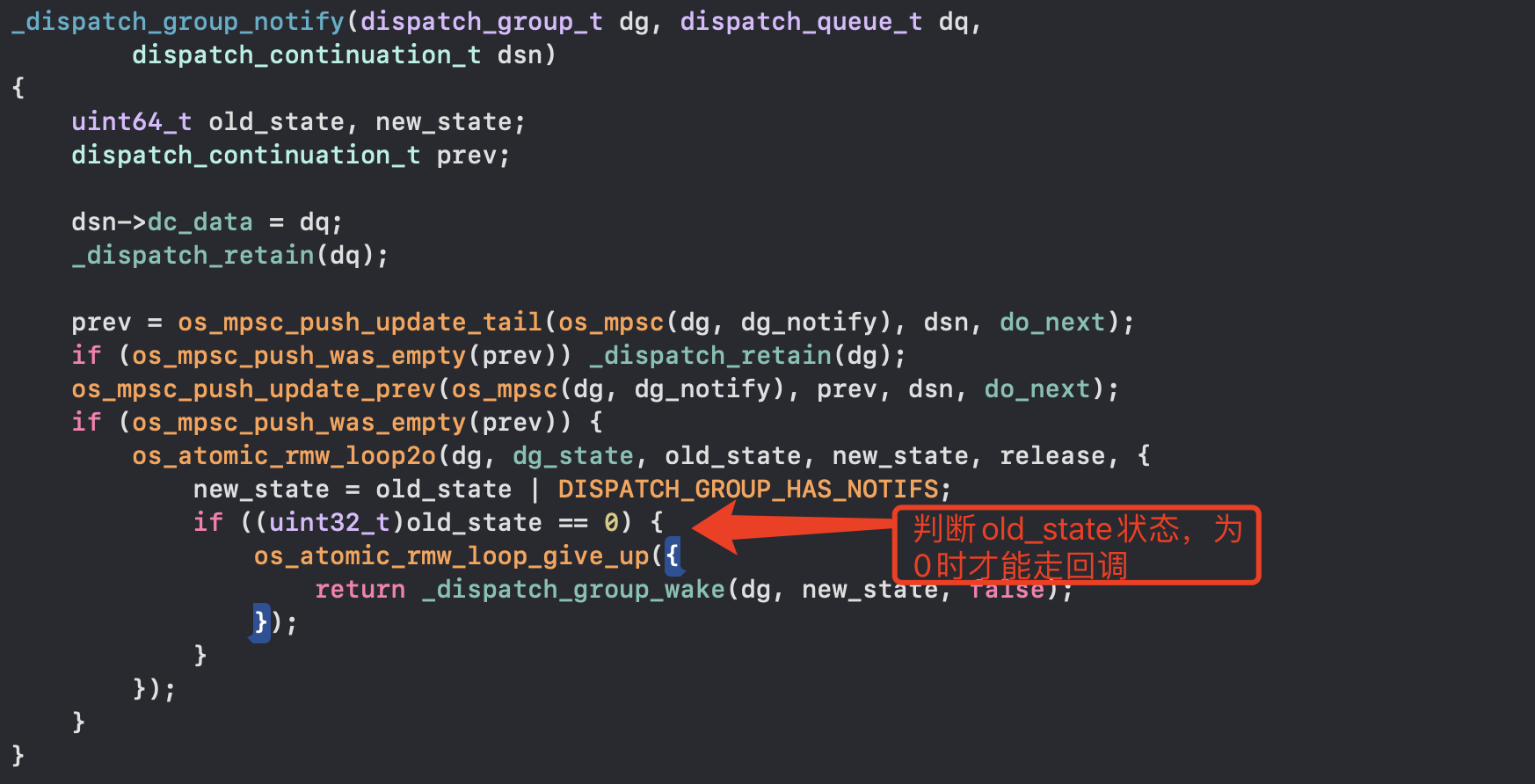
- _dispatch_group_notify做了什么,dispatch_async执行任务时是异步,此时dispatch_group_notify可能已经执行,所以要判断old_state是否为0,只有dispatch_group_leave执行了,将state变为0,才能触发notify的callback
总结
- 调度组本质,enter时0变为-1,leave时-1变为0,调用group_wakeUp时,notify中判断oldValue是否为0,为0才执行block回调
- notify中判断oldValue是否为0同时防止的异步线程的影响
dispatch_group_async相当于封装了dispatch_group_enter和dispatch_group_leave
Dispatch_Source
主要用途是timer计时器,GCD相当于对pthead封装,runloop与GCD同等级(没有归属)
- 通过条件控制一个block执行,并且这个条件在不断变化
- 其CPU负荷非常小,尽量不占用资源
- 主要通过一个条件来控制任务是否执行(block执行),并且条件不断变化
- 联合的优势
- dispatch_source_create 创建源
- dispatch_source_set_event_handler 设置源事件回调
- dispatch_source_merge_data 源事件设置数据
- dispatch_source_get_data 获取源事件数据
- dispatch_resume 继续
- dispatch_suspend 挂起
不受runloop影响,底层是封装了pthread,是workLoop,定时器场合比较多
可变数组线程安全问题
set方法-> 对新值retain,旧值release,本质写入不安全

若有收获,就点个赞吧
0 人点赞
