
同步函数VS异步函数
- 能否开辟线程
- 任务的回调是否具备异步性和同步性
- 同步函数->立即执行,看到效果
- 异步函数->异步执行,不能立刻看到效果
-
死锁分析
举例+源码
运行以下代码,6行是同步函数,将当前线程阻塞,在当前线程执行NSLog(@”3”),会导致死锁 ```cpp
(void)textDemo1{ dispatch_queue_t queue = dispatch_queue_create(“cooci”, NULL); NSLog(@”1”); dispatch_async(queue, ^{
NSLog(@"2");dispatch_sync(queue, ^{NSLog(@"3");});NSLog(@"4");
}); NSLog(@”5”); } ```
stackoverFlow查看崩溃日志
- 最后定位在dispatchsync_f_slow -> **__DISPATCH_WAIT_FOR_QUEUE**
- 提示语句:dispatch_sync called on queue already owned by current thread”
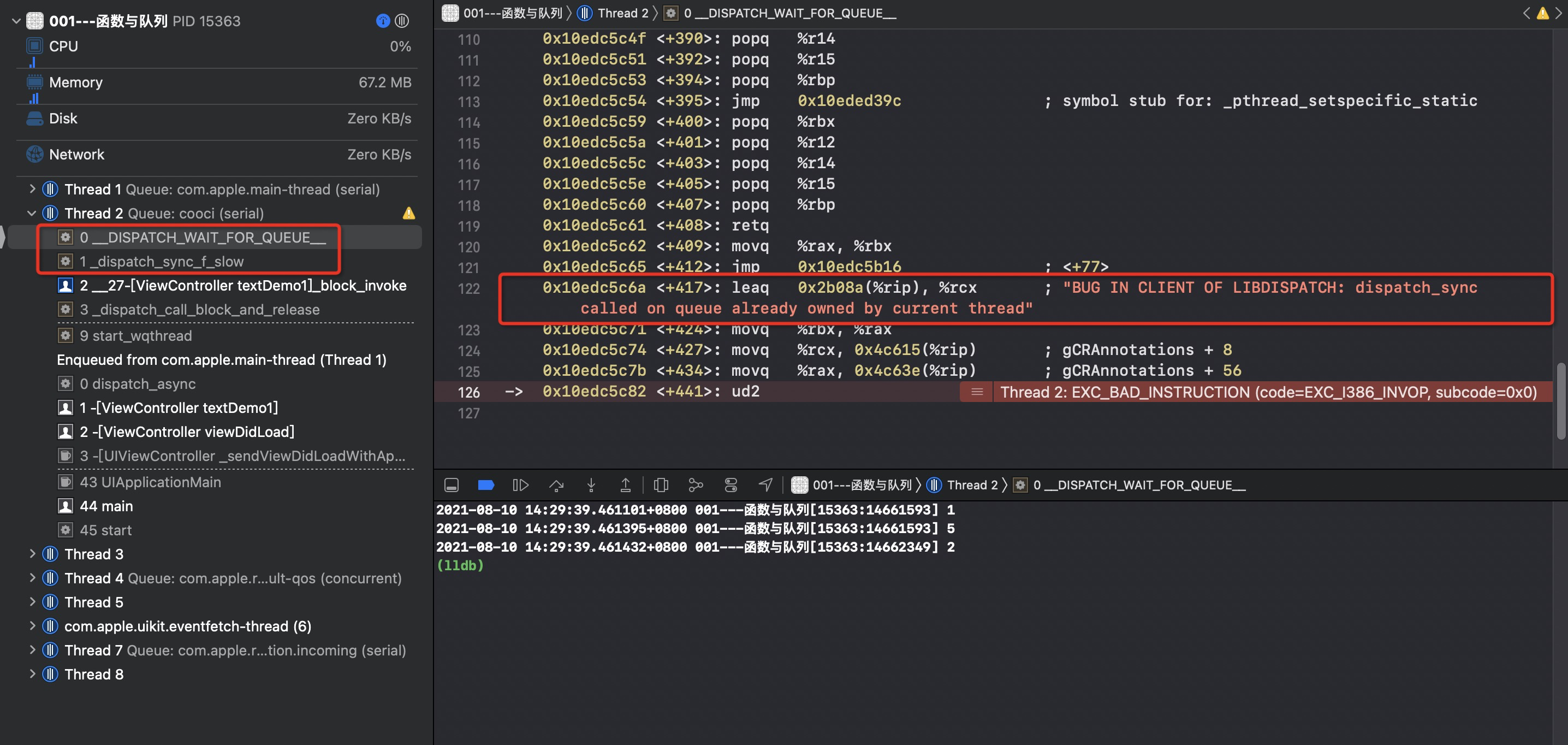
- 查看dispatch_sync底层源码
- dispatchsync -> dispatch_sync_f -> _dispatch_sync_f_inline -> _dispatch_sync_f_slow -> __DISPATCH_WAIT_FOR_QUEUE
- DISPATCH_WAIT_FOR_QUEUE中包含了上述死锁提示语
- 在判断死锁条件中,dsc->dsc_waiter代表线程ID,dq_state代表当前线程状态
- “dispatchsync called on queue “”already owned by current thread”
```cpp
_DISPATCH_WAIT_FOR_QUEUE(dispatch_sync_context_t dsc, dispatch_queue_t dq)
{
uint64_t dq_state = _dispatch_wait_prepare(dq);
if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) {
DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,
} … }"dispatch_sync called on queue ""already owned by current thread");
- 查看_dq_state_drain_locked_by调用,_dq_state_drain_locked_by -> _dispatch_lock_is_locked_by- DLOCK_OWNER_MASK = 0xfffffffc,非常大的值- 只有lock_value ^ tid = 0时,结果才为0,因此判断lock_value == tid时,结果为0```cpp_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid){// equivalent to _dispatch_lock_owner(lock_value) == tidreturn ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;}
结论
当前队列处于等待状态,而又有新的任务来需要队列去调度,因此相互等待,产生死锁。
任务的回调是否具备同步性
同步函数
获取全局并发队列,建立同步函数
针对_dispatch_sync_f_inline函数中的调用下符号断点
- _dispatch_sync_f_slow
- _dispatch_sync_recurse
- _dispatch_introspection_sync_begin
- _dispatch_sync_invoke_and_complete
- _dispatch_sync_function_invoke
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);dispatch_sync(queue, ^{NSLog(@"CC 函数分析");});
程序断点在_dispatch_sync_f_slow函数处
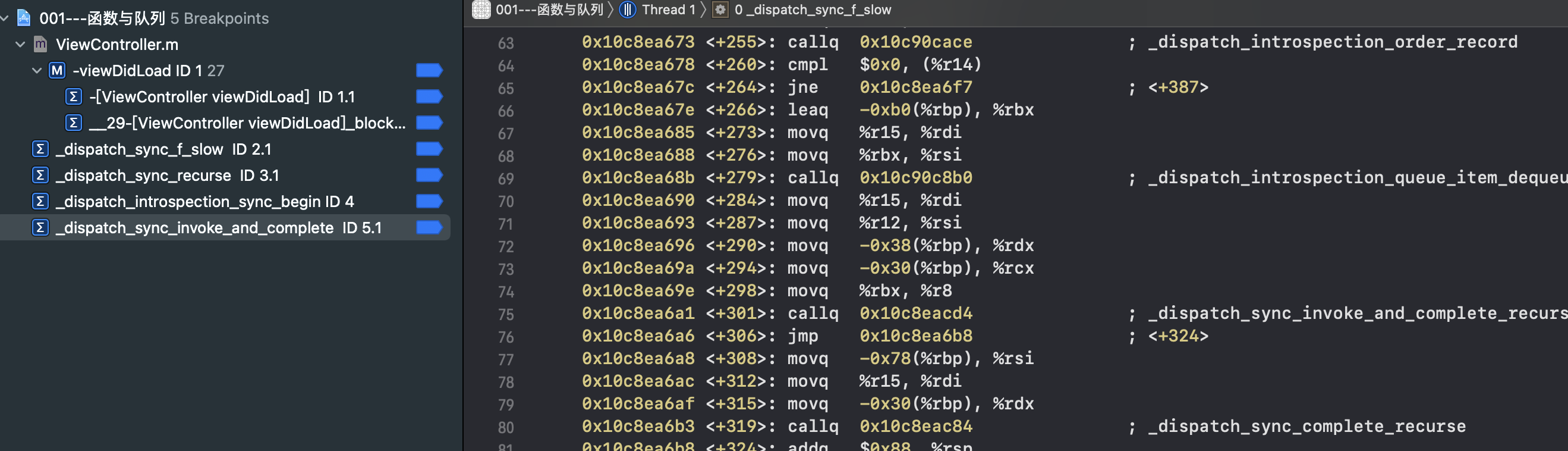
- 继续执行者断点在_dispatch_sync_function_invoke
系统级的队列没有do_targetq,自己创建的则有
if (unlikely(!dq->do_targetq)) {return _dispatch_sync_function_invoke(dq, ctxt, func);}
继续执行,调用_dispatch_sync_function_invoke_inline
- _dispatch_sync_function_invoke_inline中则会调用_dispatch_client_callout,所以全局并发队列会同步执行
```cpp
_dispatch_sync_function_invoke_inline(dispatch_queue_class_t dq, void *ctxt,
{ dispatch_thread_frame_s dtf; _dispatch_thread_frame_push(&dtf, dq); _dispatch_client_callout(ctxt, func); _dispatch_perfmon_workitem_inc(); _dispatch_thread_frame_pop(&dtf); }dispatch_function_t func)
<a name="elGV2"></a>### 异步函数<a name="K3XgN"></a>#### 举例- 创建异步函数,断点在3位置- bt查看堆栈信息,以此为依据探索_dispatch_worker_thread2等在底层的封装调用```cppdispatch_queue_t queue = dispatch_queue_create("CC", DISPATCH_QUEUE_CONCURRENT);dispatch_async(queue, ^{NSLog(@"CC 函数分析");});frame #1: 0x000000010add5578 libdispatch.dylib`_dispatch_call_block_and_release + 12frame #2: 0x000000010add674e libdispatch.dylib`_dispatch_client_callout + 8frame #3: 0x000000010add9066 libdispatch.dylib`_dispatch_continuation_pop + 557frame #4: 0x000000010add847b libdispatch.dylib`_dispatch_async_redirect_invoke + 770frame #5: 0x000000010ade81b0 libdispatch.dylib`_dispatch_root_queue_drain + 351frame #6: 0x000000010ade8b0f libdispatch.dylib`_dispatch_worker_thread2 + 135frame #7: 0x000000010b2a9453 libsystem_pthread.dylib`_pthread_wqthread + 244frame #8: 0x000000010b2a8467 libsystem_pthread.dylib`start_wqthread + 15
源码
- dispatch_async底层调用_dispatch_continuation_async
_dispatch_continuation_async中dx_push宏调用dp_push
dispatch_async(dispatch_queue_t dq, dispatch_block_t work){dispatch_continuation_t dc = _dispatch_continuation_alloc();uintptr_t dc_flags = DC_FLAG_CONSUME;dispatch_qos_t qos;qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);}
dp_push多处被赋值,以.dq_push = _dispatch_lane_concurrent_push为例
- 先判断是否存在barrier,如果存在barrier,会控制流程return回去
否则执行_dispatch_lane_push
_dispatch_lane_concurrent_push(dispatch_lane_t dq, dispatch_object_t dou,dispatch_qos_t qos){// <rdar://problem/24738102&24743140> reserving non barrier width// doesn't fail if only the ENQUEUED bit is set (unlike its barrier// width equivalent), so we have to check that this thread hasn't// enqueued anything ahead of this call or we can break orderingif (dq->dq_items_tail == NULL &&!_dispatch_object_is_waiter(dou) &&!_dispatch_object_is_barrier(dou) &&_dispatch_queue_try_acquire_async(dq)) {return _dispatch_continuation_redirect_push(dq, dou, qos);}_dispatch_lane_push(dq, dou, qos);}
dp被赋值不同,一般都会执行到_dispatch_lane_push
- 流程,_dispatch_lane_push -> dx_wakeup -> _dispatch_queue_wakeup
- _dispatch_root_queue_push -> _dispatch_root_queue_push_inline -> _dispatch_root_queue_poke -> _dispatch_root_queue_poke_slow
- _dispatch_root_queue_poke_slow底层源码
- _dispatch_root_queues_init,线程池、队列初始化及任务_dispatch_worker_thread2封装
- 判断如果是全局队列,则创建线程执行任务
- 判断如果是普通队列,进行do while循环
- 从线程池中获取线程,执行任务,同时判断线程池的变化
- 当前可用线程数大于可请求线程,报异常,释放掉剩余线程与可请求线程的差值
- 当前可用线程为0时,打印当前线程池已满
- 当前线程池最大数量thread_pool_size为255,栈空间一定的情况下,能开辟的线程数和线程大小成反比,最多能开辟1GB / 16KB = 64 * 1024大小
- 主线程1MB,子线程512KB
- 从线程池中获取线程,执行任务,同时判断线程池的变化

static void_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor){..._dispatch_root_queues_init();...#if DISPATCH_USE_PTHREAD_ROOT_QUEUESif (dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE)#endif{_dispatch_root_queue_debug("requesting new worker thread for global ""queue: %p", dq);r = _pthread_workqueue_addthreads(remaining,_dispatch_priority_to_pp_prefer_fallback(dq->dq_priority));(void)dispatch_assume_zero(r);return;}...int can_request, t_count;// seq_cst with atomic store to tail <rdar://problem/16932833>t_count = os_atomic_load2o(dq, dgq_thread_pool_size, ordered);do {can_request = t_count < floor ? 0 : t_count - floor;if (remaining > can_request) {_dispatch_root_queue_debug("pthread pool reducing request from %d to %d",remaining, can_request);os_atomic_sub2o(dq, dgq_pending, remaining - can_request, relaxed);remaining = can_request;}if (remaining == 0) {_dispatch_root_queue_debug("pthread pool is full for root queue: ""%p", dq);return;}} while (!os_atomic_cmpxchgv2o(dq, dgq_thread_pool_size, t_count,t_count - remaining, &t_count, acquire));
- **_dispatch_root_queues_init**()- 底层dispatch_once_f单例,表示当前任务只执行一次
_dispatch_root_queues_init(void){dispatch_once_f(&_dispatch_root_queues_pred, NULL,_dispatch_root_queues_init_once);}
- **_dispatch_root_queues_init_once源码中,将_dispatch_worker_thread2封装到了pthread的Api,GCD对pthread的封装**- **无论iOS、Android还是java都是对phread进行了封装**- **通过workloop调用,异步执行,调用时机与os(cpu调度处理)有关**- **总结:_dispatch_root_queues_init以单例形式进行了 线程池初始化、工作队列配置、工作队列配置以及对_dispatch_worker_thread2任务的封装**
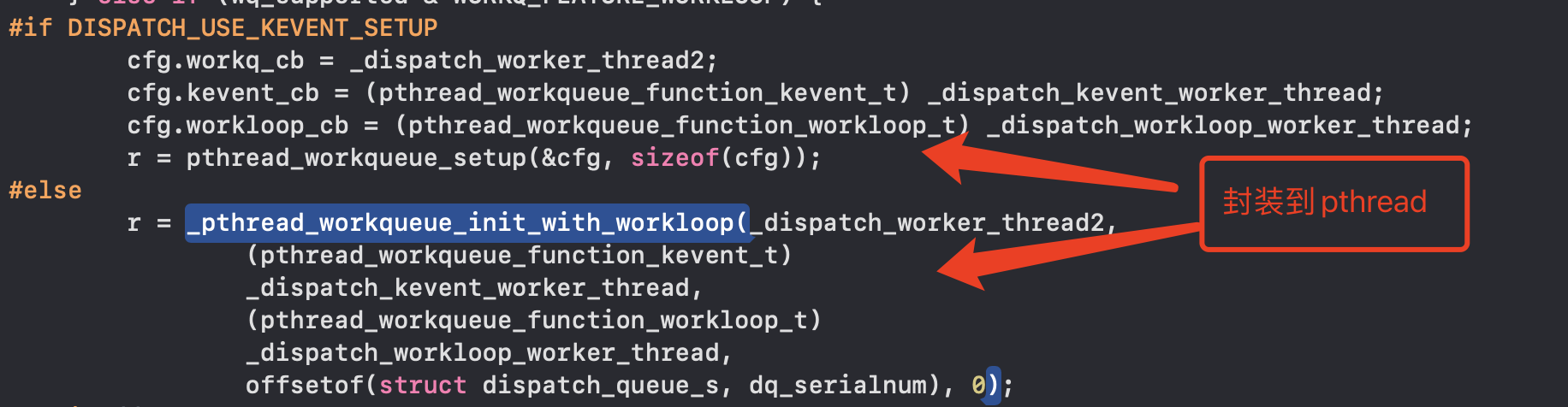
单例底层原理
Q:单例是否具备线程安全
dispatch_once底层源码
- 通过条件控制,得到单例
- val 即全局静态变量,传入的onceToken
- onceToken在程序执行过程中变化:
- 初始值为0
- 执行过程中变为了256
- 在return前变为了-1
- onceToken在程序执行过程中变化:
dispatch_once底层调用了dispatch_once_f函数,除了传入的val、block,还封装了invoke
dispatch_once(dispatch_once_t *val, dispatch_block_t block){dispatch_once_f(val, block, _dispatch_Block_invoke(block));}
dispatch_once_f底层源码
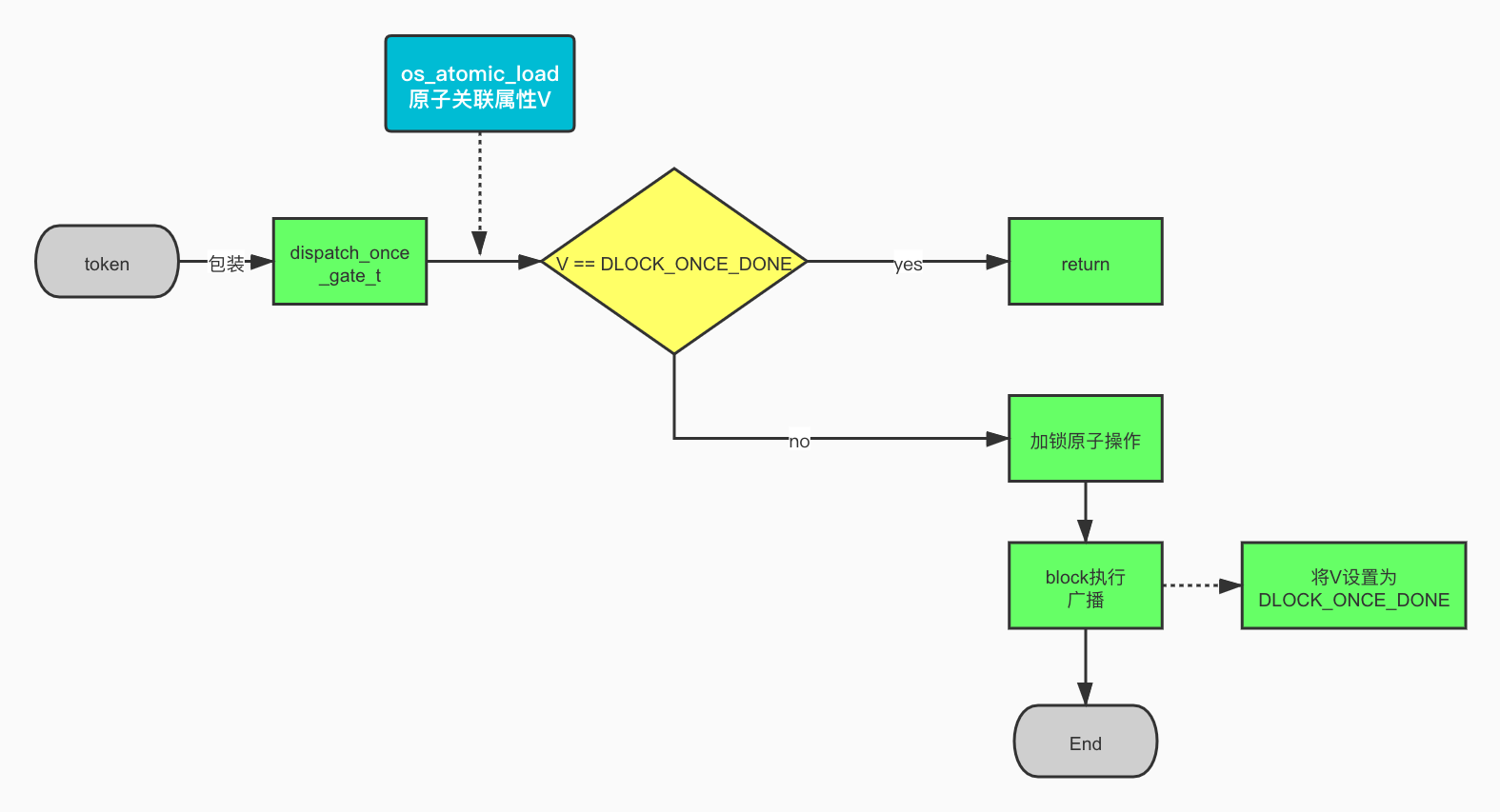
首先dispatch_once_gate_t对val类型进行转换
- 然后条件判断状态为DLOCK_ONCE_DONE时表明已经处理过,直接return
- _dispatch_once_gate_tryenter-> 第一次进来时,获取锁,原子操作多线程处理
- _dispatch_once_callout回调执行
- _dispatch_once_wait,多线程时,没有获取到锁,则开启自旋锁进行等待,当发现其它线程设置了once_done则放弃 ```cpp dispatch_once_f(dispatch_once_t val, void ctxt, dispatch_function_t func) { dispatch_once_gate_t l = (dispatch_once_gate_t)val;
if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTER
uintptr_t v = os_atomic_load(&l->dgo_once, acquire);if (likely(v == DLOCK_ONCE_DONE)) {return;}
if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
if (likely(DISPATCH_ONCE_IS_GEN(v))) {return _dispatch_once_mark_done_if_quiesced(l, v);}
endif
endif
if (_dispatch_once_gate_tryenter(l)) {return _dispatch_once_callout(l, ctxt, func);}return _dispatch_once_wait(l);
}
- _dispatch_once_gate_tryenter(l) 原子操作,线程加锁保护,_dispatch_lock_value_for_self对当前线程加锁```cpp_dispatch_once_gate_tryenter(dispatch_once_gate_t l){return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,(uintptr_t)_dispatch_lock_value_for_self(), relaxed);}
- _dispatch_once_callout执行回调和广播
- dispatch_once_f中对传入的val(static dispatch_once_token)进行封装,封装为dispatch_once_gate_t,这个变量用来获取底层原子性的一个关联。关联一个uintptr_t类型的变量v,用来查询。
- 当前的onceToken是一个全局静态变量。根据每个单例不同,静态变量也不同。为了保证唯一性,底层使用了类似KVC的的形式通过os_atomic_load出来,如果状态为DLOCK_ONCE_DONE,直接return。
- 当第一次代码执行进来时,为保证线程的安全性,把自己锁起来,保证当前执行任务的唯一性。锁住之后进行block的调用执行,执行完毕解锁,同时将变量v的值置为DLOCK_ONCE_DONE(下次执行直接return),保证了单例的唯一性。
单例如何销毁
- 通过修改onceToken的值可以达到销毁的目的 ```objectivec
(void)dealloc {
predicate = 0; class = nil; }
同时这两部分提取出来,放到类中 static Object *class = nil; static dispatch_once_t onceToken; ```

若有收获,就点个赞吧
0 人点赞
