
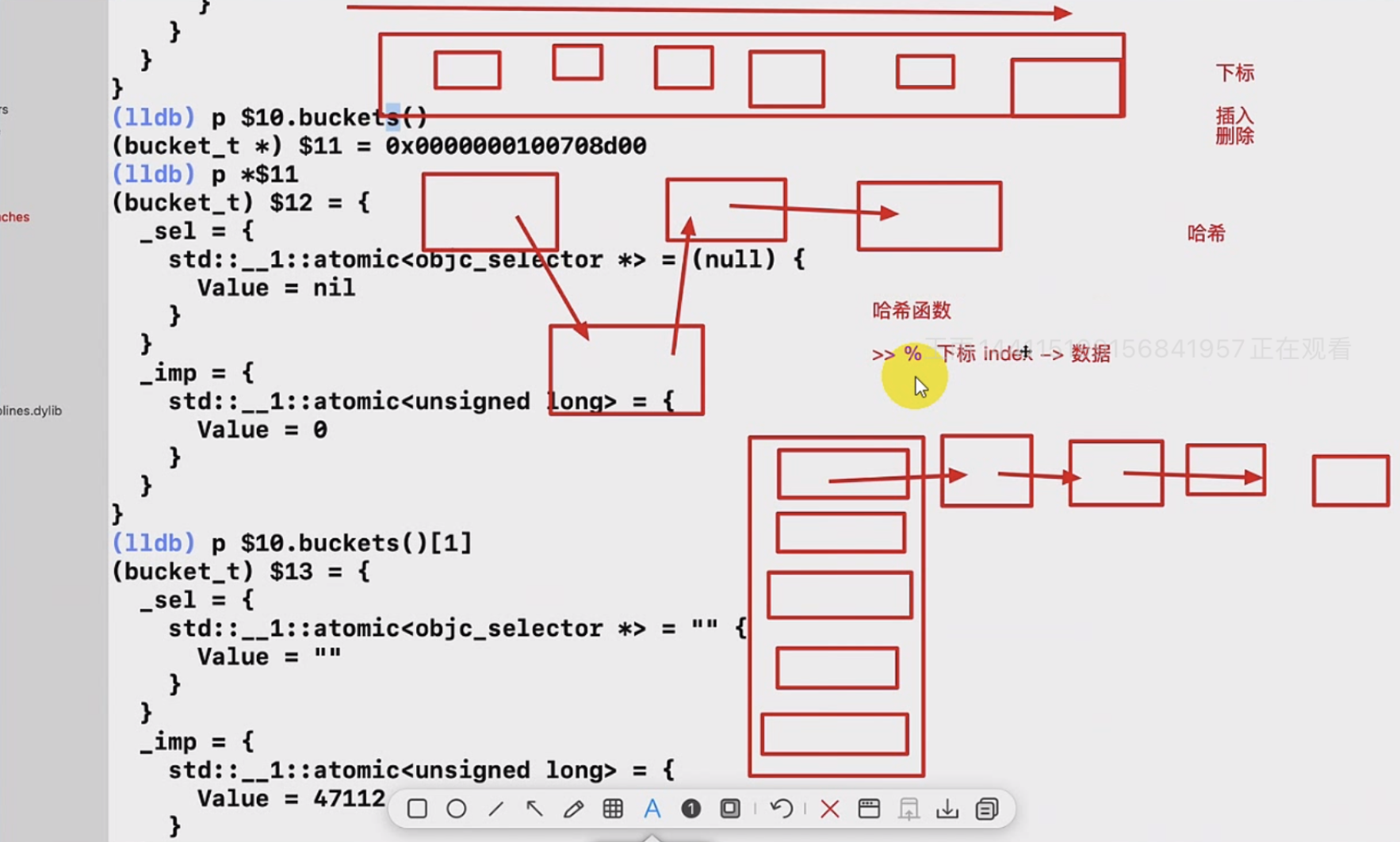
Hash函数
- 数组是按顺序排列,因此按下标可以快速查找取值,但插入、删除要移动整个数组,非常耗时
- 链表是按链式存储,插入、删除很方便,但查找具体某一个值很耗时
- Hash函数则结合了二者的优点,通过取余或者除 等操作快速定位下标,然后出现hash冲突时用链式存取
LLDB调试
首先建立Person类,获取其Class
LGPerson *p = [LGPerson alloc];Class pClass = [LGPerson class];
通过LLDB,得到cache_t结构,cache_t是缓存的话,一般我们要找到其缓存的SEL、IMP,
(lldb) p/x pClass(Class) $0 = 0x0000000100008400 LGPerson(lldb) p (cache_t *)0x0000000100008410 // 位移16 0x10(cache_t *) $1 = 0x0000000100008410(lldb) p *$1(cache_t) $2 = {_bucketsAndMaybeMask = {std::__1::atomic<unsigned long> = {Value = 4436902816}}= {= {_maybeMask = {std::__1::atomic<unsigned int> = {Value = 0}}_flags = 32808_occupied = 0}_originalPreoptCache = {std::__1::atomic<preopt_cache_t *> = {Value = 0x0000802800000000}}}}
在cache_t源码中,看到了一个bucket_t的结构体,点进去查看其结构,即包含了SEL和IMP
#if __arm64__explicit_atomic<uintptr_t> _imp;explicit_atomic<SEL> _sel;#elseexplicit_atomic<SEL> _sel;explicit_atomic<uintptr_t> _imp;#endif
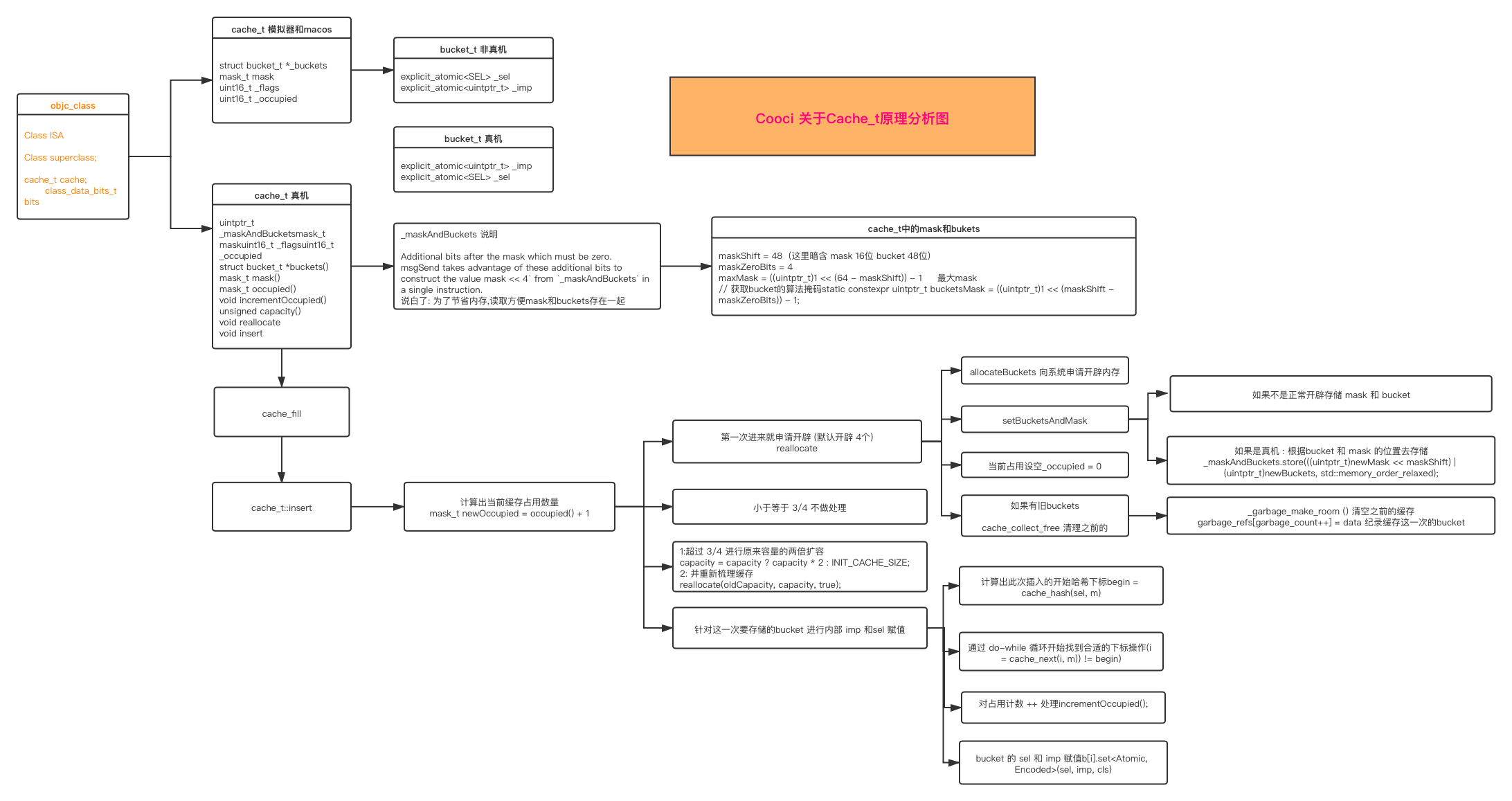
cache_t数据结构
- cache存储的是cache_t地址指针,即首地址指针
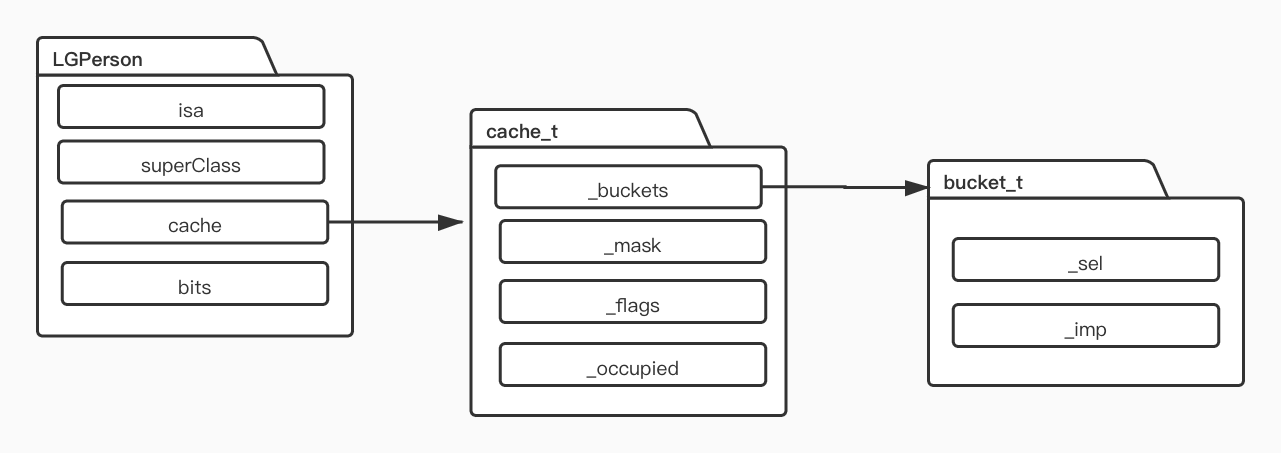
- _bucketsAndMaybeMask同时存储了buckets和mask,方便存取
struct cache_t {private:explicit_atomic<uintptr_t> _bucketsAndMaybeMask;union {struct {explicit_atomic<mask_t> _maybeMask;#if __LP64__ //代表Macos或Unix架构 X86_64uint16_t _flags;#endifuint16_t _occupied;};explicit_atomic<preopt_cache_t *> _originalPreoptCache;};...}
接着进行上面的LLDB调试,发现执行p $2._bucketsAndMaybeMask()等语法都无法进行下一步调试,这时候就要去源码里找方法,在源码中有如下方法返回结构体指针
struct bucket_t *buckets() const;
因此,可以p $2.buckets(),此时得到结果Value都是nil,因为没有调用方法。
(lldb) p $2.buckets()(bucket_t *) $3 = 0x000000010875c3a0(lldb) p *$3(bucket_t) $4 = {_sel = {std::__1::atomic<objc_selector *> = (null) {Value = nil}}_imp = {std::__1::atomic<unsigned long> = {Value = 0}}}
在调用方法后, cache_t有值,但是buckets没有值,因为buckets是hash,无序的,其0位不一定有值,经测试在p $10.buckets()[6]后拿到含值得数据结构
(lldb) p *$8(cache_t) $10 = {_bucketsAndMaybeMask = {std::__1::atomic<unsigned long> = {Value = 4442067904}}= {= {_maybeMask = {std::__1::atomic<unsigned int> = {Value = 7}}_flags = 32808_occupied = 1}_originalPreoptCache = {std::__1::atomic<preopt_cache_t *> = {Value = 0x0001802800000007}}}}(lldb) p $10.buckets()(bucket_t *) $11 = 0x0000000108c493c0(lldb) p *$11(bucket_t) $12 = {_sel = {std::__1::atomic<objc_selector *> = (null) {Value = nil}}_imp = {std::__1::atomic<unsigned long> = {Value = 0}}}(lldb) p $10.buckets()[6](bucket_t) $19 = {_sel = {std::__1::atomic<objc_selector *> = "" {Value = ""}}_imp = {std::__1::atomic<unsigned long> = {Value = 47248}}}
接着执行源码中的sel()方法,拿到saySomething函数, imp函数得到其实现
(lldb) p $19.sel()(SEL) $20 = "saySomething"(lldb) p $19.imp(nil, pClass)(IMP) $21 = 0x0000000100003c90 (KCObjcBuild`-[LGPerson saySomething])
LLDB在调试过程中出错的话,就要重新来一次,很不方便,我们可以模拟底层自建类_objc_class
typedef uint32_t mask_t; // x86_64 & arm64 asm are less efficient with 16-bitsstruct kc_bucket_t {SEL _sel;IMP _imp;};struct kc_cache_t {struct kc_bucket_t *_bukets; // 8mask_t _maybeMask; // 4uint16_t _flags; // 2uint16_t _occupied; // 2};struct kc_class_data_bits_t {uintptr_t bits;};// cache classstruct kc_objc_class {Class isa;Class superclass;struct kc_cache_t cache; // formerly cache pointer and vtablestruct kc_class_data_bits_t bits;};
将pClass赋值给自定义的kc_objc_class, 并循环打印buckets
LGPerson *p = [LGPerson alloc];Class pClass = p.class; // objc_clas[p say1];[p say2];[p say3];[p say4];[p say1];[p say2];[pClass sayHappy];struct kc_objc_class *kc_class = (__bridge struct kc_objc_class *)(pClass);NSLog(@"%hu - %u",kc_class->cache._occupied,kc_class->cache._maybeMask);for (mask_t i = 0; i<kc_class->cache._maybeMask; i++) {struct kc_bucket_t bucket = kc_class->cache._bukets[i];NSLog(@"%@ - %pf",NSStringFromSelector(bucket._sel),bucket._imp);}
打印结果如下,4-7是什么意思?答案就在底层源码
LGPerson say : -[LGPerson say1]LGPerson say : -[LGPerson say2]LGPerson say : -[LGPerson say3]LGPerson say : -[LGPerson say4]LGPerson say : -[LGPerson say1]LGPerson say : -[LGPerson say2]4 - 7
在函数调用时,底层会调用void insert(SEL sel, IMP imp, id receiver),即对消息接受者插入一个sel和imp
- 初始occupied为0,第一次调用时:
- occupied值变为1,同时capacity容积为1<<2等于4,然后创建一个桶,将桶的指针存储在cache_t中
- occupied每次进来都会+1,当newOccpied+1小于最大容积的3/4时,进行两倍扩容。
- 扩容首先开辟2倍内存,比如原来是3(原有内存已经开辟好,不能修改),那么新开辟8大小,数组复制非常消耗性能,通过垃圾袋将3(原来)中的buckets回收,再将新的bucket缓存到新开辟的内存中,再次调用被回收的方法时,会重新hash插入桶子
通过cache_hash得到下标位置,do while循环找空地址插入桶子
void cache_t::insert(SEL sel, IMP imp, id receiver){runtimeLock.assertLocked();// Use the cache as-is if until we exceed our expected fill ratio.mask_t newOccupied = occupied() + 1; // occupied初始为0, 调用时+1unsigned oldCapacity = capacity(), capacity = oldCapacity;if (slowpath(isConstantEmptyCache())) { // 第一次调用// Cache is read-only. Replace it.if (!capacity) capacity = INIT_CACHE_SIZE; // 1<<2 得到4reallocate(oldCapacity, capacity, /* freeOld */false); //创建一个桶, 将桶的指针存在cache_t中}else if (fastpath(newOccupied + CACHE_END_MARKER <= cache_fill_ratio(capacity))) { //保证缓存表存的方法数量小于等于容量的3/4// Cache is less than 3/4 or 7/8 full. Use it as-is.}#if CACHE_ALLOW_FULL_UTILIZATIONelse if (capacity <= FULL_UTILIZATION_CACHE_SIZE && newOccupied + CACHE_END_MARKER <= capacity) {// Allow 100% cache utilization for small buckets. Use it as-is.}#endifelse { // 4 * 2 = 8capacity = capacity ? capacity * 2 : INIT_CACHE_SIZE; //两倍扩容if (capacity > MAX_CACHE_SIZE) {capacity = MAX_CACHE_SIZE;}reallocate(oldCapacity, capacity, true);}bucket_t *b = buckets();mask_t m = capacity - 1; // 4 - 1 = 3mask_t begin = cache_hash(sel, m); // hash得到开始地址mask_t i = begin;// Scan for the first unused slot and insert there.// There is guaranteed to be an empty slot.do { // 循环插入SEL和IMPif (fastpath(b[i].sel() == 0)) {incrementOccupied();b[i].set<Atomic, Encoded>(b, sel, imp, cls());return;}if (b[i].sel() == sel) {// The entry was added to the cache by some other thread// before we grabbed the cacheUpdateLock.return;}} while (fastpath((i = cache_next(i, m)) != begin));bad_cache(receiver, (SEL)sel);#endif // !DEBUG_TASK_THREADS}
总结
```objectivec cache_t 的工作流程
当前查找的 IMP 没有被缓存,调用 reallocate 方法进行创建-分配内存,然后使用 bucket 的 set 方法进行填充缓存。
当前查找的 IMP 已经被缓存了,然后判断缓存容量是否已经达到 3/4 的临界点。
如果已经到了临界点,则需要进行扩容,扩容大小为原来缓存大小的 2 倍。扩容后处于效率的考虑,会清空之前的内容,然后把当前要查找的 IMP 通过 bucket 的 set 方法缓存起来。
如果没有到临界点,那么直接进行缓存。
```

若有收获,就点个赞吧
0 人点赞
