一、 前言
课题内容:10G的数字大文件,只有4G内存,如何排序?
- 创造一个数字大文件,先不创建10G,可以写入10万个数做测试,只有800KB左右!
- 对文件进行排序
参考博客:
首先想到归并排序,归并排序是典型的分治算法,它不断地将某个数组分为两个部分,分别对左子数组与右子数组进行排序,然后将两个数组合并为新的有序数组。
一般来说,小文件单机版排序比并发排序更快一些,但是大文件无法一次性读入内存处理,需要分块处理。单机版排序无法做到分布式排序,分布式排序需要联网进行,网络传输跟通道传输非常类似,稍作修改就可以做到在网络上进行排序。
也就是说,大文件做并发更快!
并行和并发是有区别的,依赖操作系统和硬件是否支持。同时,在允许的情况下,使用有缓冲的通道和使用文件读写缓冲,有利于加快程序的处理速度,避免及时阻塞。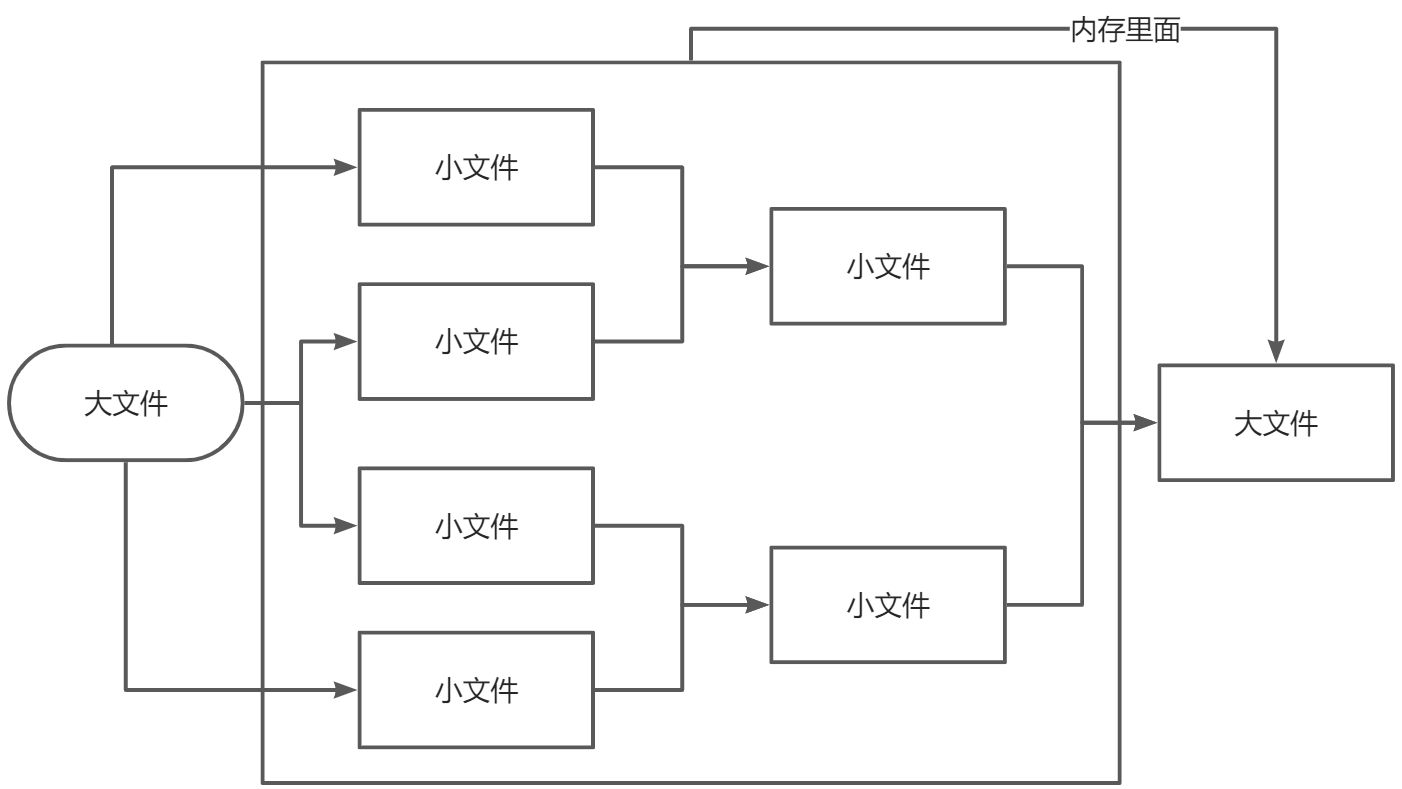
二、 测试排序是否可执行
1. 往通道写入可变参数的整数ArrSort
package arraySort// 往通道写入可变参数的整数func ArrSort(a ...int) <-chan int {out := make(chan int)go func() {for _, v := range a {out <- v}close(out)}()return out}
2. 按升序排序InMemSort
对一个整数数组进行排序,系统库中已经提供了排序函数(这个也可以自己写),直接使用即可。
需要注意的是,Go中使用通道,使用不当会造成死锁。需要注意通道的使用,否则一运行就发生竞争条件造成程序无法执行而终止。
通道使用注意事项详解(这块找找资料附链接)
参考:通道用例大全(go语言白皮书)
通常来说,协程的使用是成对出现的,并且习惯用Go匿名函数来操作。需要留意匿名函数的传参问题,可以去官方文档进行查看(这块找找资料附:链接)。go程运行时,函数调用是瞬间返回的。如果在其它地方使用range操作来处理通道,在通道数据发送完毕时必须显示关闭通道,否则必是死锁错误。
package arraySort/*数组排序对一个整数数组进行排序,系统库中已经提供了排序函数,直接使用即可。需要注意的是,Go中使用通道,使用不当会造成死锁。需要注意通道的使用,否则一运行就发生竞争条件造成程序无法执行而终止。通常来说,协程的使用是成对出现的,并且习惯用Go匿名函数来操作。需要留意匿名函数的传参问题,可以去官方文档进行查看。go程运行时,函数调用是瞬间返回的。如果在其它地方使用range操作来处理通道,在通道数据发送完毕时必须显示关闭通道,否则必是死锁错误。*/import (// "fmt""sort"// "time")// var startTime time.Time// func init() {// startTime = time.Now()// }// 按升序排序func InMemSort(in <-chan int) <-chan int {out := make(chan int, 4096)// 启动一个协程输出排序数据go func() {var a []intfor v := range in {a = append(a, v)}// fmt.Println("Read done: ", time.Now().Sub(startTime))sort.Ints(a)// fmt.Println("Sort done: ", time.Now().Sub(startTime))// 将排序好的数据输出至通道中for _, n := range a {out <- n}close(out)}()return out}
3. 合并两个有序数组Merge
归并排序是分别进行的,每一块排序完成后,需要等待另外的块排序完毕后,才可继续进行。通道能很方便的做到这个操作,每一个读通道都是阻塞的,在未读取到数据之前,始终等待。
合并两个有序数组时,也要遵循一定的顺序合并,最终的数据才是有顺序的。这块是程序执行最难的一处,无法并行排序,只能一次合并有序数组。
package arraySort/*合并两个有序数组归并排序是分别进行的,每一块排序完成后,需要等待另外的块排序完毕后,才可继续进行。通道能很方便的做到这个操作,每一个读通道都是阻塞的,在未读取到数据之前,始终等待。合并两个有序数组时,也要遵循一定的顺序合并,最终的数据才是有顺序的。这块是程序执行最难的一处,无法并行排序,只能一次合并有序数组。*/import (// "fmt"// "time")// 按升序合并两个通道中数据func Merge(in1, in2 <-chan int) <-chan int {out := make(chan int, 4096)go func() {v1, ok1 := <-in1v2, ok2 := <-in2for ok1 || ok2 {if !ok2 || (ok1 && v1 <= v2) {out <- v1v1, ok1 = <-in1} else {out <- v2v2, ok2 = <-in2}}close(out)// fmt.Println("Merge done: ", time.Now().Sub(startTime))}()return out}
4. 主函数
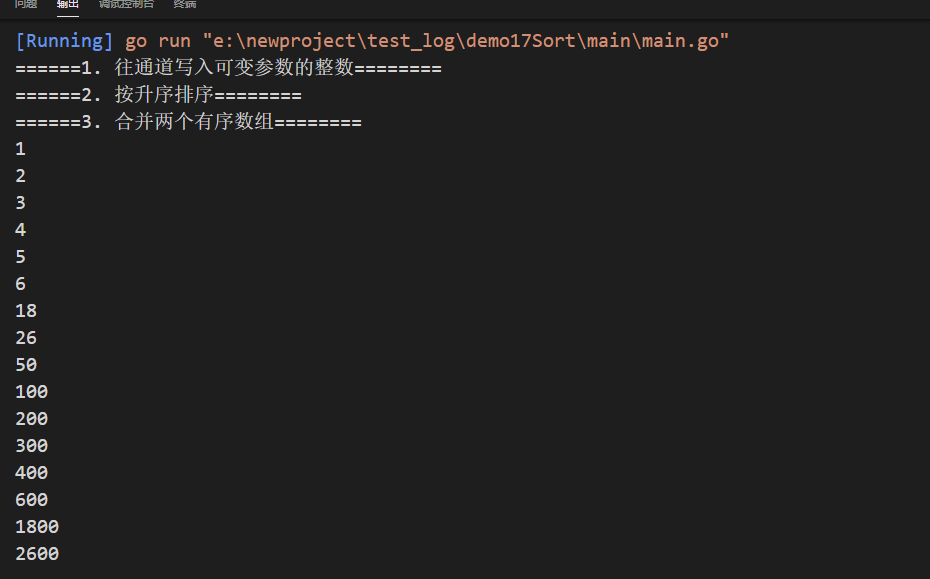
func sortLogin() {fmt.Println("======1. 往通道写入可变参数的整数========")ch1 := arraySort.ArrSort(1, 4, 6, 2, 18, 3, 26, 5) //<-chan intch2 := arraySort.ArrSort(100, 400, 600, 200, 1800, 300, 2600, 50)fmt.Println("======2. 按升序排序========")fmt.Println("======3. 合并两个有序数组========")p := arraySort.Merge(arraySort.InMemSort(ch1), arraySort.InMemSort(ch2))for m := range p {fmt.Println(m)}}
三 、 生成随机数文件
1. 生成指定数量的随机整数RandomSource
生成指定大小的随机整数数据来测试用。
生成简单整数即可。
package arraySort/*生成样本数据生成指定大小的随机整数数据来测试用。生成简单整数即可。*/import (// "crypto/rand""math/rand")// 生成指定数量的随机整数func RandomSource(count int) <-chan int {out := make(chan int)go func() {for i := 0; i < count; i++ {out <- rand.Int()}close(out)}()return out}/*rand.Seed(time.Now().UnixNano()) // 设置种子数为当前时间var src [100]intfmt.Println("=====生成随机数组====")for i := 0; i < 100; i++ {src[i] = rand.Intn(100)}*/
2. 用缓冲的方式将数据写入文件WriteSink
写文件基本都类似,也是按二进制方式写入数据到文件。
该处写文件不需要另起协程,当然也可以起协程,效果不明显。
package arraySort/*写数据到文件写文件基本都类似,也是按二进制方式写入数据到文件。该处写文件不需要另起协程,当然也可以起协程,效果不明显。*/import ("encoding/binary""io")// 向可写输入写入数据func WriteSink(writer io.Writer, in <-chan int) {for m := range in {buffer := make([]byte, 8)binary.BigEndian.PutUint64(buffer, uint64(m))writer.Write(buffer)}}
3. 用缓冲的方式读取文件ReadSource
Go习惯用法是接口类型,即可读数据源均可,包括文件,网络,甚至各种输入类型,而不是简单的FileSource形式,而是更广泛意义上的可读源。
以二进制的方式读数据,同时使用有缓冲的读操作,加快文件读取速度。如果尺寸为-1时完全一次性读取文件,否则读取指定大小的文件。文件读取有一个偏移量,默认从偏移量处开始往后读取到指定的尺寸。
package arraySort/*从源读取数据Go习惯用法是接口类型,即可读数据源均可,包括文件,网络,甚至各种输入类型,而不是简单的FileSource形式,而是更广泛意义上的可读源。以二进制的方式读数据,同时使用有缓冲的读操作,加快文件读取速度。如果尺寸为-1时完全一次性读取文件,否则读取指定大小的文件。文件读取有一个偏移量,默认从偏移量处开始往后读取到指定的尺寸。*/import ("encoding/binary""io")// 从可读位置读入数据// 读入指定长度的数据, 为-1时一次性全部读完func ReadSource(reader io.Reader, chunkSize int) <-chan int {out := make(chan int, 4096)go func() {buffer := make([]byte, 8)size := 0for {n, err := reader.Read(buffer)size += nif n > 0 {v := int(binary.BigEndian.Uint64(buffer))// var v intout <- v}if err != nil || (chunkSize != -1 && size >= chunkSize) {break}}close(out)}()return out}package arraySortimport ("encoding/binary""io")//从可读位置读入数据,如果剩下的不能占用一次的读取大小就全部读完即chunkSize = -1func ReadSource(reader io.Reader, chunkSize int) <-chan int {out := make(chan int, 4096)go func() {buffer := make([]byte, 8)size := 0for {n, err := reader.Read(buffer)size += nif n > 0 {v := int(binary.BigEndian.Uint64(buffer))out <- v}if err != nil || (chunkSize != -1 && size >= chunkSize) {break}}close(out)}()return out}
4. 主函数
func readFile() {fmt.Println("======4. 生成指定数量的随机整数========")random := arraySort.RandomSource(num)fmt.Println("======5. 用缓冲的方式将数据写入文件========")fileWrite, errWrite := os.Create(fileInPath)if errWrite != nil {panic(errWrite)}defer fileWrite.Close()// 使用缓冲方式写数据,使用缓冲比不适用缓冲快了好几倍writer := bufio.NewWriter(fileWrite)// for m := range random {// fmt.Println(m)// writer.WriteString(strconv.Itoa(m)+"\n")// }arraySort.WriteSink(writer, random)// 最后数据可能不能写缓冲, 需要强制刷新缓冲writer.Flush()fmt.Println("======6.用缓冲的方式读数据========")fileRead, errRead := os.Open(fileInPath)if errRead != nil {panic(errRead)}defer fileRead.Close()// reader := bufio.NewReader(file)// //循环读取文件内容// for {// //读到一个换行就结束// line, err := reader.ReadString('\n') //注意是字符// // 代表文件末尾 err!= nil// if err == io.EOF {// if len(line) != 0 {// fmt.Println(line)// }// fmt.Println("文件读完了")// break// }// if err != nil {// fmt.Println("read file failed, err:", err)// return// }// fmt.Print(line)// }// 使用有缓冲方式读数据reader := arraySort.ReadSource(bufio.NewReader(fileRead), -1)n := 0for m := range reader {fmt.Println(m)n++// 只输出前10个二进制数字if n >= 10 {break}}}
测试输出,只输出前10个二进制数字,可以看到是乱序的!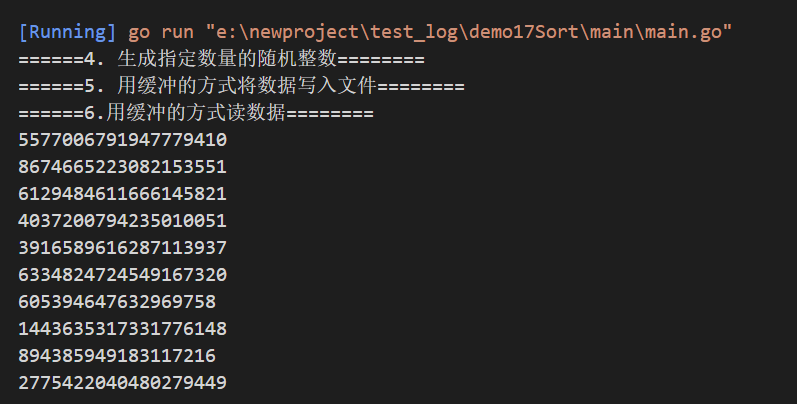
四、 排序
1. 分片读取文件内容Create
分片的实现,其实就是指定一次性读取多大文件内容而已。实现方式很多,一般就是读取等大小的块,该处需要注意的是,文件的完整性,如果读取的内容是不完整,或者被错误分隔的,将造成数据的不完整或错误。
该处实现文件切片并归并排序,也是最主要的外部排序实现方式。注意文件偏移量的概念和读方式。
package arraySort/*分片读取文件内容分片的实现,其实就是指定一次性读取多大文件内容而已。实现方式很多,一般就是读取等大小的块,该处需要注意的是,文件的完整性,如果读取的内容是不完整,或者被错误分隔的,将造成数据的不完整或错误。该处实现文件切片并归并排序,也是最主要的外部排序实现方式。注意文件偏移量的概念和读方式。*/import ("bufio""os"// "fmt")// 可读入资源切片func Create(fileName string, fileSize, count int) <-chan int {chunkSize := fileSize / countvar result []<-chan intfor i := 0; i < count; i++ {file, err := os.Open(fileName)if err != nil {panic(err)}// 设置文件偏移量, 并从偏移量开始0处读取文件内容file.Seek(int64(i*chunkSize), 0)p := ReadSource(bufio.NewReader(file), chunkSize)//按升序排序result = append(result, InMemSort(p))}//递归进行两两归并return MergeN(result...)}
这里注意有一个递归排序的过程!MergeN
可变通道的递归合并,一般也是按中点切分,区间内进行递归合并。
如果只有一个通道时不需要递归,直接退出即可。需要注意的是,递归合并始终传递可变通道类型。
package arraySort/*递归合并数组可变通道的递归合并,一般也是按中点切分,区间内进行递归合并。如果只有一个通道时不需要递归,直接退出即可。需要注意的是,递归合并始终传递可变通道类型。*/// 递归进行两两归并func MergeN(ins ...<-chan int) <-chan int {// 只有一个通道时直接返回if len(ins) == 1 {return ins[0]}// 取中点m := len(ins) / 2// 递归归并return Merge(MergeN(ins[:m]...), MergeN(ins[m:]...))}
2. 将排序数据写入文件Write
排序完成后将数据写入结果文件中,便于后续直接处理有序的文件内容。
缓冲写数据需要注意,可能缓冲区未满,文件就写结束,需要强制刷新缓冲区,避免丢失未来得及写入的部分数据。
package arraySort/*将排序数据写入文件排序完成后将数据写入结果文件中,便于后续直接处理有序的文件内容。缓冲写数据需要注意,可能缓冲区未满,文件就写结束,需要强制刷新缓冲区,避免丢失未来得及写入的部分数据。*/import ("bufio"// "fmt""os"// "strconv")// 将排序好的数据写入文件中func Write(in <-chan int, fileName string) {file, err := os.Create(fileName)if err != nil {panic(err)}defer file.Close()w := bufio.NewWriter(file)defer w.Flush()WriteSink(w, in)// writer := bufio.NewWriter(file)// for m := range in {// fmt.Println(m)// writer.WriteString(strconv.Itoa(m)+"\n")// }// // arraySort.WriteSink(writer, random)// // 最后数据可能不能写缓冲, 需要强制刷新缓冲// defer writer.Flush()}
这里注意有一个写数据到文件的过程WriteSink
写文件基本都类似,也是按二进制方式写入数据到文件。
该处写文件不需要另起协程,当然也可以起协程,效果不明显。
package arraySort/*写数据到文件写文件基本都类似,也是按二进制方式写入数据到文件。该处写文件不需要另起协程,当然也可以起协程,效果不明显。*/import ("encoding/binary""io")// 向可写输入写入数据func WriteSink(writer io.Writer, in <-chan int) {for m := range in {buffer := make([]byte, 8)binary.BigEndian.PutUint64(buffer, uint64(m))writer.Write(buffer)}}
3. 打印排序结果
文件过大时全部数据可能无法输出,内存不够,故只输出一部分数据即可。
package arraySort/*打印排序结果文件过大时全部数据可能无法输出,内存不够,故只输出一部分数据即可。排序一个800M的整数数据,文件分4块,可以看到读取,内部排序都比较快,比较慢的部分是归并部分,归并部分需要每个数据进行比较,故速度会稍微慢一些。*/import ("fmt""os")// 输出文件内容func Echo(fileName string) {file, err := os.Open(fileName)if err != nil {panic(err)}defer file.Close()p := ReadSource(file, -1)n := 0for m := range p {fmt.Println(m)n++if n >= 10 {break}}}
4. 主函数
func MergerSort() {fmt.Println("======7. 分片读取文件内容========")fileContent := arraySort.Create(fileInPath, 800, 4)// for m := range fileContent {// fmt.Println(m)// }fmt.Println("======8. 将排序数据写入文件========")arraySort.Write(fileContent, fileOutPath)fmt.Println("======9. 输出文件内容========")arraySort.Echo(fileOutPath)}
排序一个800M的整数数据,文件分4块,可以看到读取,内部排序都比较快,比较慢的部分是归并部分,归并部分需要每个数据进行比较,故速度会稍微慢一些。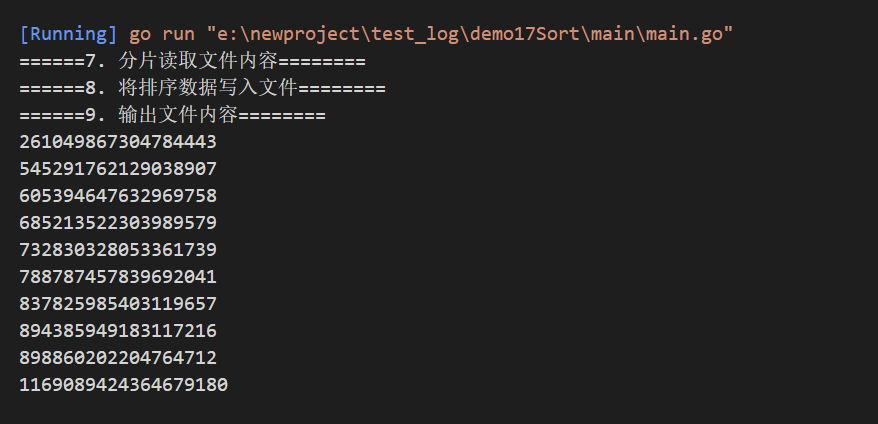
打印10个数测试一下!可以看到已经排序!

若有收获,就点个赞吧
0 人点赞
