本文档是对课程内容的简单整理。
- 前缀Z_ 为正课视频的简称,如Z1为正课视频第1课
- 前缀G_ 为更新视频的简称,如G1为更新视频第1课
分类是已知类别的,聚类未知。
- 聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;
- 也可以探究不同类之间的相关性和主要差异。
聚类需要统一量纲
K-means K-means++聚类
文章
2019D
D19105320030.pdf
(D19100010050.pdf)
SPSS
SPSS操作 需要统一量纲
SPSS操作 见Z10文档 D:\00000MCM\清风\0 课件和代码\正课配套的课件和代码\第10讲.聚类模型
Python
Python 见D:\00000py\1\mcm 2019d_q3_0030_PCAKmeans.py
from sklearn.decomposition import PCAfrom sklearn.cluster import KMeansimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport numpy as npimport pandas as pdimport copyimport datetimepaths = './datasets/2019d/'data1 = pd.read_excel(paths + 'feature1_forq3.xlsx', header=None) #文件 1 特征参数数据data1 = pd.DataFrame(data1)data1 = np.array(data1)data0 = pd.read_excel(paths + 'data1_small_outforq2.xlsx', header=None) #文件 1汽车运行数据data0 = pd.DataFrame(data0)data0 = np.array(data0)sport = pd.read_excel(paths + 'sport1_forq3.xlsx', header=None) # 文件 1 运动学片段sport = pd.DataFrame(sport)sport = np.array(sport)sport = sport - np.array([[1, 1, 0]] * sport.shape[0])# 合并数据 转换数据data = data1.tolist()data = np.array(data) # (200, 15) 200行数据 15特征#PCA 3 个主成分pca_d = PCA(n_components=3) #选择 3 个主成分data_new = pca_d.fit_transform(data) # (200, 3) 200行数据 3主成分clust = KMeans(n_clusters=3) #构造聚类,分 3 类clust.fit(data_new) #聚类label_p = clust.labels_ #获取聚类标签 (200, ) 200行数据 1标签 范围 0 1 2la1 = data_new[label_p == 0] # (170, 3)la2 = data_new[label_p == 1] # (24, 3)la3 = data_new[label_p == 2] # (6, 3)x1=[]y1=[]z1=[]x2=[]y2=[]z2=[]x3=[]y3=[]z3=[]for i in range(la1.shape[0]): # 三位空间分布x1.append(la1[i][0])y1.append(la1[i][1])z1.append(la1[i][2])for i in range(la2.shape[0]):x2.append(la2[i][0])y2.append(la2[i][1])z2.append(la2[i][2])for i in range(la3.shape[0]):x3.append(la3[i][0])y3.append(la3[i][1])z3.append(la3[i][2])fig = plt.figure()ax = fig.add_subplot(111, projection='3d')ax.scatter(x1,y1,z1,c='b')ax.scatter(x2,y2,z2,c='r')ax.scatter(x3,y3,z3,c='k')plt.show()
系统(层次)聚类
SPSS
SPSS操作 树状图 聚合系数折线图(用于确定聚类K值) 画出分类结果示意图
DBSCAN算法(密度的聚类方法)
能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据。
Matlab
D:\00000MCM\清风\0 课件和代码\正课配套的课件和代码\第10讲.聚类模型\代码和例题数据\DBSCAN Clustering
聚类算法对比
2018C 1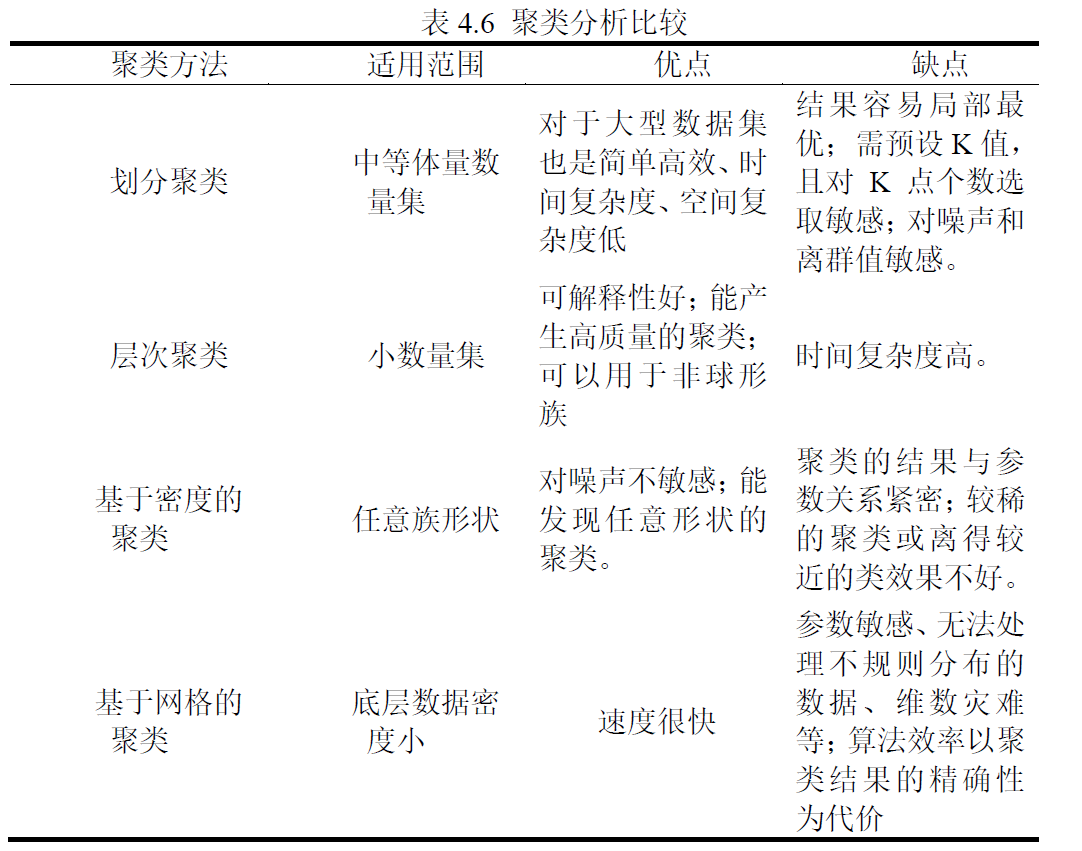

若有收获,就点个赞吧
0 人点赞
