非常重要的、基础性的、一定程度上决定性的任务。
参考资料
数学建模冲刺篇(数据预处理)_沉晨尘宸的博客-CSDN博客(参考)
数学建模-数据预处理 - 道客巴巴
数据预处理 第2篇:数据预处理(缺失值)_悦光阴的博客-CSDN博客
数学建模 数据预处理UESTC Like-CSDN博客数学建模数据预处理
处理流程
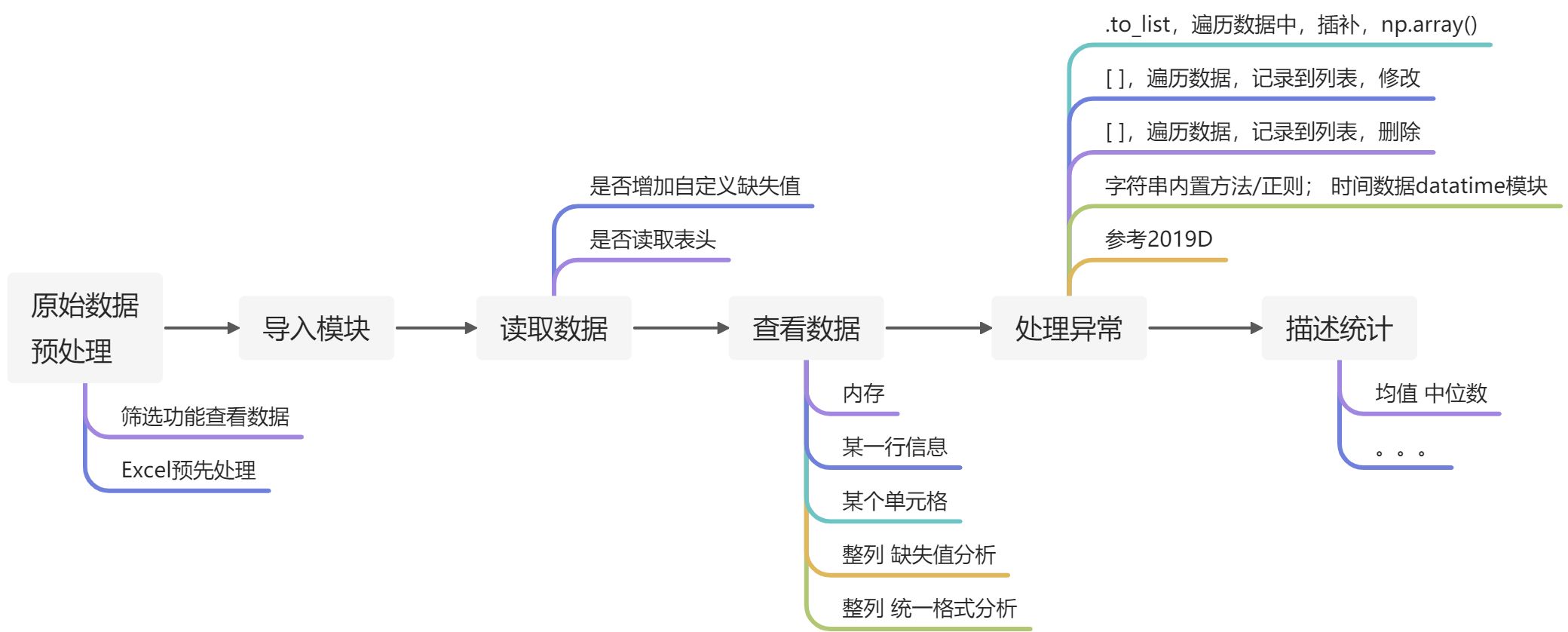
文件关系 Python程序
(花了不少时间才归纳出的处理流程ヽ(≧∀≦)ノ)
Python
Pandas数据清洗及基本处理_ITmincherry的博客-CSDN博客
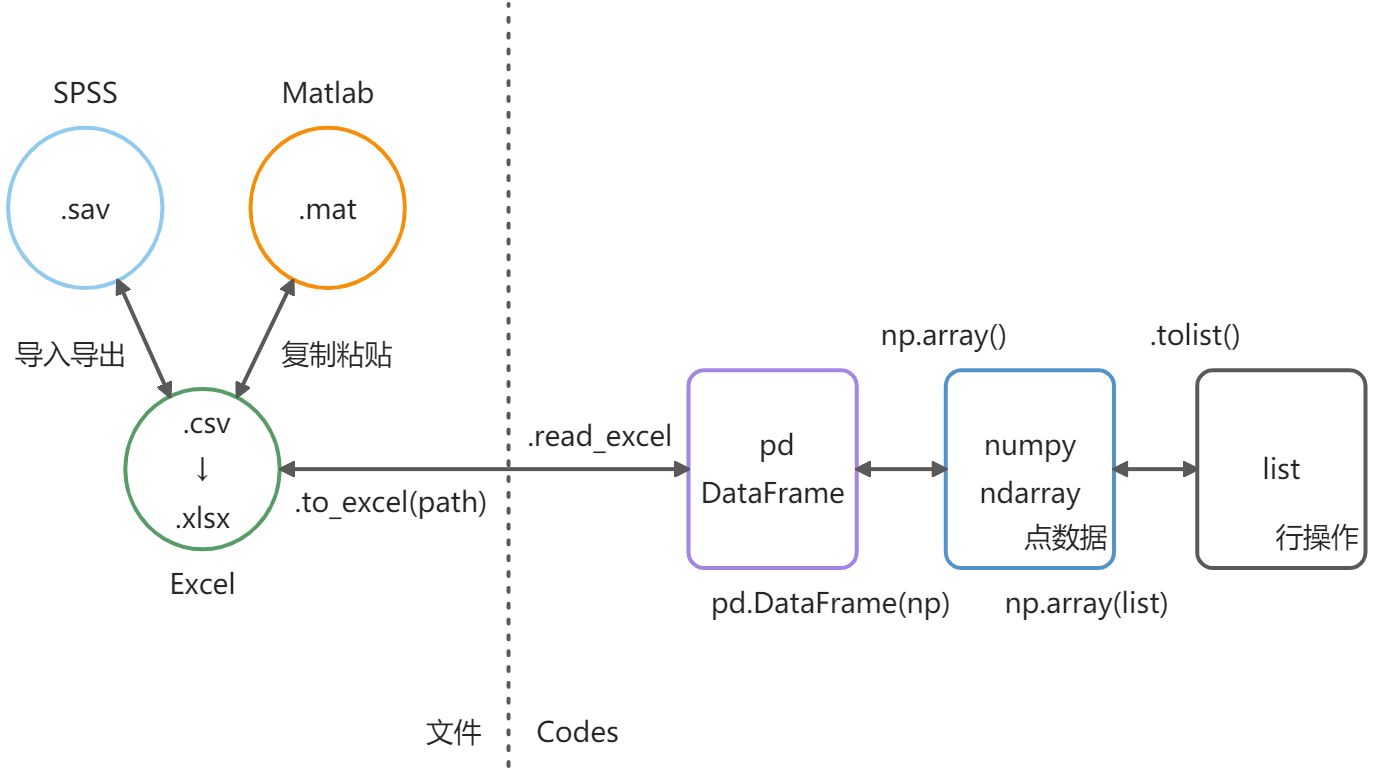
Pandas 读取保存Execl->DataFrame->ndarray->list
datetime 时间处理
Pandas
读取细节:
- 注意是否读取第一行作为表头 ,header=None
- 不得出现空白列,会被读取为Unnamed:xx
- 自动处理重复列名称(尽可能不要重复)
缺失值处理:
- NA NaN nan N/A n/a 空值:为缺失值 nan
- na NAN nAn N/a n/A:为字符串,不是缺失值,需要增加指定格式为缺失值 见菜鸟教程
SciView查看数据时,鼠标点击一个具体单元格,防止颜色错误
pandas用法总结_yiyele的博客-CSDN博客_pandas用法
Pandas入门详细教程_Python数据之道-CSDN博客
Python pandas用法 - 简书
Python+Pandas读取excel一列或者多列保存为列表_liuzh的博客-CSDN博客_python读取excel指定列
python+pandas 保存list到本地excel_liuzh的博客-CSDN博客_python将list写入excel
判断是否为缺失值nan
pd.isnull(cell1)
对pandas数据判断是否为NaN值的方法详解python脚本之家
pandas 里面对nan的判断 - 清源居士 - 博客园
Python类型判断
isinstance(a, int)
python如何判断数据类型 - 知乎
pandas中查看数据类型的几种方式 - 简书
删除数据
Pandas常用操作 - 删除指定行/指定列 - Convict - 博客园
datatime模块
参考2019D 读写为不同函数
python datetime中strptime用法详解python脚本之家
python时间处理,datetime中的strftime/strptime - 桑卡 - 博客园(参考)
描述统计 异常值
pandas异常值的处理_Python教程网
箱线图(Boxplot)_J小白的博客-CSDN博客(参考)
【Python】实现箱线图异常值检测_J小白的博客-CSDN博客(参考)
Pandas进行异常值分析—describe()查看数据基本情况、箱线图查看异常值分布_zm_1900的博客-CSDN博客
填充缺失值
pandas 缺失值处理,插值 - emanlee - 博客园
机器学习pandas之缺失值的处理方法_坤坤子的世界的博客-CSDN博客
excel_pd_numpy_list.py
import numpy as npimport pandas as pdimport datetimeimport copypaths = './datasets/'# 读取数据 (DataFrame ...) 备用方法xlrddata1 = pd.read_excel(r'D:\00000py\1\datasets\pdtest.xlsx')data1_noheader = pd.read_excel(r'D:\00000py\1\datasets\pdtest.xlsx', header=None) # 不读取第一行作为表头# DataFrame->DataFrame->ndarray->listdata1_pd = pd.DataFrame(data1) # DataFrame->DataFramedata1_np = np.array(data1_pd) # DataFrame->ndarraydata1_list = data1_np.tolist() # ndarray->list# 数据处理data1_np_copy = copy.deepcopy(data1_np) # 深拷贝数据 针对numpydata1_title = data1_pd.columns.to_list() # 列标题listtime1 = datetime.datetime.strptime(data1_np[0][0].replace('.000.', ''), '%Y/%m/%d %H:%M:%S') # 获取格式化的时间time2 = datetime.datetime.strptime(data1_np[1][0].replace('.000.', ''), '%Y/%m/%d %H:%M:%S')delta = (time2 - time1).seconds # 时间间隔 秒print(time1)print(time2)print(delta)# list->ndarray(转置)->DataFramer_data1_np = np.array(data1_list) # list->ndarrayr_data1_pd = pd.DataFrame(data1_np) # ndarray->DataFramer_data1_pd_t = pd.DataFrame(data1_np.T) # ndarray转置->DataFrame# 转为DataFrame 保存数据r_data1_pd.columns = data1_title # 写表头(可选)r_data1_pd.to_excel(paths + 'save_test.xlsx')print()print('finish')# #读取数据备用方法# data = xlrd.open_workbook(r'D:\00000MCM\0 codes\2020B\q3.xlsx') # datas q2xxhg# # 转为ndarray# table = data.sheet_by_index(0) #按索引获取工作表,0就是工作表1# resArray = []# for i in range(1, table.nrows): #table.nrows表示总行数 去除第一行# line=table.row_values(i) #读取每行数据,保存在line里面,line是list# resArray.append(line) #将line加入到resArray中,resArray是二维list# resArray=np.array(resArray) #将resArray从二维list变成数组
正则化处理数据上限下限 2020B1
GitHub - cdoco/learn-regex-zh: 翻译: 学习正则表达式的简单方法
语雀 https://www.yuque.com/pumpkinlin/qgskax/xgx1t7#iaai1
Python3 正则表达式 | 菜鸟教程
正则表达式 – 教程 | 菜鸟教程
在线测试正则表达式 regex101: build, test, and debug regex
sffFf2017/12/18 13:42:13.000.2017/12/18 13:42:13.000. 2017/12/18 13:42:13.000. 2017/12/18 13:42:13.000.fun2017/12/18 13:42:13.000. 2017/12/18 13:42:13.000. 2017/12/18 13:42:13.000.val valval valvalval agwfa awgawg aavalvalvalvalvalval<h1><h1><h2><h1><h2><h3>RegExr was created by gskinner.com, and is proudly hosted by Media Temple.Edit the Expression & Text to see matches. Roll over matches or the expression for details. PCRE & JavaScript flavors of RegEx are supported. Validate your expression with Tests mode.The side bar includes a Cheatsheet, full Reference, and Help. You can also Save & Share with the Community, and view patterns you create or favorite in My Patterns.Explore results with the Tools below. Replace & List output custom results. Details lists capture groups. Explain describes your expression in plain English.^[0-9a-zA-Z]{5}$[aeiou] 区域内任意字符[^aeiou] 除了区域内任意字符(val){2} 不限位置^(val){2}$ 限定位置(独立位置)^[0-9]{4}/[0-9]{2}/[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2} 时间2017/12/18 13:42:13<.+> 贪婪模式<.+?> 非贪婪模式
删除字符串中不需要的内容:
- 字符串操作 .replace()
- 正则表达式
注意贪婪模式:通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从”贪婪”表达式转换为”非贪婪”表达式或者最小匹配。
分段匹配 2019D 见下
D:\00000py\1\mcm 正则化匹配数字范围.py
import re# re.match 从起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。# re.search 扫描整个字符串并返回第一个成功的匹配。(匹配到一次就返回)str0 = r'13-15'str1 = r'-13-14'str2 = r'-13-(14)'str3 = r'-13-(-14)'str4 = r'-13-(-14)'lists = [str0, str1, str2, str3, str4]for i in range(5):print('str' + str(i) + ' ' + lists[i] + ': ', end='')# result = re.match('-?\d+-\(?\(?-?\d+\)?\)?', lists[i])# all = result.group()# print(all, end=' ')min = re.match('-?\d+-', lists[i]).group()[:-1] # [:-1]用于删除-print(min, end=' ')maxstr = len(min) + 1 # 设置起点 不匹配之前的数据# print(lists[i][maxstr:], end=' ')max = re.search('-?\d+', lists[i][maxstr:]).group()print(max)
Matlab Excel SPSS操作
见 Z5课件
D:\00000MCM\清风\0 课件和代码\正课配套的课件和代码\第5讲.相关系数
SPSS
对照变量注释剔除变量 修改标度or名义
缺失值分析
- SPSS 分析-缺失值分析 (数据过大导致内存不足 无法使用)
SPSS案例:快速统计样本缺失-CDA数据分析师官网
SPSS缺失值分析 - 百度文库
- SPSS导出excel文件,标度变量缺失值为#NULL!,Excel 使用countif函数统计个数(注意F4固定单元格)
如何在Excel中统计某一列中的指定值的数量-百度经验
Excel中的if语句 =IF(A114187>=90,”cut”,)
不等于号 <>
缺失值填充
- SPSS 转换 - 重新编码为相同变量
- Excel处理
- Python处理
Python操作模板
D:\00000py\1\mcm pre_preprocessing.ipynb
#%% 导入模块import osimport numpy as npimport pandas as pdimport datetimeimport copyimport xlrdprint('导入模块完成')#%% 加载原始数据data_path = r'D:/00000MCM/0 codes/pre_preprocessing/'file_name = r'property-data-PL.xlsx'# missing_values = ["na", "--"] # read_excel读取时 增加指定格式为缺失值 na_values=missing_values# 默认缺失值格式: NA NaN nan N/A n/a 空值data_ori = pd.read_excel(data_path + file_name) # header=None读取无标题行文件 na_values=missing_values 增加自定义缺失值# data_ori = pd.read_excel(data_path + file_name, na_values=missing_values) # header=None读取无标题行文件 na_values=missing_values 增加自定义缺失值data_pd = pd.DataFrame(data_ori) # 原始数据->DataFrame (可能无需这个步骤 原始数据为DataFrame)data_title = data_pd.columns.to_list() # 获取列标题(list)data_np = np.array(data_pd) # DataFrame->ndarraydata_np_copy = copy.deepcopy(data_np) #原始数据副本(记录处理后最终数据)# data_list = data_np.tolist() # ndarray->listprint('数据加载完成')#%% 查看数据# 查看内存地址# 查看第一行数据及类型(非列类型,仅代表本行数据)# 查看单个单元格# 缺失值分析(读取时可增值缺失值格式)# 查看数值列是否存在异常(数据格式不统一)# 原始数据形状print('\n原始数据形状')hang, lie = data_pd.shapeprint('行: ' + str(hang))print('列: ' + str(lie))# 查看内存地址print('\n查看内存地址')print(id(data_ori))print(id(data_pd))print(id(data_np))print(id(data_np_copy))# 查看第一行数据及类型(非列类型,仅代表本行数据)print('\n查看第一行数据及类型(非列类型,仅代表本行数据)')hang1 = data_np[1] # 第一行数据输出print(hang1)for i in range(len(hang1)):if True: # 存在标题print(data_title[i], end=' ')print(hang1[i], end=' ')print(type(hang1[i]))# 查看单个单元格print('\n查看单个单元格:值 类型 是否为缺失值 是否为指定类型')cell1 = data_pd.loc[3, 'x2']print(cell1)print(type(cell1))print(pd.isnull(cell1))print(isinstance(cell1, float))# 缺失值分析(读取时可增值缺失值格式)print('\n缺失值分析(读取时可增值缺失值格式):是否含有 数量 比例')# 判断各变量中是否存在缺失值missing_if = data_pd.isnull().any(axis = 0)# 各变量中缺失值的数量missing_num = data_pd.isnull().sum(axis = 0)# 各变量中缺失值的比例missing_rate = data_pd.isnull().sum(axis = 0)/data_pd.shape[0]# 输出结果for i in range(lie):if True: # 存在标题print(data_title[i], end=' ')print(missing_if.iloc[i], end=' ')print(missing_num.iloc[i], end=' ')print(missing_rate.iloc[i])# 查看数值列是否存在异常(数据格式不统一)print('\n查看数值列是否存在异常(数据格式不统一)')# 数值列除了缺失值 其他数据类型统一 否则为objectfor i in range(lie):if True: # 存在标题print(data_title[i], end=' ')print(data_pd.iloc[:, i].dtype)print('\n查看数据 统计描述完成')#%% 数据预处理# 原始数据形状print('\n原始数据形状')hang, lie = data_pd.shapeprint('行: ' + str(hang))print('列: ' + str(lie))# 删除异常值操作# 替换异常值操作# 转为list 插入数据#%% 统计描述(需要先去除异常数据)# 仅能计算类型统一的数值列data_mean = data_pd.mean() # 均值data_median = data_pd.median() # 中位数# 。。。#%% 后修处理#%% 保存数据

若有收获,就点个赞吧
0 人点赞
