- 1 什么是长尾问题?
- 2 场景图生成中的长尾问题
- 3 方法分类
- Neural Motifs: Scene Graph Parsing with Global Context
- KERN: Knowledge-Embedded Routing Network for Scene Graph Generation
- Visual Relationships as Functions: Enabling Few-Shot Scene Graph Prediction
- VCTree: Learning to Compose Dynamic Tree Structures for Visual Contexts
参考 长尾分布下的图片分类问题 - https://zhuanlan.zhihu.com/p/153483585
1 什么是长尾问题?
长尾问题,也叫做偏差(bias),该问题的讨论在机器学习中已经研究很久了(如[2011 CVPR]Unbiased look at dataset bias)。在传统的分类和识别任务中,训练数据的分布往往都受到了人工的均衡,即不同类别的样本数量无明显差异。举个简单的例子,如果要做一个动物分类数据集,猫狗等常见数据可以轻轻松松的采集数以百万张的图片,但是考虑到数据集的均衡,我们必须也给雪豹等罕见动物采集等量的样本,而随着类别稀有度的增加,其采集成本往往成指数增长。
那么如果我们完全不考虑人工均衡,自然的采集所有相关数据呢?这样的数据就是本文所关注的长尾数据。在自然情况下,数据往往都会呈现如图1的长尾分布(Long-Tailed Distribution)。这种趋势同样出现在从自然科学到社会科学的各个领域各个问题中,参考Zipf’s Law或者我们常说的28定律。
图1 长尾分布
直接利用长尾数据来训练的分类和识别系统,往往会对头部数据过拟合,从而在预测时忽略尾部的类别。如何有效的利用不均衡的长尾数据,来训练出均衡的分类器就是我们所关心的问题,从工业需求上来说,该研究也将大大地提升数据采集的速度并显著降低采集成本。
长尾效应主要体现在有监督学习里,无监督/自监督学习等因为不依赖标注,所以长尾效应体现的不明显,目前也缺少这方面的研究(但并不代表无监督/自监督学习不受长尾效应的影响,因为图片本身也有分布,常见的图案和罕见的图案也会形成这样的长尾效应,从而使模型对常见的图案更敏感)。
目前,长尾问题主要出现在计算机视觉领域,并且也是一大热门研究方向。可以从图2看到近年Long-Tailed Recognition的论文总结。
图2 Long-Tailed Recognition论文总结,来自Awesome-of-Long-Tailed-Recognition
2 场景图生成中的长尾问题
2.1 数据集长尾分布
场景图生成任务常用的数据集长尾分布问题比较严重。如图3,最常用的Visual Genome数据集,其中92%的关系不超过10个实例,同时,大多数使用它进行训练的场景图生成模型只关注具有数千个样本的前50个关系类别,而忽略了几乎98%的只有有限样本的关系类别。针对长尾问题的工作,也可说是为了更有效地预测出那些“尾部”关系类别。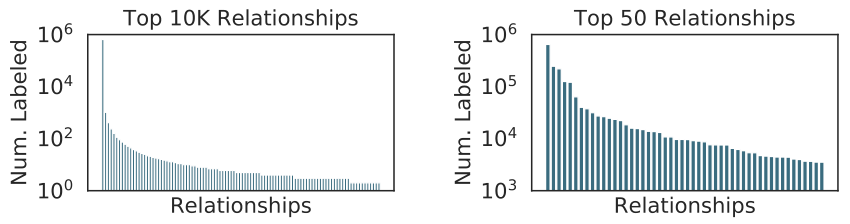
图3 Visual Genome有一个很长的尾巴
2.2 评价指标
在SGG任务中,不仅仅存在数据集长尾分布的问题,其评价指标Recall@K也存在一定问题。之前的SGG模型,过度依赖单一指标Recall@K,而这个指标因为不区分各个类别的贡献加上Visual Genome本身的长尾效应,即便模型只学出了on/near/wear/has等少数几种relationship,模型的Recall@K依然非常高。这导致了近年大多数SGG的文章,只是在过拟合的道路上越走越远,而非真正生成了更有意义的场景图。
3 方法分类
有七篇论文(方法)涉及场景图生成中的长尾问题,如下图。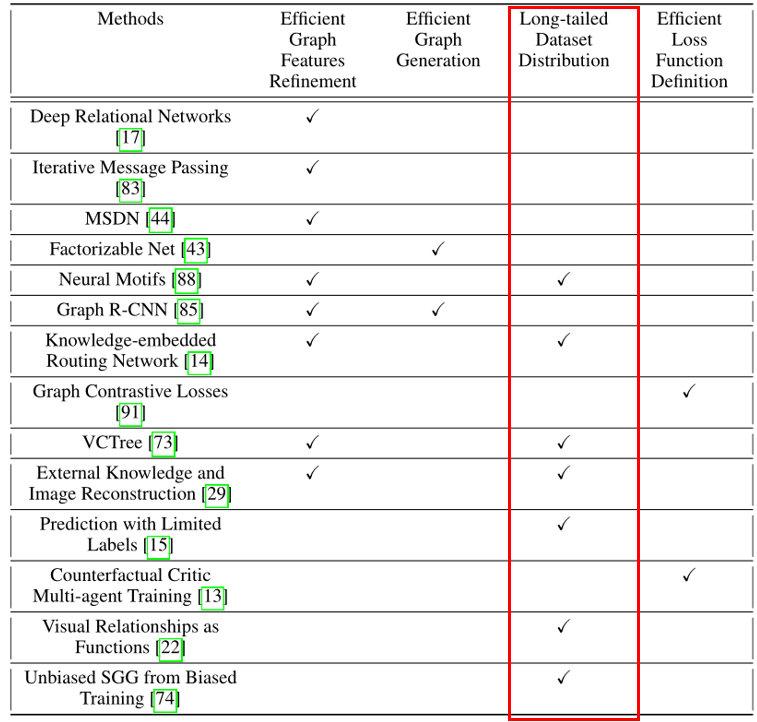
上述七种方法可以根据其利用的技术进一步分为三类。
A. 统计信息(statistical information/semantic space)
[CVPR 2018]Neural Motifs
Visual Genome数据集存在的长尾分布问题由[2018 CVPR]Neural Motifs一文首次提出,虽然他们的工作专注于设计一个特征提取方案,但这篇文章含蓄的指出了,当前基于Visual Genome数据集下作出的Scene Graph或者Visual Relationship Detection,其实说白了都是学习的数据集的bias,并没有真正学习到relationship。
[CVPR 2019]KERN
2019年,有两篇论文同时提出了一模一样的mean Recall@K指标,名字都一样。这两篇论文首次开始关注,怎么衡量和解决无偏场景图。那么我们来看看VCTree和KERN给的两种解决方案。
1)Knowledge-embedded Routing Networks,KERN:虽然MotifNet隐含地试图找到统计相关性,但KERN是第一个在其pipline中显式地建模这些数据统计并在给定目标object对的情况下正则化关系预测的semantic space的工作,因此朝着解决长尾分布问题迈出了第一步。
2)VCTree:用一个独立的分支来学习structure,并确保feature learning的分支和structure learning的分支没有/中断反向传播。这也就保证了,结构和feature不会共同过拟合到一起。下图是我对VCTree核心idea的一个概览图。
[CVPR 2019]External Knowledge and Image Reconstruction
B. 半监督学习和小样本学习
[CVPR 2019]VCTree
下面两篇论文从半监督和小样本学习技术的最新进展中获得灵感,提出了一些解决SGG任务中长尾问题的方法。
[ICCV 2019]Prediction with Limited Labels
这篇文章提出了一种半监督方法,通过使用图像不可知的特征,例如来自一组非常小的已标记关系实例的对象标签和相对空间对象位置,将概率标签分配给未标记图像中的关系。
[ICCV 2019]Visual Relationships as Functions
这篇文章提出了一种利用最近在小样本学习中的研究,从频繁类别中学习对象表示并使用这些来对稀有类别进行小样本预测的方法。
C. TDE
[CVPR 2020 oral]Unbiased Scene Graph Generation from Biased Training
之前的所有技术都需要从头开始训练才能解决问题,并且本质上提出了一个完整的模型,但本文提出了一个独特的框架,可以用在任何经过训练的SGG模型之上,以处理数据集中存在的偏差。该框架利用因果推理的概念,可以附加在任何模型之上,以使模型的关系预测不那么有偏见。
Neural Motifs: Scene Graph Parsing with Global Context
原文链接:https://arxiv.org/abs/1711.06640 这是第一篇关注到VG数据集存在关系类别偏见的文章。 虽然本文没有直接去解决偏见的问题,而是专注于设计一个高效的特征细化模型,但其提出了一个令人震惊的baseline:直接用分析VG数据集得到的先验概率P(relation|subject, object)进行预测(也可以说利用了object对的统计相关性),竟然比当时的state-of-art方法性能好,这充分说明了数据集中对某些关系类别存在偏见。
1 VG数据集分析(subject-object的统计相关性)
文章首先对VG数据集中object和关系的类型和实例数量进行分类整理,结果如下图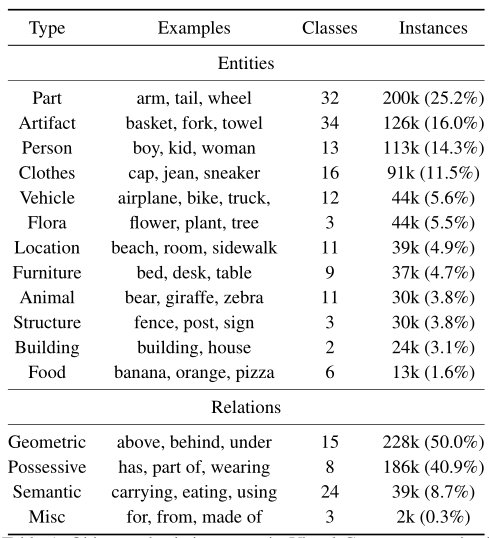
可以看到,90.9%的关系是Geometric(空间几何)或Possessive(所有格)。相比之下,对应于Activity(活动)的Semantic(语义)关系就不那么频繁和明显了,虽然近一半(24/40)的关系类型本质上是语义的,但它们只包含8.7%的关系实例,同时,在语义关系中“using”和“holding”占所有语义关系实例的32.2%。
根据上图对object和关系的分类整理,可以进一步可视化VG数据集的object类型和关系类型的分布,如下图。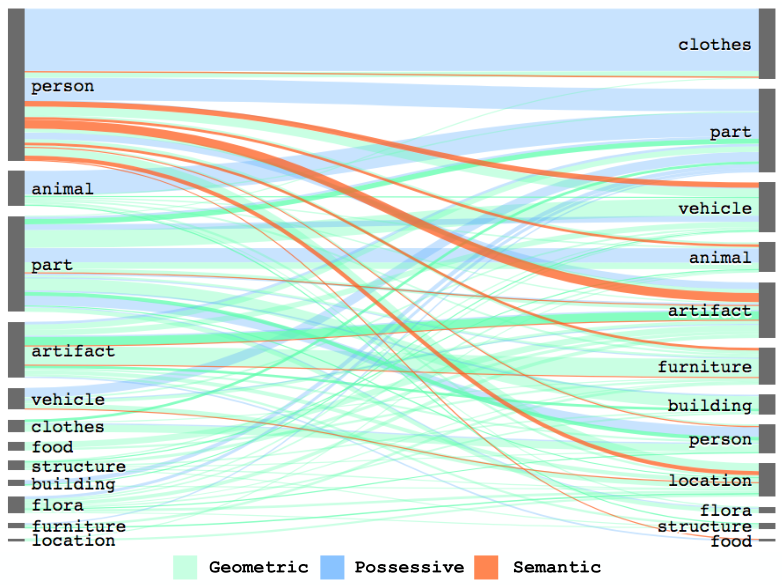
从图中可以看到:服装和某些object几乎都是通过Possessive关系来联系的,而家具和建筑object几乎都是通过Geometric关系来联系的;几乎所有的Semantic关系都是由人主导的。这表明常识先验(common sense priors)在生成准确的场景图中起着重要作用。
在下图中,文章测试了在仅给定某些标签的前提下(不包含图像特征),预测场景图中的头结点(object)、边(关系)或尾结点(object)标签的可能性,其中较高的曲线意味着该元素的标签在给定其他值时是高度确定的。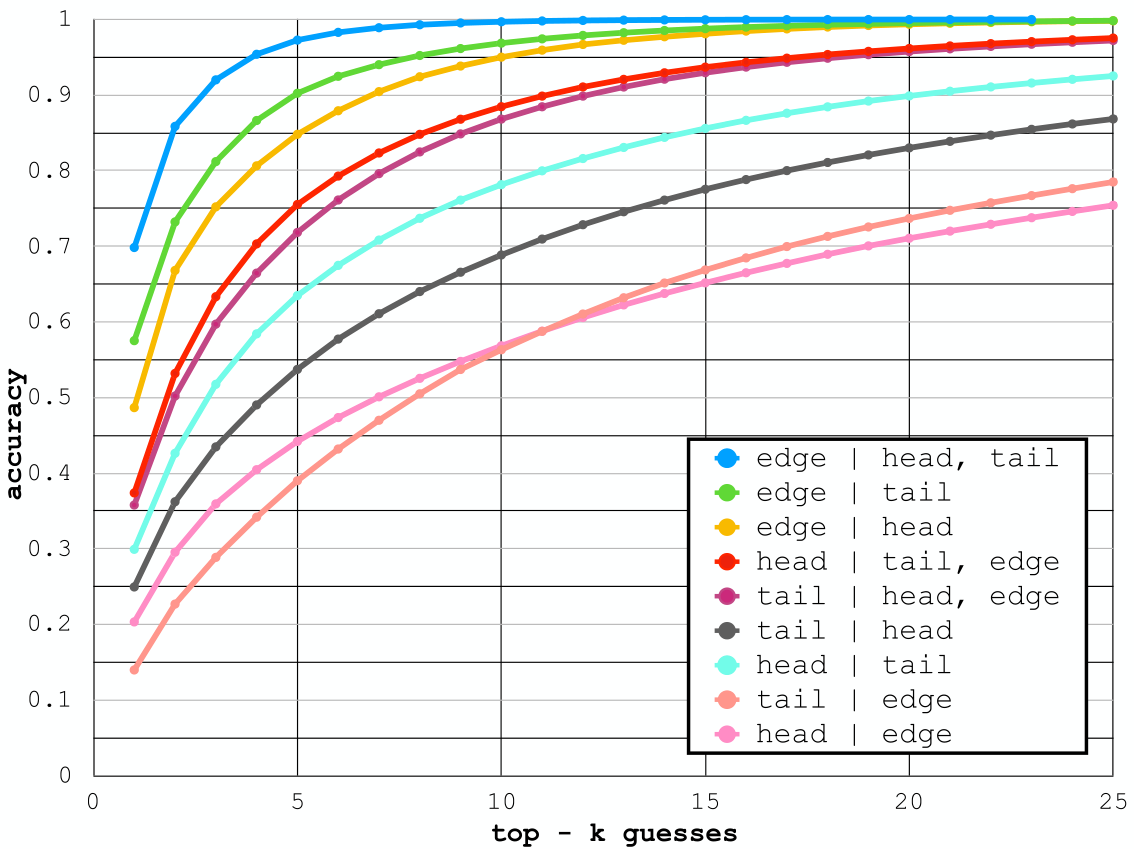
从图中可以看出,头尾结点的标签提供了重要的信息,无论是对彼此还是对边的标签,在已经给出的头或尾标签的基础上添加边标签只会带来最小的收益。最重要的是,图中显示,根据object对的标签,关系的标签是高度确定的:**给定object对的标签,预测其最频繁的关系有70%的概率是正确的,而预测这对object的前5个最频繁的关系的话,则有97%的概率包含正确的标签**。这种强烈的偏见使得object的标签在预测关系时变得至关重要。
2 新的模型 Stacked Motif Network(SMN)
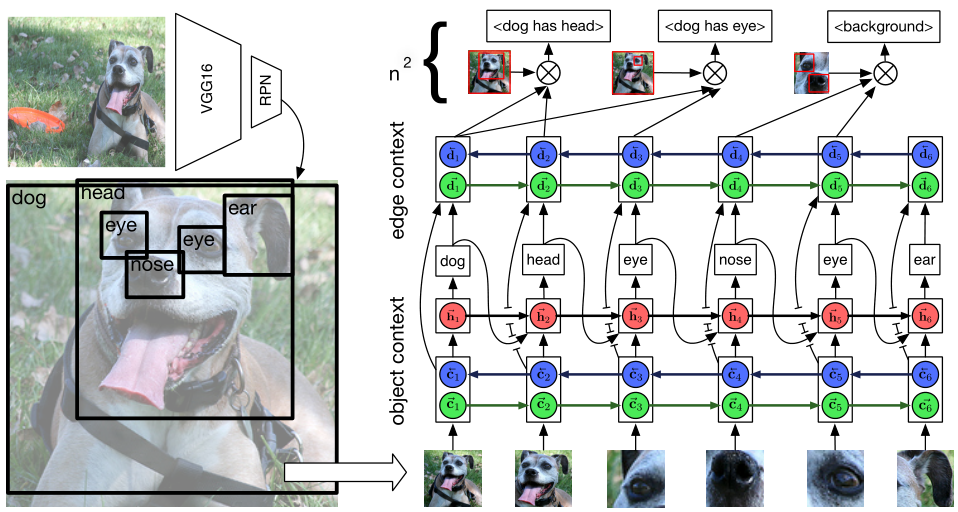
该模型并没有明确地针对数据集的长尾分布问题,故不再详说。
3 实验
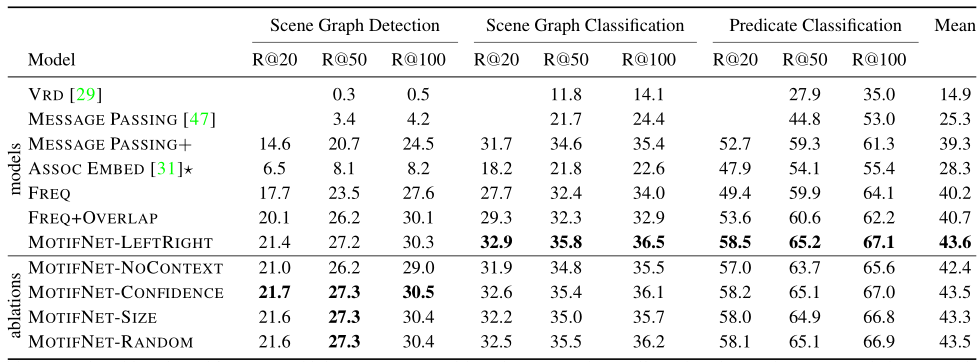
3.1 数据集
本次实验使用Visual Genome(VG)数据集,遵循广泛采用的分割方式,即使用包含150个最常见的object类别和50个最常见的predicate类别的VG分割。
3.2 实验内容
评价指标使用Recall@K,同时实验包括SGG常用的三个子任务PredCls、SGCls、SGDet(SGGen)。
为了体现文章对于VG数据集的分析结果,额外引入了几个额外的frequency baselines,这些baseline建立在训练集的统计数据上。frequency baseline分别是:
- FREQ:使用预训练的目标检测器来预测每个RoI的object标签。为了获得两个object之间的关系概率,查找在训练集中计算的这两个object关系的频率分布(即直接使用先验概率P(Relation| Subject, Object)来预测关系)。
- FREQ-OVERLAP:在FREQ的基础上,要求两个RoI相交,才算这两个object有关系。
3.3 实验结果
从表中可以看到,FREQ+OVERLAP竟然比之前state-of-art方法MESSAGE PASSING+的性能平均提高了5.5%,这清楚地表明数据集中对某些特定关系类型有一定的偏向,关系类别的不平衡是相当明显的。
当然,本文提出的模型Stacked Motif Network通过捕获更好的global context相比于FREQ+OVERLAP还是有一定的提升,但是该模型并没有明确地针对长尾分布问题。
KERN: Knowledge-Embedded Routing Network for Scene Graph Generation
原文链接:https://arxiv.org/pdf/1903.03326v1.pdf KERN试图利用object对与其关系之间的统计相关性的先验知识来解决VG数据集关系分布不均匀的问题。 Neural Motifs是先前作品中表现最好的方法,它通过编码global context隐含地捕捉object对与其关系之间的统计相关性,但没有将其实际应用到模型中。KERN则是第一个在其pipeline中明确建模统计相关性或者说KERN第一次将统计知识与深度架构明确统一起来,利用统计知识明确地规范化关系预测的语义空间,通过明确规范关系预测的语义空间,KERN可以很好地解决现实世界关系分布不均匀的问题。 可以说KERN为解决长尾问题迈出了第一步。
1 动机
由于现实世界中的关系分布严重不平衡,现有的方法对于训练样本有限的关系表现很差。以Visual Genome数据集为例,文章分别评估了前10个最频繁关系的样本(即“top 10”子集)和其余不太频繁关系的样本(即“the rest”子集)的性能。如下图所示,如果有足够的训练样本,当前state-of-art方法SMN(Stacked Motif Networks,即Neural Motifs一文中的模型)可以有很好的性能,但如果没有足够的训练样本,那它的性能会严重下降。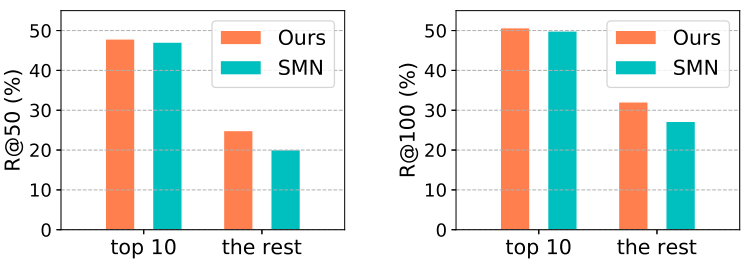
根据Neural Motifs一文中对VG数据集的统计分析显示,直接预测具有给定标签的object对的最频繁关系的baseline方法FREQ优于之前的state-of-art方法Iterative Message Passing。因此,对这些object对和关系之间的统计相关性进行建模,可以有效地规则化semantic prediction space,从而解决关系样本不均匀分布的问题。另一方面,从Iterative Message Passing一文中也可得知,场景中关系和object对的相互作用(interplay)在场景图生成中也起着重要作用。
2 本文工作
本文证明了object对和其关系的统计相关性可以用一个结构化的知识图(structured knowledge graph)来明确表示,同时,object对和其关系之间的相互作用可以通过在图中传播节点消息(propagating node messages through the graph)来捕捉。类似地,context也可以通过另一个具有消息传播的图来捕捉。由此,本文引入了一种新的Knowledge-Embedded Routing Network(KERN),KERN**在先验统计知识的明确指导下捕获object和其关系的相互作用,并自动挖掘context以促进场景图的生成**。
虽然以前的研究也注意到了统计知识,但它们只是通过关系和object之间的迭代消息传播(Iterative Message Passing)或通过对object和关系的global context进行编码(Neural Motifs)来隐含地挖掘这些信息。相反,KERN以结构化图的形式正式表示这些统计知识,并将该图合并到深度传播网络中作为额外的指导。这样,它可以有效地调整object对的可能关系的分布,从而使预测不那么模糊,即利用统计知识明确地规范关系预测的语义空间。如上图所示,对于样本充足的关系,KERN取得了微小的改进,对于样本有限的关系,这种改进更加明显。
另一方面,本文还发现场景图生成任务的评价指标Recall@K容易被拥有大比例样本的关系的表现所支配,所以提出了一个新的评价指标mean Recall@K,这个指标和VCTree文章中新提出的指标名字一样,效果也完全一样。
3 新的模型 Knowledge-Embedded Routing Network
场景图定义为一个三元组:G={B, O, R},其中
- B={b, b, …, b}是区域候选集
- O={o, o, …, o}是object集,其中o表示区域b的相应类别标签
- R={r, r, …, r}是关系集,其中r是主体(b, o)和客体(b, o)以及关系标签x∈R的三元组。R是所有关系的集合,包括表示给定object对之间没有关系的非关系。
给定图像I,场景图的概率分布p(G|I)可以分解为三个部分:
p(G|I) = p(B|I)p(O|B, I)p(R|O, B, I)
上述公式也可以称为场景图生成的数学模型。
最后的场景图就是通过对这三个部分的预测而最终生成的结果。
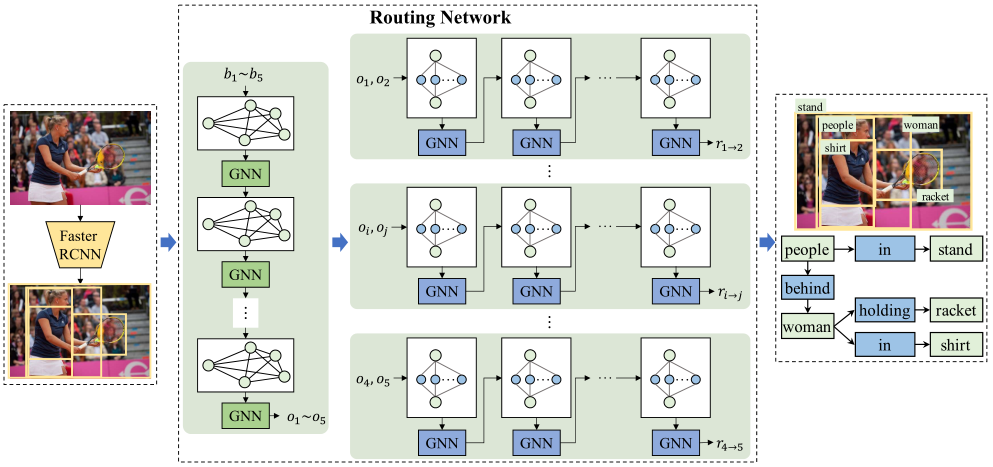
3.1 模型简述
给定一幅图像,模型首先采用Faster RCNN来提取一组候选区域。然后,构建一个图来关联这些候选区域(也可以称为候选场景图,这里选择的是简单的全连通图),并使用GNN来学习context表示来预测每个区域的类别标签。对于每个具有预测标签的object对,模型构建另一个图来将给定的object对与所有可能的关系相关联,并使用GNN来推断它们的关系。对所有object对重复该过程,最后生成场景图。
整个网络共两个模块,即Faster RCNN和Routing Network,接下来将对模型的两个模块Faster RCNN和Routing Network进行详细解析。
3.2 Faster RCNN
这一部分可以对应于数学模型中的p(B|I)
该模块用于提取给定图像I的候选区域B={b, b, …, b}。对于每个区域,除了表示其位置的边界框bounding box b,模型还使用ROI pooling层提取区域的特征向量f,这些特征向量将被送到传播网络中,用于随后的推理。
3.3 Routing Network
该模块就是本文的核心,我认为该模块就是实现KERN中knowledge-embedded的部分,即将统计信息融入到特征中去,这也是本节主要解析的内容,对于使用GNN传递信息的过程不再详叙。
该模块可以分为两个部分,即上图的左右两部分,分别用于预测object标签和关系标签。
A. 预测object标签
这一部分通过出现在图像中的region来传播信息,从而学习contextualized representation。个人认为这一部分就是Neural Motifs一文中的思想(或许是Iterative Message Passing的思想?还未阅读)。
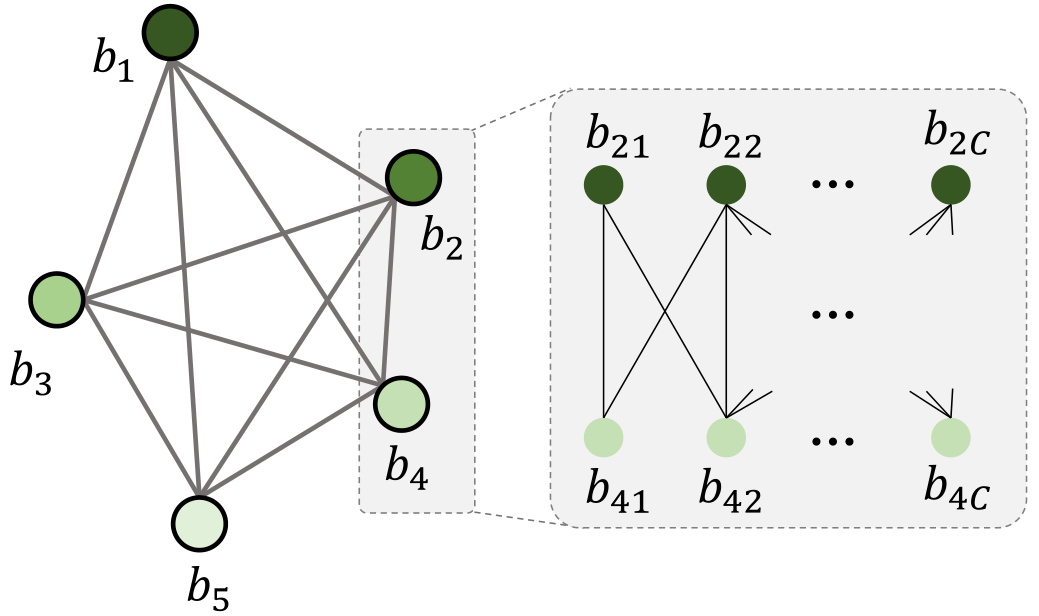
在这一部分,模型创建了一个图,如上图所示,图的结点是候选区域B={b, b, …, b},然后根据object的统计相关性矩阵M来关联图的所有候选区域结点。
构建M的过程:**首先统计来自不同类别的object在数据集(如VG)的训练集上共同出现的概率。具体来说,就是对于c和c’两个类别,在属于c’类object存在的情况下,计算c类object存在的概率m(如“人”存在的情况下,“帽子”存在的概率是0.x)。统计所有object类别对共同存在的概率,得到一个矩阵M∈R,其中C是object类别的数量。然后,我们基于矩阵M∈所有区域。给定b和b两个区域,我们复制b共C次以获得结点C={b, b, …, b},结点b表示区域b与类别c的相关性,对b也执行相同的过程。直观来看,m可用于将结点b和结点b和关联起来,因此统计相关性矩阵M∈可用于将候选区域结点相关联。
现在,为了获得每个节点一个对象预测,受Graph Gated Neural Networks(gated GNN)启发,采用一种 gated recurrent更新机制去提炼特征和预测object类别,在此不再详述。这一部分最后输出的结果是object类别标签O={o, o, …, o},作为下一部分的输入。
B. 预测关系标签
给定object对的类别,它们之间关系的概率分布是高度偏斜的。例如,给定一个主语“人”和一个宾语“马”,它们的关系很可能是“骑”。在这里,我们以结构化图的形式表示object对及其关系的统计相关性,如下图所示,并采用另一个GNN来探索object对和其关系的相互作用以推断关系。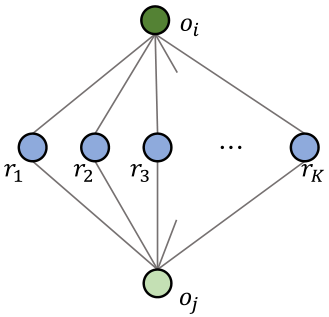
以结构化图形式表示object对及其关系的统计相关性的过程:图中结点表示object和关系,边表示对应object对和所有关系之间共同存在的统计信息。具体来说,先计算给定类别c的object和类别c’的object之间所有可能关系的概率,它们被表示为{m, m, …, m},其中K是所有关系类别的数量。那么对于该部分的输入object o和object o,模型构造了一个带有两个object结点和K个关系结点的图。使用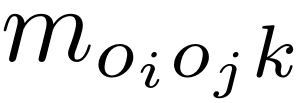 来表示o、o和关系结点k之间的相关性,这样就建立了一个嵌入统计信息的图。
来表示o、o和关系结点k之间的相关性,这样就建立了一个嵌入统计信息的图。
得到上述图后,使用相同的gated GNN架构,文章称为identical graph gated recurrent的更新机制去更新特征以获得最终场景图预测结果。
4 实验
4.1 数据集
本文和Neural Motifs一文的数据集设置几乎一样,即使用Visual Genome(VG)数据集,遵循广泛采用的分割方式,即使用包含150个最常见的object类别和50个最常见的predicate类别的VG分割。
4.2 新指标mean Recall@K
4.2 实验内容
采用经典的三个场景图生成子任务PredCls、SGCls和SGGen来评估模型。在评价指标方面,本文不但使用了最常用的Recall@K,还提出了一个新的指标mean Recall@K,这一指标在VCTree一文中再讨论,本文直接使用。
同时,本文还提出以前的一些工作(如Iterative Message Passing)在计算R@K时的约束条件(Constraint)是:对于给定的object对,只能获得其一种关系。而其他一些工作在计算R@K时则忽略了这一约束,从而获得了更高的R@K。那么本文在报告R@K和mR@K时,分为了有约束(Constraint)和无约束(No constraint)两种情况。
各种方法的比较情况如下:
AE:Associative Embedding
IMP:Iterative Message Passing
IMP+:使用更好目标检测器的Iterative Message Passing
FREQ:Neural Motifs中提出的一个baseline
SMN:Stacked Motif Networks,Neural Motifs一文中提出的方法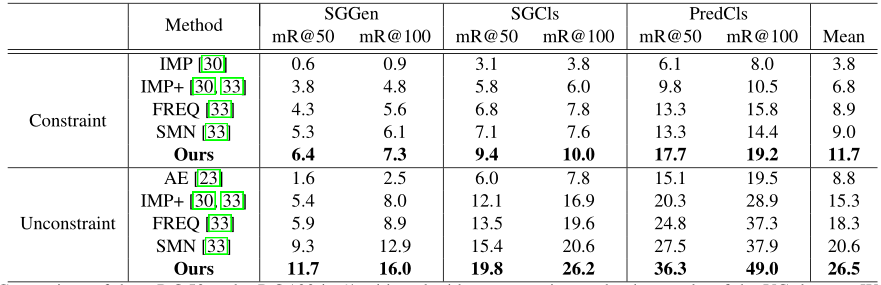
如上图可以看到,FREQ比先前所有的方法表现都好,这说明object对和其关系之间的统计相关性相比于其他信息(如contextual cues,Iterative Message Passing文章中的内容)起着同等甚至更重要的作用。SMN是现有作品中表现最好的方法,它通过编码global context隐含地捕捉统计相关性;通过明确地合并统计相关性,我们的方法可以更好地利用它们,显著地改进性能。具体来说,在这两种设置下,KERN在所有三个任务上都始终优于现有方法。
为了与现有方法进行全面比较,下表给出了所有方法的R@50和R@100: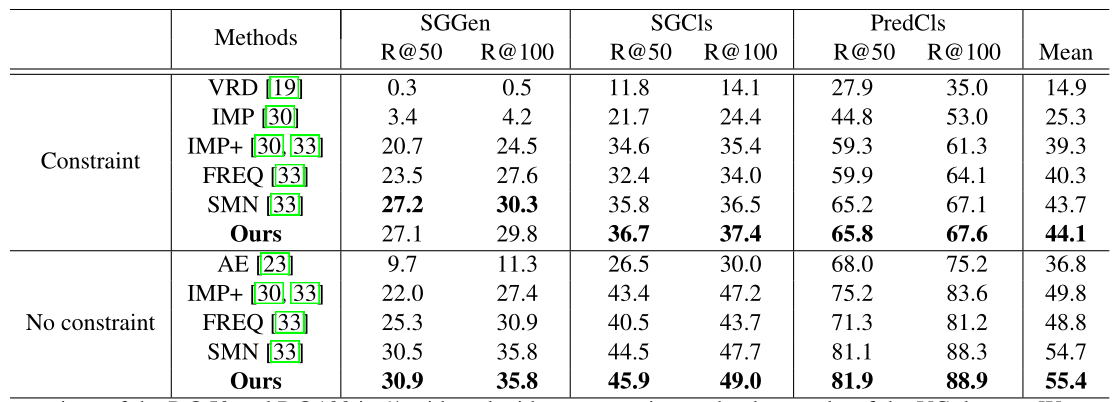
4.3 深入分析KERN性能的提升
如4.2节中的比较所示,与现有的state-of-the-art方法相比,我们的方法在mR@K和R@K指标上都有所改进。然而,我们发现KERN在mR@K指标的改进比R@K指标的改进明显得多。因此,本文对此现象展开了更深入的分析。
下图是不同关系类别在VG数据集上的分布。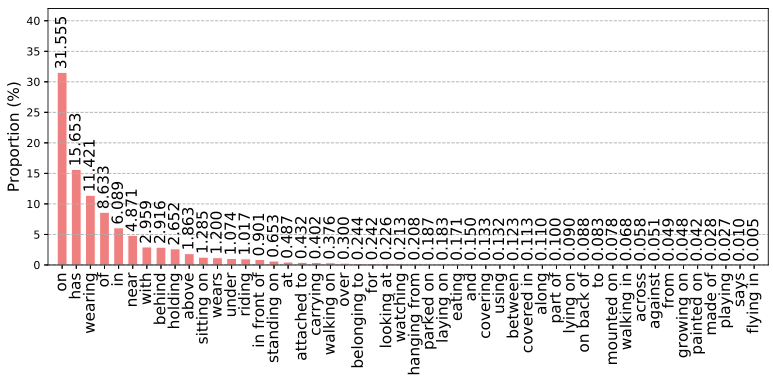
如上图,关系分布极不均匀。前10个最频繁的关系的样本数量占总样本数量近90%,其余40个关系的样本仅占10%左右。
如下图所示,SMN对于频繁的关系表现得相当好,例如“on”、“has”;,对于样本较少的关系(例如“make of”、“to”),SMN表现很差。然而,由于R@K指标是由模型在这些最频繁关系上的表现所主导的,所以SMN的R@K指标仍然很高。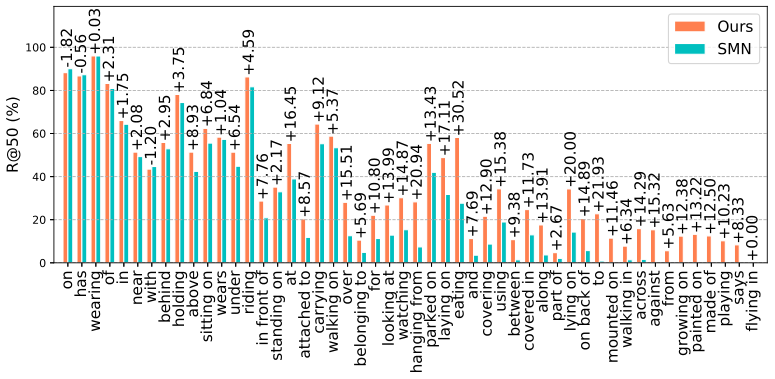
mR@K指标衡量所有关系的整体表现,因此,对频繁关系的过拟合导致SMN的mR@K指标明显下降。
与现有的方法不同,本文模型集成了先验知识,对semantic space进行显式正则化;因此,对于这些不太频繁的关系,它也表现良好。这样,本文模型可以很好地解决关系分布不均的问题。
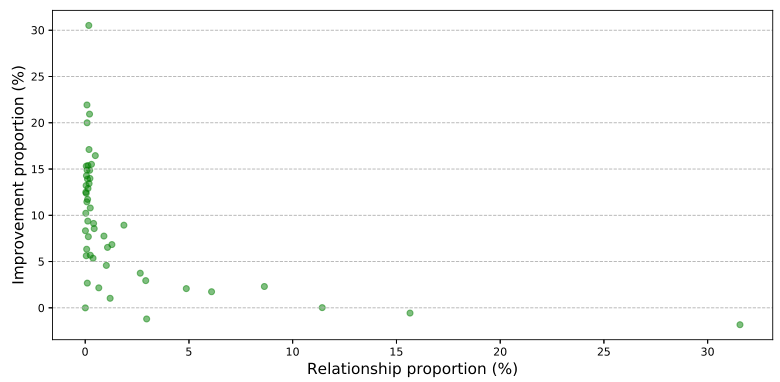
为了更直接地比较性能改进和样本数量之间的关系,我们在下面两张图中进一步给出了KERN相比于SMN的不同关系和样本比例的改进。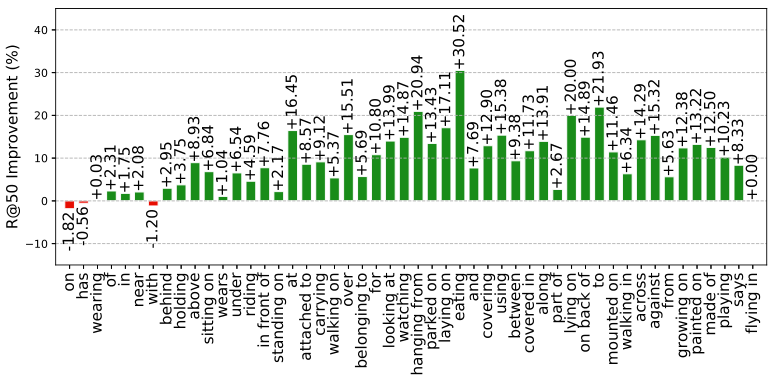
4.4 消融实验
KERN的核心是将object对及其关系的统计相关性融入模型,为了验证其有效性,令模型不使用object相关性w/o rk以及关系相关性w/o rk,实验结果如下: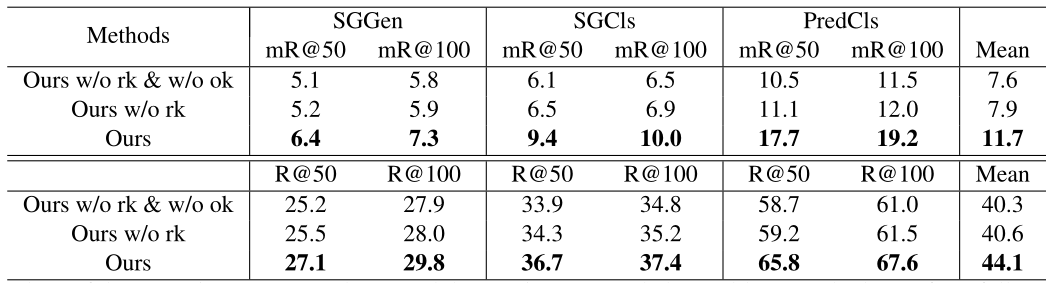
这种明显的性能下降清楚地表明,纳入统计相关性有助于场景图的生成。
Visual Relationships as Functions: Enabling Few-Shot Scene Graph Prediction
上述模型致力于使用统计信息来获得期望的结果,但是在各种文献工作中也有使用了小样本学习和半监督技术来处理数据集的不平衡。 本篇文章从小样本学习的最新进展中获得了灵感,提出了第一个支持小样本学习的SGG模型,同时,该模型也可用于解决SGG任务中的长尾问题。
简述
本文提出了一种方法,从频繁类别中学习对象表示(object representations),然后使用对象表示来对稀有类别进行预测。这是通过使用一种机制来创建对象表示来完成的,该对象表示对对象提供的关系进行编码(encode relationships afforded by the object)。这个想法是,如果一个subject表示被一个特定的谓词转换,结果object表示应该接近与subject有相似关系的其他对象。
例如,if we transform the subject, person, with the predicate riding, 所得到的object表示应该接近于可被骑的对象的表示,并且同时在空间上低于主体。
对于这样的转换,我们把谓词当作函数来处理,把它分成两个单独的函数:一个正向函数把object表示转换成subject,一个反向函数把subject表示转换回object。每一个都被进一步分成两个部分:一个空间部分(f,p)将注意力转移到image space,一个语义部分(f,p)对对象特征进行操作。
模型的pipeline如下图所示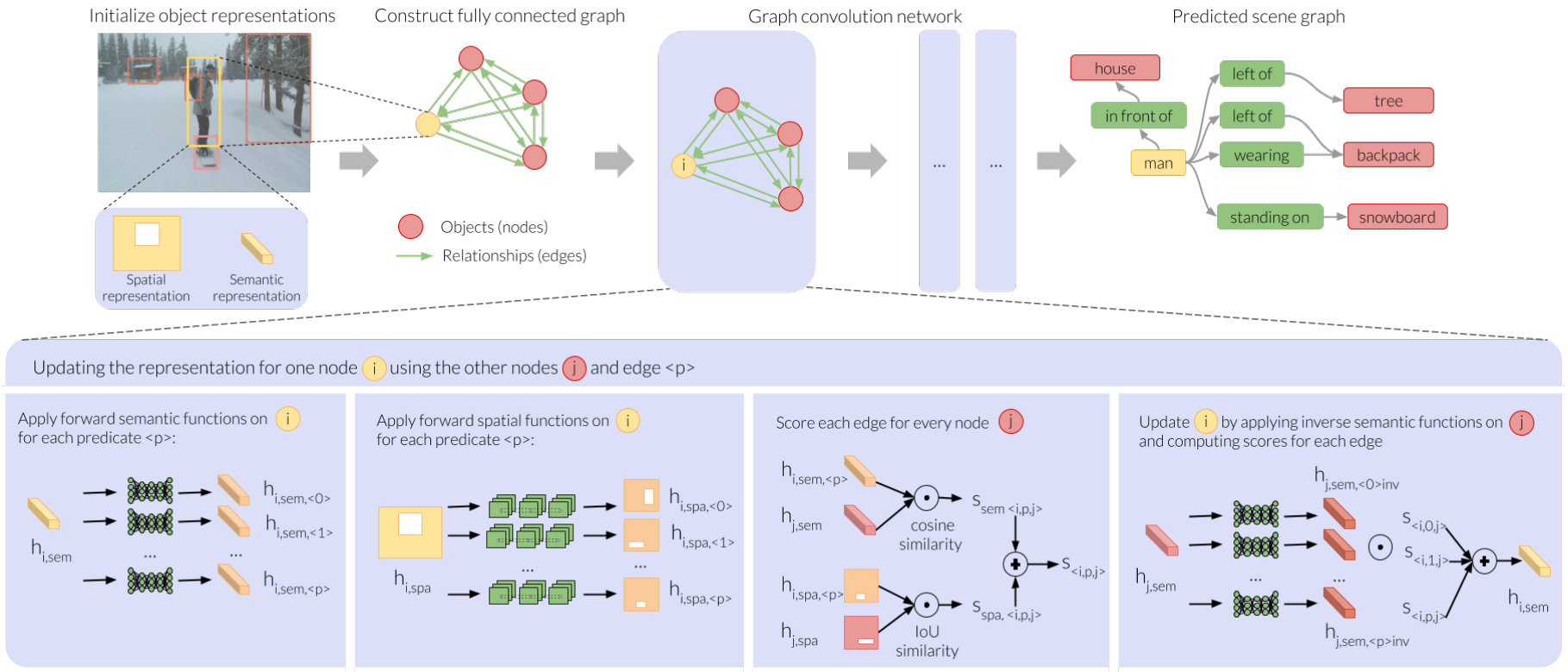
动机
然而,由于训练关系实例在世界上和训练数据中的不均匀分布,现有的场景图模型只能在最频繁的关系中执行。
因此,迄今为止的所有场景图模型都忽略了稀有关系的长尾。
为了使模型能够用很少的例子学习谓词,我们需要一种机制来创建对象表示,该对象表示对对象提供的关系进行编码。如果我们用一个特定的谓词来转换一个subject表示,那么结果应该是提供与subject相似关系的object。例如,如果我们转换subject,person,用谓语ride,得到的宾语表示应该接近可以骑行的object表示。
现有的场景图模型[18,38,57,6,55]不能执行谓词的少镜头预测,因为它们的对象表示没有编码足够的关于它们提供的关系的信息。例如,神经基序[57]利用语言先验来表示物体。他们的工作发现,对象类别,而不是它们的表示,在很大程度上指示了对象之间存在的关系,从而依赖于数据集偏差。然而,依赖于这种偏见是不会转移的——一个模型在<人- 骑 - 马>的context下看到一个“骑马”的例子,并不会学会预测,当它看到<人 - ? - 滑雪板>时。
只有当滑雪板和马有相似的物体表现时,这种转移小样本才有可能。我们如何设计一个场景图模型来学习将视觉关系的信息编码到对象表示中?
相关工作
然而,所有这些方法都使用对象特征对谓词进行分类,将对象特征与谓词信息混淆,这妨碍了它们在用于训练新的少量谓词类别时的效用。
相反,我们学习对节点之间的谓词函数进行评分,在多次迭代中加强正确的关系并弱化不正确的关系。
虽然基于图的学习通常需要大量的训练数据,但我们扩展了少量预测的工作,以展示如何使用谓词函数学习的对象表示可以进一步用于转移到罕见的谓词。少拍文学大致分为两个主要框架。第一种策略是为一组频繁类别学习一个分类器,然后用它们来学习少量类别[12,13,32,49,39,6]。第二种策略是学习不变量或分解,从而实现少镜头分类[27,52,50,14]。我们的框架更像第一个框架。
pipe line: 带有谓词函数的图形卷积框架
在这一部分,我们描述我们的图形卷积框架(如上图)和谓词函数。该框架负责在图形卷积框架中使用频繁谓词创建对象表示。**这些表示将在下一节中使用,以实现罕见谓词的少量预测。
本节目标:
我们的目标是使用频繁谓词学习一个有效对象表示。
为了确保表示将有相似关系的对象投影在一起,我们将谓词设计为嵌入在图形卷积网络的转换对象的函数。这些功能是在场景图生成任务期间学习的。
公式化:
图片I;
bbox proposal B={b1, b2…bn}(使用Faster RCNN中的region proposal network);
根据B,提取出最初的object特征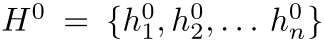
H和B输入我们的图卷积框架
**
框架的输出是一个场景图G={V, ε, P},其中结点:objects vi ∈V;边:relationship 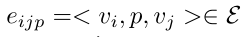
其中p∈P,是谓词类别之一
传统图卷积:
我们的模型主要是作为在局部图邻域上运行的GCN的扩展而提出的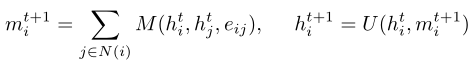
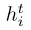 是gcn网络中结点vi的第t层输出
是gcn网络中结点vi的第t层输出
M()和U()分别是聚集和顶点更新函数,用于累积来自其他节点的信息。
N(i)是结点i的邻居集
我们的GCN:
类似于以前使用多个边类别的工作[47],我们扩展了上述公式以支持多个边类型,即给定两个节点vi和vj,对于所有|P|谓词类别,从vi到vj存在一个边。与以前的工作不同,在以前的工作中,边是输入[47],我们初始化一个完全连通的图,即所有对象都通过所有谓词边与所有其他对象相连。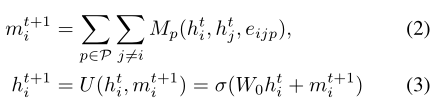
其中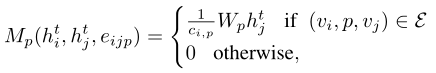
cip是边ij的归一化常数
传统来说,h包含对象的语义特征,即D维常量
本文将对象的空间特征也进行了融入,得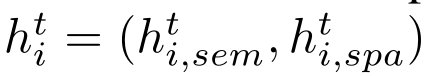 其中
其中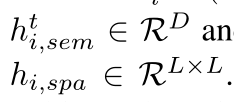
这样,之前的聚合公式变为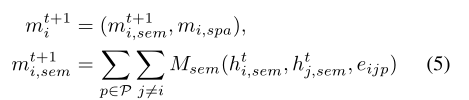
其中mispa是固定的
为了定义Msem,我们为每个谓词p引入了语义(fsem,p)和空间(fspa,p)谓词函数。
其中semantic function是MLP,而spatial** function是卷积层,各有6层+一个ReLu激活函数。**
我们试图同时执行节点分类和边预测。在不知道哪些边实际存在的情况下,如果我们允许每个谓词同等地影响另一个节点,我们将会增加很多噪声。为了避免这个问题,我们首先为每个谓词p计算一个分数: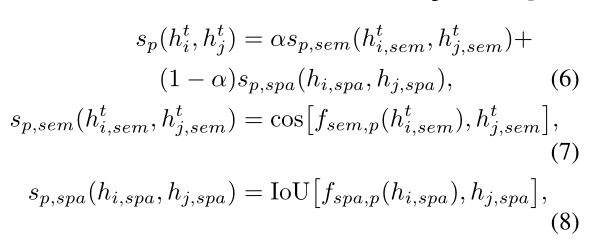
其中α ∈ [0,1]是超参数,cos()是余弦距离函数,IoU()是。。。
这给出了节点vi认为边< vi,p,vj >存在的可能性的分数。
这个分数用于衡量在等式3的更新中,节点vj将通过谓词p影响节点vi的程度。我们现在可以定义: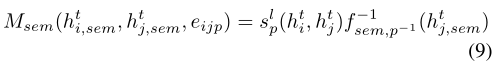
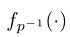 表示从object返回到subject的后向谓词函数。例如,给定关系<人-骑-滑雪板>,我们的模型不仅学习如何使用函数riding转换人,还学习如何使用逆谓词riding-1将滑雪板转换为人。学习每个谓词的向前和向后函数允许我们在两个方向传递消息,即使我们的谓词是有向边。
表示从object返回到subject的后向谓词函数。例如,给定关系<人-骑-滑雪板>,我们的模型不仅学习如何使用函数riding转换人,还学习如何使用逆谓词riding-1将滑雪板转换为人。学习每个谓词的向前和向后函数允许我们在两个方向传递消息,即使我们的谓词是有向边。
Usem()累积语义函数传递的消息,以更新语义对象表示: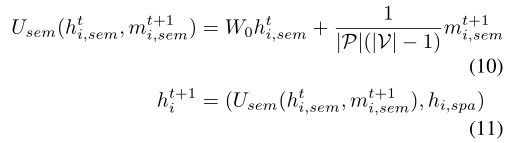
空间表示不会更新,因为对象的空间位置不会移动。
输出场景图
我们使用vi= g(hi)来预测节点类别,其中g是一个MLP,它生成所有可能的对象类别的概率分布。
只有当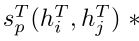
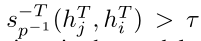 ,每个可能的关系才会作为关系输出。T是模型中的总迭代次数,τ是阈值超参数。
,每个可能的关系才会作为关系输出。T是模型中的总迭代次数,τ是阈值超参数。
Few-shot predicate framework

我们利用在图形卷积网络中训练的对象表示来训练小样本谓词。回想一下,语义(fsem,p)和空间(fspa,p)谓词函数是使用频繁谓词p ∈ P训练的。
我们将小样本谓词分类器设计为两层的MLPs,层间有ReLU激活。假设稀有谓词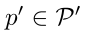 ,每个谓词有7个实例
,每个谓词有7个实例
通过在图形卷积中分解对象的谓词表示,我们创建了一个支持谓词转换的表示空间。我们将在实验中展示,我们的表示将语义相似的对象放在一起,这些对象参与相似的关系。现在,当使用很少的稀有谓词的例子进行训练时,例如驾驶,我们可以依赖于通过骑行聚集的对象的语义嵌入。
我们通过已学习的谓词函数传递对象谓词对< vi,p’,vj >的所有k个标记示例,并从最终图形卷积层提取隐藏表示(hi,sem,hi,spa)和(hj,sem,hj,spa)。
我们沿着通道维度连接这些转换,并将它们作为输入提供给小样本分类器。
实验
进行了两个实验:
我们的第一个实验测试了我们的方法在实现少镜头场景图预测这一主要目标上的实用性。在这项任务中,我们的模型优于竞争基线,验证了我们的假设,即构建捕捉所提供的关系的对象表示将能够实现更好的少量传输。
我们的第二个实验研究了我们的图形卷积框架,并将我们的场景图形预测性能与现有的最先进的方法进行了比较。回想一下,我们的目标不是优化场景图预测性能。然而,我们的模型优于现有的使用视觉特征回忆@50的模型,但是正如预期的那样,与使用模糊先验或数据集偏差的模型相比,表现不佳。我们还表明,将关系信息编码到对象表示中也会损害对象分类。我们的第三个实验展示了我们的模型是如何通过可视化预测转换来解释的。
数据集
我们使用视觉基因组[30]数据集进行训练、验证和测试。为了对现有的场景图方法进行基准测试,我们使用了150个对象和50个谓词类别的常用子集[55,57,56]。
对于SGG
评价指标
Recall@k
subTask**
老三样
对于Few-show predict,我们在PredCls的任务中报告了recall@1和recall@50。我们从k ∈ [1,2,3,4,5]中改变可用于训练小样本谓词分类器的有标签的例子的数量。我们在测试集中报告召回@50和召回@100。
Few-shot prediction
我们的第一个实验研究我们如何用拥有有限例子的每个谓词来执行少镜头场景图预测。我们的方法需要一组频繁出现的谓词和一组仅有k个例子的罕见谓词。我们将可视化基因组中通常使用的50个谓词分割开来,将训练样本最多的25个谓词放入第一个集合,并将剩余的25个谓词放入第二个集合。我们使用第一个集合中的谓词来训练谓词函数和图形卷积框架。接下来,我们使用它们,通过使用由预处理谓词函数生成的表示,为第二个集合中的稀有谓词训练k-shot分类器。我们迭代k ∈ [1,2,3,4,5]。
在图4中显示,我们的方法在所有k值上优于所有基线比较。我们的改进随着k增加到k = 5而增加,其中我们在50时优于GloV e [43]基线3.7和迁移学习基线8.7。对于k ≥ 10的值,神经模体模型优于我们的模型。这是意料之中的,因为神经模体使用数据集中对象和谓词之间的偏差,随着更多的数据用于训练模型,这些偏差会变得更强。在图5中,我们显示了由我们的完整模型生成的场景图,包括频繁谓词和罕见谓词。我们在fewshot学习设置中的性能验证了我们的假设,即构建嵌入关系信息的对象表示可以更好地转移到稀有谓词。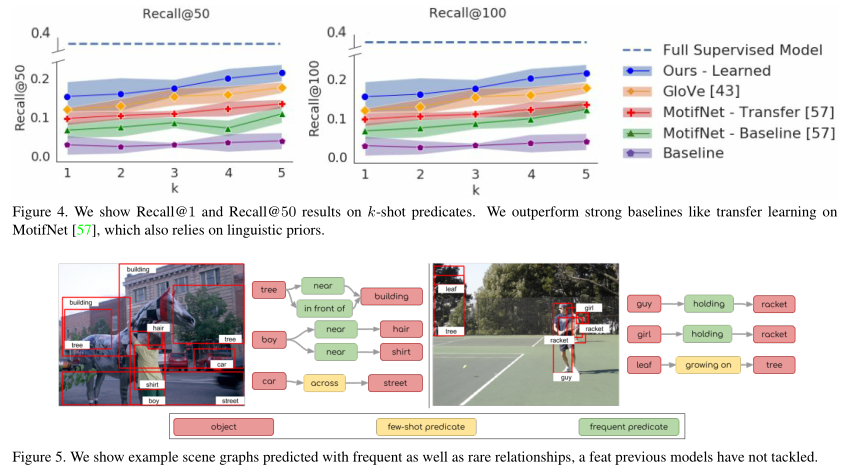
VCTree: Learning to Compose Dynamic Tree Structures for Visual Contexts
现有的作品利用回忆@K(简称R@K) [19]作为评价尺度。然而,这个度量很容易被具有大比例样本的关系的表现所支配。由于不同关系的分布严重不均匀,如果一种方法在几个最频繁的关系上表现良好,它可以获得很高的R@K分数。因此,它不能很好地衡量所有关系的表现。为了解决这个问题,我们进一步提出了一个平均回忆@K(简称mR@K)作为补充评估指标。它首先计算每个关系样本的R@K,然后对所有关系进行平均,以获得mR@K。与R@K相比,mR@K可以对所有关系进行更全面的绩效评估。

若有收获,就点个赞吧
0 人点赞
