激活函数定义
激活函数是控制神经元输出阈值的,即如果输入没有超过阈值,则神经元不会产生输出。
- 输出一般并不是简单的简单的线性输入关系,而是通过激活函数控制
- 激活函数有多种类别,每个激活函数也有其独特性质
多种激活函数
对于激活函数层来说
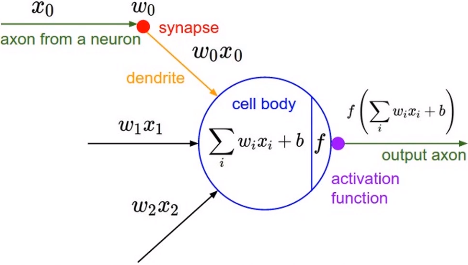
input.shape == output.shapetorch.nn.Sigmoid()
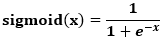
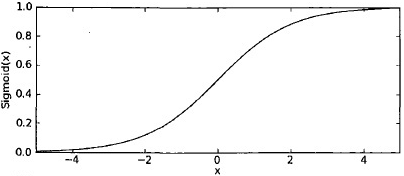
特点梯度比较好求
- 可能出现梯度离散的情况,因为其梯度在x轴两端接近于0
- 常用于二分类任务神经网络最后一层的激活函数,且多与交叉熵损失函数配合使用
torch.nn.Softmax()
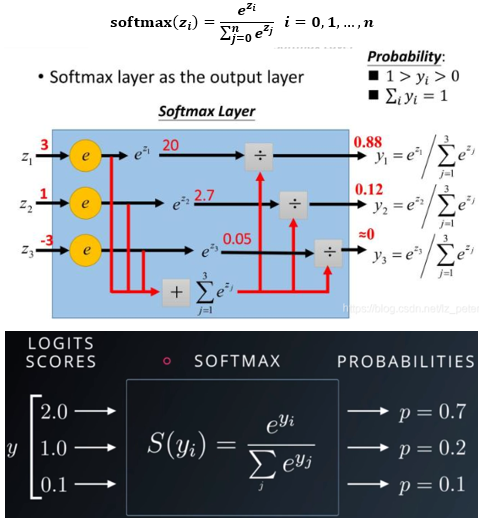
特点
- softmax函数,又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
- softmax函数的原理
softmax第一步就是将模型的预测结果转化到指数函数(指数函数的非负性)上,这样保证了概率的非负性。为了确保各个预测结果的概率之和等于1。我们只需要将转换后的结果进行归一化处理。方法就是将转化后的结果除以所有转化后结果之和,可以理解为转化后结果占总数的百分比。这样就得到近似的概率。
- 常用于多分类任务神经网络最后一层的激活函数,且多与交叉熵损失函数配合使用
- 该激活函数有两个特点
- 将输入向量元素的值进行放缩,使其和为1
- 将最大值与其他值的差距进一步扩大
torch.nn.Tanh()
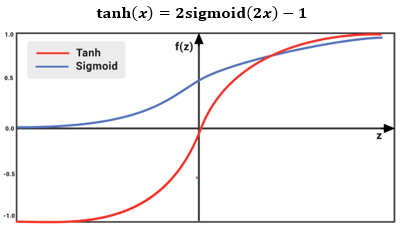
特点
- 该函数在RNN中使用比较多,与sigmoid很类似,区别是其取值在(-1, 1)
- 可能出现梯度离散的情况
- 梯度比sigmoid大
torch.nn.Relu(inplace=False)
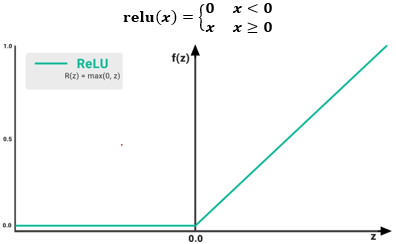
- inplace — 原地计算选项,即是否改变传入的数据,默认为False,将该激活函数加入神经网络模型中时,一般需要显式设置该属性为True
特点
- 该函数是使用最频繁的激活函数
- 该函数一定程度上解决了sigmoid函数梯度离散的情况,因其x>0时梯度固定为1
torch.nn.LeakyRelu()
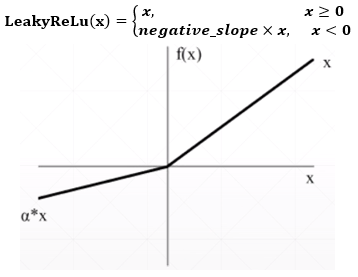
- negative_slope — 指定x<0时的梯度,默认为0.01
特点
- ReLu函数的改进版本,解决ReLu函数在x<0时梯度为0的情况,也就避免了x<0时,因为梯度为0而停止优化的情况
torch.nn.SELU(inplace=False)
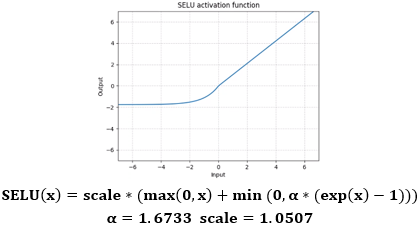
特点
- 一种在x=0处比ReLu更光滑的函数,SELU可以说是两种函数的合并

若有收获,就点个赞吧
0 人点赞
