原文
缩写
SG:Scene Graph 场景图
SGG:Scene Graph Generation 场景图生成,有的论文也将其称为Scene Graph Parsing
前言
本篇论文作者是Nanyang Technological University的Kaihua Tang,作者本人的知乎主页。
从论文的题目中可以看出,作者期望从有偏见的训练中(Biased Training)利用无偏预测获得无偏见的场景图(Unbiased Scene Graph)。生成有偏见的场景图是现有SGG模型普遍存在的一大问题,如将human walk on/ sit on/ lay on beach等包含丰富信息的谓语简单“概括”为human on beach、将behind/ in front of“概括”为near,这就导致场景图所包含的信息不会比单纯识别出object多到那里去,因此场景图也无法向下游任务(如VQA)提供良好的帮助。
论文主要做了以下两个工作:
1)设计了一个无偏预测的推理算法Causal TDE Inference(非训练方法,模型“不可见”,适用于任何SGG模型)
2)设计了一个新的通用SGG框架Scene-Graph-Benchmark.pytorch,其使用maskrcnn-benchmark进行底层目标检测,集成了目前最全的SG metrics(包括Recall、Mean Recall、No Graph Constraint Recall、Zero Shot Recall等)。该框架提供重写的各种SGG baseline模型(如MOTIFS、VTranE、VCTree),有着当之无愧的State-of-The-Art SGCls和SGGen结果。
有偏训练
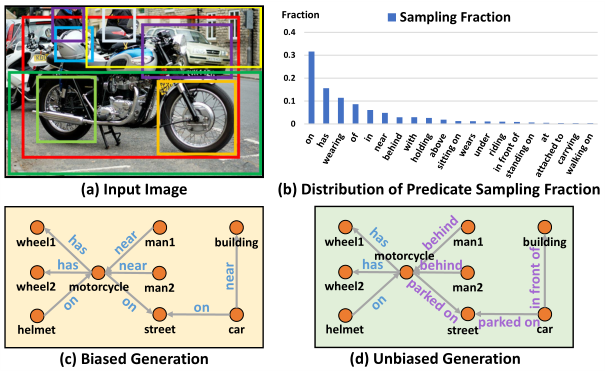
图1 SGG的一个例子
如图1(c)是目前最先进的SGG模型MOTIFS的场景图预测结果,其检测出的视觉关系简单,仅包含很少的信息量。导致这一问题的主要原因,来自于严重偏置的训练数据。如图1(b)所示,是Visual Genome数据集中最常见的谓词样本分布,呈现出VG数据集数据标注的Long Tail Effect——长尾效应(如on、has等是包含样本数量极多的简单谓语(head),而后面的一串是包含样本数量较少的谓语(long tail))。使用这样的数据集,模型将被训练成预测on的次数是standing on的1000倍,那么测试时,前者就更可能被预测出来。
造成有偏见的数据标注的原因可以分为以下三点:
- the long-tail theory:person carry bag确实比dog carry bag的数量多
- bounded rationality:在人类标注关系时,更倾向于标注简单的关系,即标注person beside table而不是person eating on table
- language or reporting bias:我们更喜欢说person on bike,而不是person ride on bike
我们不应该责怪这种有偏见的标注,因为视觉世界本是和我们描述它的方式都是有偏见的。同时,这种有偏见的数据标注也会带来好处,就是过滤掉不必要的关系候选项,如park on table、apple wear hat等。
无偏预测的思想内涵
对于人类和机器来说,其决策的制定都是由content(内因)和context(外因)混合作用而决定的。
人类在有偏见的大自然中生长,在拥抱好的context的同时,避免不好的context,并与content一起做出无偏见的决定。其潜在的机制是基于因果关系的(causality-based):决策是通过追求由content引起的主要因果效应,而不是追求由context引起的副作用来做出的。然而,机器是基于可能性的(likelihood-based),会产生有偏结果,如图2。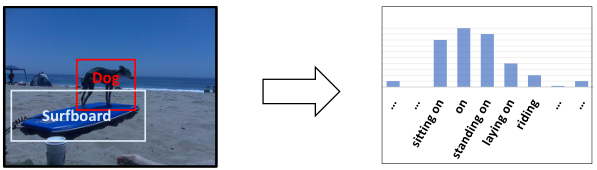
图2 基于可能性的有偏生成
注:在大多数SGG模型中
- content:object和subje的visual features
- context:object-subject union regions的visual features以及object、subject的类别标签
故论文认为,无偏预测的关键是教会机器如何区分主要作用(main effect)和副作用(side effect)。
为了在无偏预测中追求主要作用,论文提出赋予机器反事实思维(counterfactual thinking)**:
If i had not seen the content, would I still make the same prediction?
如果我没有看到content,我还会做出相同的预测吗?
反事实存在于“我看到了”的事实和“我没有看到”的想象之间,所谓反事实思维:事实与反事实之间的比较,将会自然地消除context偏差的影响,因为context是两者之间唯一不变的东西**。
注:反事实思维源自于贝叶斯之父Judea Pearl的一本名为《The Book of Why》的书,论文作者Kaihua Tang也是从此书中获取的灵感。
上一段描述有些抽象难懂,下面举一个具体的例子来帮助理解如何将反事实思维运用到场景图生成——反事实场景(counterfactual scene)和事实场景(factual scene)的比较。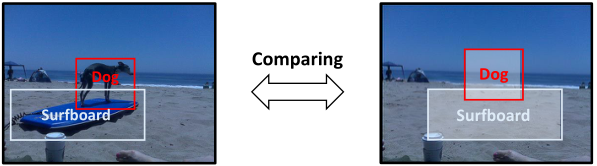
图3 一个直观的反事实思维例子
如图3,左侧图片是所谓的事实场景,也可以说是原始场景;右侧图片是反事实场景,就是将原始场景中content(狗和冲浪板的视觉特征)去除,其他部分(如scene和object classes)保持不变,就像object的视觉特征从未出现过。通过这两者的比较,我们可以专注于关系的主要视觉影响,同时也不丢失context。
作者构建图3那样的反事实场景的原因 作者认为,SGG中的偏见主要来源于图3那样的反事实场景,即不看具体的两个物体的状态(feature),单纯通过两个物体的label和一个union box的环境信息,就盲猜这两个物体是什么relationship。因为VisualGenome数据集的bias和长尾效应,偏偏这种盲猜不仅更容易学习还大部分情况下都是对的。导致的结果就是,具体的visual feature不再重要,也就预测不出真正有意义的细粒度的relationships了。因为更细粒度的relation出现太少,而且很容易错,所以干脆把所有复杂的sitting on/standing on/riding全预测成on。
无偏预测的具体方法
上一节讨论了无偏预测的思想内涵,本节将令无偏预测付诸实践。论文提出了一种基于因果推理的无偏场景图生成方法,称之为Total Direct Effect, TDE。
实际上偏差问题在机器学习中已经研究了很长时间,现有的去偏方法大致可以分为以下三类:
- 数据增强或重新采样
- 通过精心设计的training curriculums或learning losses进行无偏学习。
- 从无偏见中分离出有偏见的陈述
论文提出的TDE可以视为第三类方法,但其不同于属于第三类的其他方法(如Seeing through..和Reducing unimodal…等),TDE不需要训练额外的层来建模偏差,它通过**因果图上的反事实运算**直接将偏差与现有模型分开,如下图。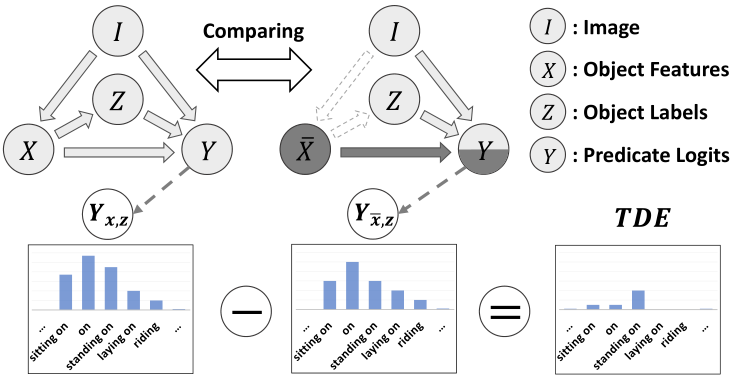
图4 基于TDE的无偏生成
这里可以简单地将节点理解为数据特征,有向链理解为数据流,如X→Y、Z→Y、I→Y表示关系Y是根据以下内容的组合生成的:object和subject的视觉特征、object和subject的类别标签、图像Image。因果图的反事实运算,实际上类似于图三的原始(事实)场景和反事实场景之间的运算,只不过这里变成了**原始因果图(根据有偏训练框架转换而成)与反事实因果图**(在原始因果图的基础上进行一系列变化,后面讲解)的运算。
原始因果图(Original Causal Graph)
在了解因果图前先看一下场景图生成的有偏训练框架(简单看一下就行)。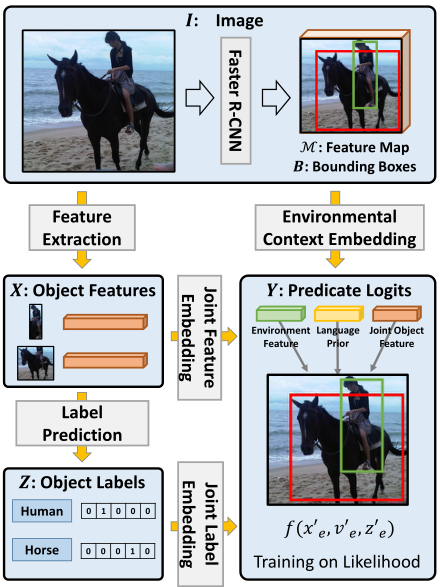
图5 场景图生成的有偏训练框架
我们可以将场景图生成的有偏训练框架转为因果图形式。如下图所示。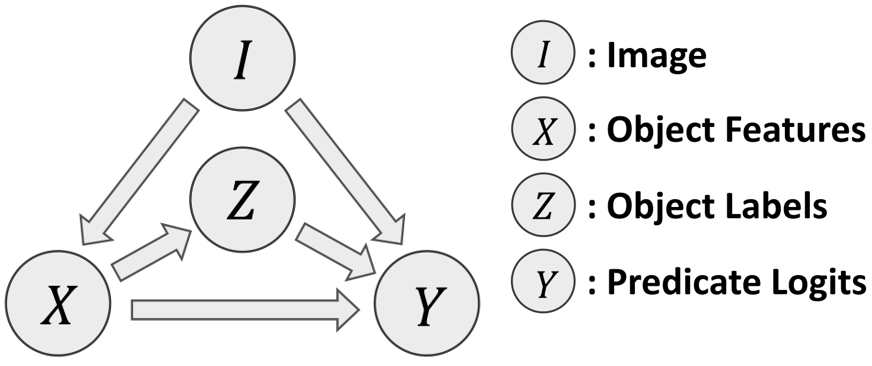
图6 原始因果图
因果图是一个有向无环图G={N, E},表示一组变量N如何通过因果联系E相互作用,它提供了数据背后因果关系的草图以及变量是如何获得它们的值。图6的因果图适用于各种SGG方法,因为它非常通用,对详细的实现没有任何限制。
对于图6因果图含义的全面解析:
- Node I (Input Image&Backbone):
预训练的Faster RCNN被冻结在该结点,image输入该结点后,结点输出一组bounding boxes B={b__|i=1…n} 以及image的feature map M__ 。
- Link I → X (Object Feature Extractor):
首先通过Faster RCNN的object classifier提取RoIAlign特征 R = {r__} 和暂定的object类别标签 L __= {l__} ,然后采用某种方式(MOTIFS:LSTMs、VCTree:TreeLSTMs、VTransE:全连接层)为每个object编码visual context,即
Input: {(rbl)} ⇒ Output: {x__}
- Node X (Object Feature)
object对儿(object-subject)的feature表示为 X = {(xx)|i≠j; i, j=1…n}。方便起见,后文中i和j的组合表示为e: x__= (x__x)
- Link X → Z (Object Classification)
每个object的微调标签通过某种方式从相应的x解码得来。即
Input: {x} ⇒ Output: {z__}
- Node Z (Object Class)
该结点包含object对儿的类别标签z__= (z____z)
- Link X → Y (**Object Feature** Input for SGG)
Link Z → Y (**Object Class** Input for SGG)
Link I → Y (**Visual Context** Input for SGG)
三个影响谓语类别的链接,其含义分别是:
a. 将成对的特征X合并为一个联合表示,即
Input: {x__} ⇒ Output: {x__‘}
b. 计算language prior z__‘ = W[z__⊗z__]
c. 提取contextual union region特征v__’ = Convs(RoIAlign(M, b∪b__)),其中b∪b表示两个RoI的union box
- Node Y (Predicate Classification)
三个分支的输入再经过融合函数(fusion function)得到谓语Y的logits y。目前有两个通用的融合函数:
- SUM: y= Wx‘ + Wv’ + z’
- GATE: y = Wx‘ · σ(Wx‘ + Wv’ + z’),其中σ(·)表示sigmoid函数
反事实因果图(Counterfactual Causal Graph)
得到上述的原始因果图后,就可以进一步推断反事实因果图。反事实因果图的推断过程:
原始因果图 → 被干预的原始因果图 → 反事实因果图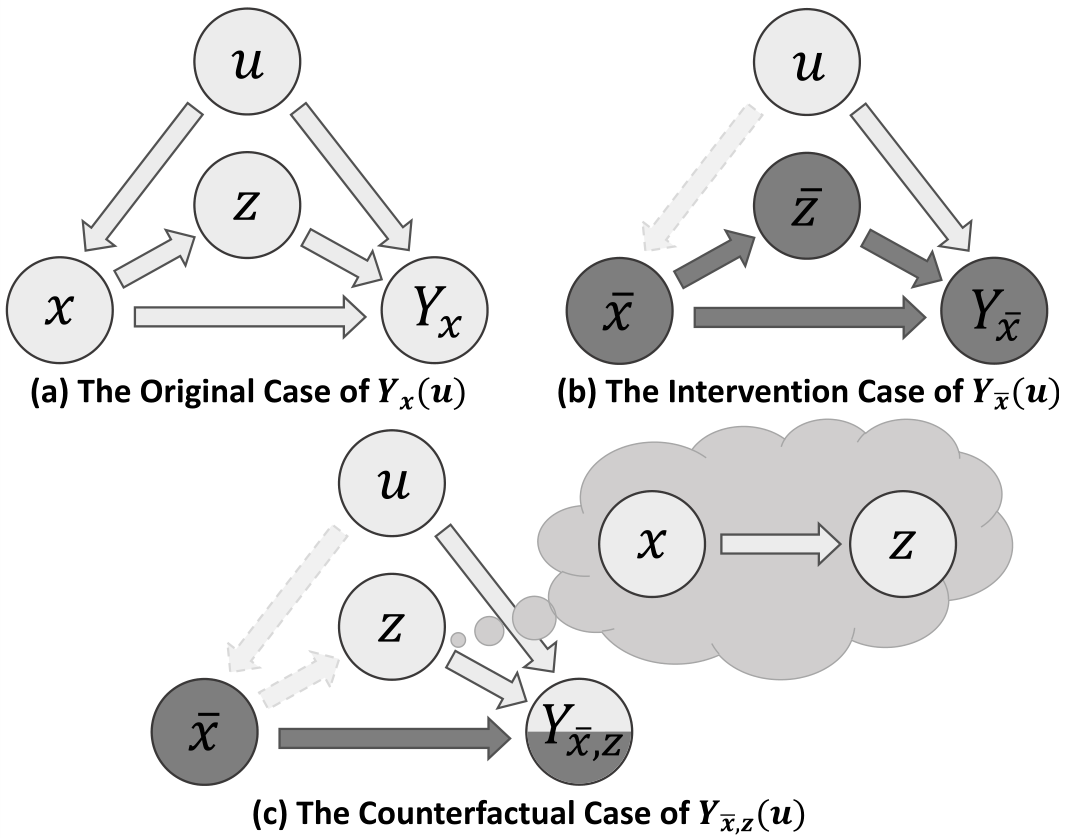
图7 原始、被干预、反事实的因果图
其中u表示输入SGG的图片;x、z等表示结点X、Z的取值;原始的和反事实的Y,可表示为Y(u)和Y(u)(使用x~代替上划线x)
- 干预(Intervention):该过程表示为do(·),表示清除了因果图中某个结点的所有输入链接,并要求该结点取某个值,如
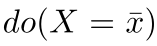
表示结点X不再受其因果父代(即结点I)的影响,并指定其值为x~。
注意:干预某个结点后,其后所有子节点均受到干预的影响。
如图7(b),结点 X 被干预后的例子。
- 反事实(Counterfactual):它的意思是“counter to the facts”,即某个图被干扰后,令某个结点认为其原始的因果父代仍然存在,不受干预的影响,保持原始值。如图7(c)中的Z结点,在结点X被干预后,其仍取原始值z,就好像原始的因果父代X仍然存在一样(X仍然取值x)。
我们使用的反事实因果图就是图7(c)的例子,即
- 对结点X进行干预,令其值为x~(通常来说,x~的值可以设置为零向量或者训练集样本特征的平均值,平均值的效果较好),这部分可以表示将object-subject的visual feature抹掉;
- 结点Z反事实,其值仍为原始值,这部分可以表示object-subject的标签保留原样
- 最后的结果Y(u)受(x~, z, u)三个分支的影响
如此,反事实因果图就正确地对应于反事实场景的设定,如图3中的反事实场景:原始场景中content(狗和冲浪板的视觉特征)去除,其他部分(scene和object classes)保持不变,就像object的视觉特征从未出现过。
因果图上的反事实运算——TDE
如在“无偏预测的思想内涵”一节中讨论的,我们可以依靠观察到的结果Y(u)和它的反事实替代Y(u)之间的差异来消除偏见的影响。在因果推断(causal inference)中,上述差异可以计算为Total Direct Effect(TDE):
TDE = **Y(u) - Y**(u)
其中第一项来自图7(a)原始图,第二项来自图7(c)反事实图。
最后,回到场景图生成,我们提出的无偏预测方法是通过用TDE来代替传统的一次性预测得到结果,即本质上“思考”了两次:一次得到正常的观测值**Y(u) = y(x, z__),一次得到假想的值Y(u) = y(x~, z__)
关于TDE的模型“不可见”
我们可以发现所谓的TDE方法没有引入任何额外的参数,也可以说没有针对模型的有偏训练进行任何改动,其使用原始SGG模型进行了两次预测,将两次预测的结果进行差值运算,最终得到无偏见的预测。所以TDE方法是模型“不可见”的,广泛适用于各种SGG模型。
实验
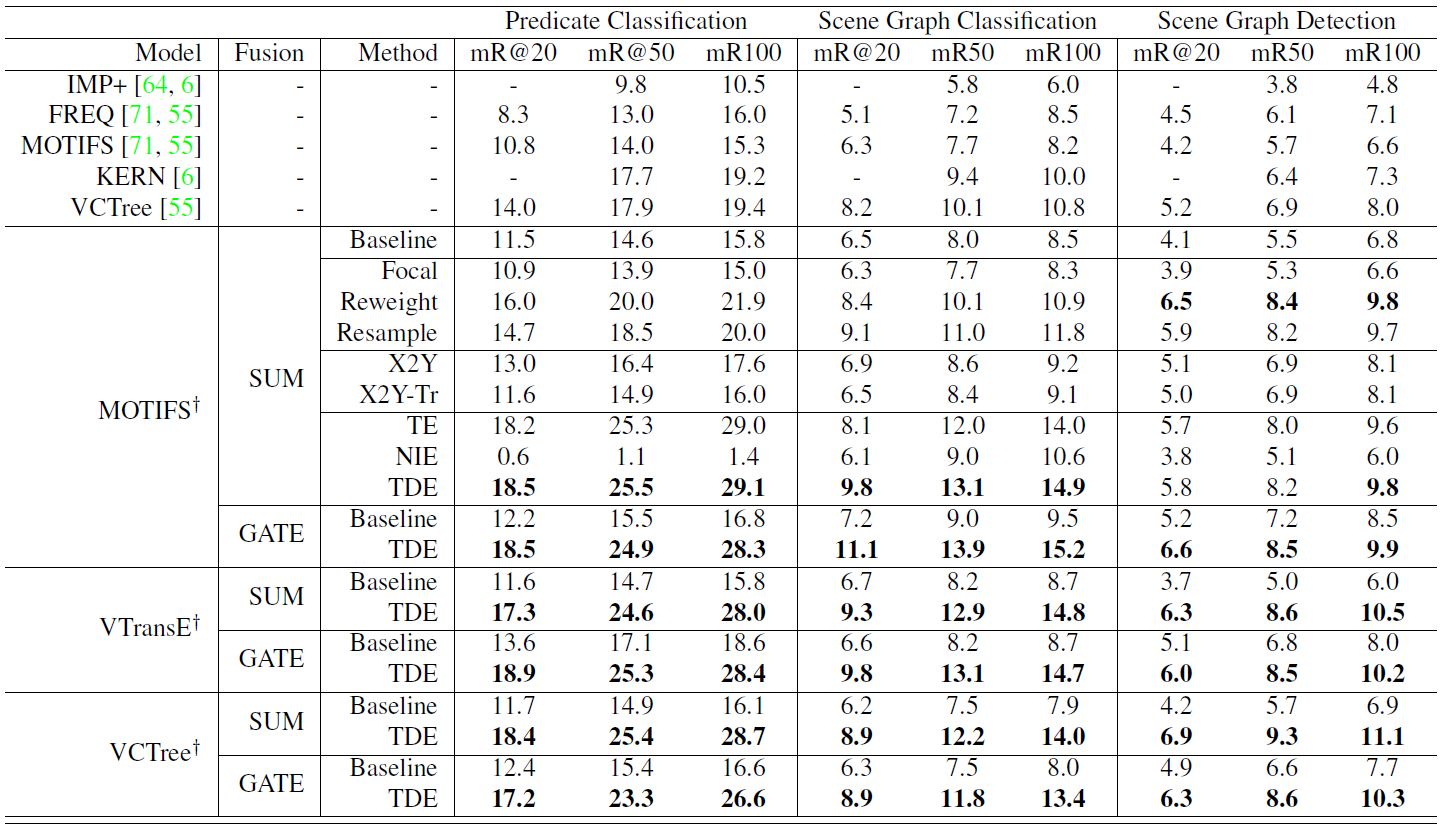
数据集
本次实验使用Visual Genome(VG)数据集,由于该数据集92%的谓词仅有不超过10个实例,故我们遵循广泛采用的VG数据集分割方式,即使用包含150个最常见的object类别和50个最常见的predicate类别的VG分割。
实验内容
我们使用mear Recall指标评估了三个模型:VTransE、MOTIFS、VTree在三种场景图生成的子任务上的性能,这三个子任务分别是:
PredCls(给定ground truth bounding boxes和labels作为输入)、
SGCls(给定ground truth bounding boxes作为输入)、
SGDet\SGGen(给定Image作为输入)
上表中,论文提出的SGG框架Scene-Graph-Benchmark.pytorch中重写的模型使用 † 标注。
评估时,模型分别使用了两种融合函数以及九种推理方法,两种融合函数是:SUM、GATE,九种推理方法分别是:
a. baseline
b. 三种conventional debiasing methods:Focal、Reweight、Resample
c. 两种intuitive causal graph surgeries:X2Y、X2Y-Tr
d. 三种causal effects:TE、NIE、TDE
实验结果
使用mean Recall@K指标,论文提出的TDE方法明显优于其他推理方法(包括baseline),有效的改善了SGG模型的性能。同时我们可以发现,三种SGG模型以及它们分别使用的两种融合函数,在不同情况下表现不同,实际使用时要结合实际进行选择。

若有收获,就点个赞吧
0 人点赞
