动机
预训练将致力于解决图学习面临的两个挑战:
- 特定任务的已标记数据可能极其稀缺
- 训练集中的图在结构上不同与测试集(现实世界)中的图
很少有研究将预训练推广到图数据。
先前的研究表明,在图数据集上进行预训练还面临一项巨大的挑战:
成功的迁移学习需要大量的专业知识来仔细选择与下游任务相关的样本和标签。否则,知识从相关的预训练任务转移到新的下游任务会损害泛化性,并显著限制了预训练模型的适用性和可靠性,这被称为负迁移。
- 本文提出的预训练策略成功的关键是在单个节点层次以及整个图层次上预先训练一个有表现力的GNN,这样GNN就可以同时学习有用的局部和全局表示。
传统的预训练方法在整个图层次或单个节点层次上预训练GNN,只能带来有限的改进,甚至导致下游任务的负迁移。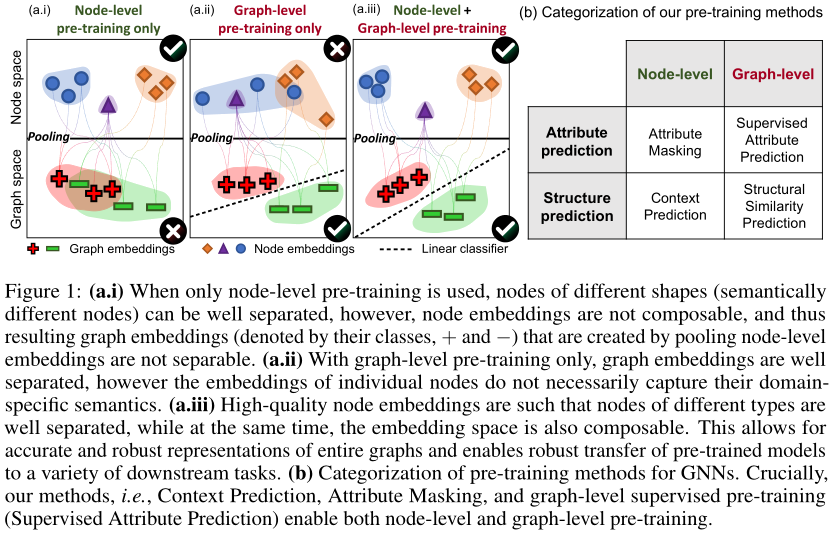
- 图b是本文提出的预训练方法,包括节点级和图级(其中Structural Similarity Prediction并未实现)。
方法概述
- 本文提出了一个自监督学习的方法,用于图级预测任务GNN的预训练。
We focus on pre-training as an approach to transfer learning in Graph Neural Networks (GNNs) for graph-level property prediction.
- 本文工作的两个核心贡献:
- 作者首次系统的探索了大规模GNN预训练。为此,作者建立了两个新的预训练数据集,并且分享出来,一个有2M graph的化学数据集和一个有395K graph的生物数据集。同时作者还表明,大尺度的特定领域数据集的预训练研究是至关重要的,现有的下游任务数据集太小,无法以统计上可靠的方式进行模型评估。
- 提出了一种有效的GNN预训练策略。
具体方法
- 方法的核心
同时在独立的节点级别与图级别去预训练GNN
节点级预训练
- 对于节点级别的预训练,本文的方法是用那些容易获得的没有标注的数据,来捕捉特定领域的知识与规则,并提出了两个自学习策略,Context Prediction和Attribute Masking
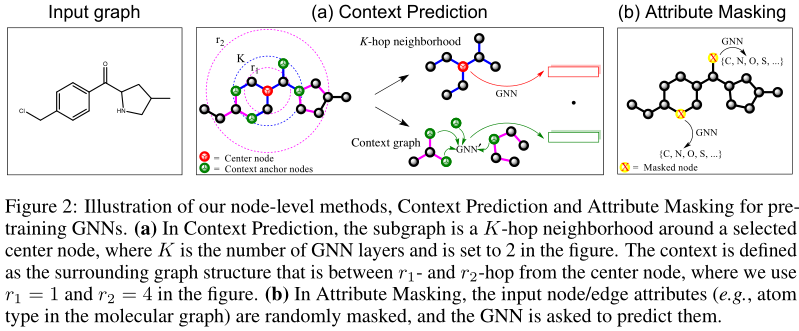
Context Prediction: Exploiting distribution of graph structure
本方法的目标是能够使得相似结构的节点的embedding相似。
主GNN编码邻居以获得节点embedding,context GNN编码context graph以获得context embedding。
Attribute Masking: Exploiting distribution of graph attributes
- 随机掩盖一些节点/边的特征,用特殊的标识代替,然后放进gnn学周围的embedding,利用周围的embedding来预测这个特征。
图级预训练
- 我们的目标是预训练GNN来生成有用的graph embedding,该graph embedding由节点级预训练中的方法获得的有意义的节点embedding组成。
- 图级预训练有两个选项,如图1 (b)所示:预测整个图的特定领域属性,或预测图结构。
Supervised Graph-Level Property Prediction
- 作者利用多任务联合学习不同的任务来预训练。然而,朴素的直接多任务图级别的预训练可能在迁移的时候失效,因为这些任务可能与下游任务无关,造成负迁移。一个解决方案是选择真正相关的预训练任务,只拿这些任务预训练。然而,寻找这些任务代价非常大。
- 多任务学习的预训练只用来做图级别的预训练,因此,创造graph embedding的这些局部节点的embedding可能会变得无意义。这些无意义的节点会加剧负迁移,许多没有用的与训练任务会互相干扰。
- 所以,基于此,才有了之前先预训练节点级别的embedding的方法,作为正则,然后再进行graph级别的预训练。
Structual Simailarity Prediction
- 没做
实验
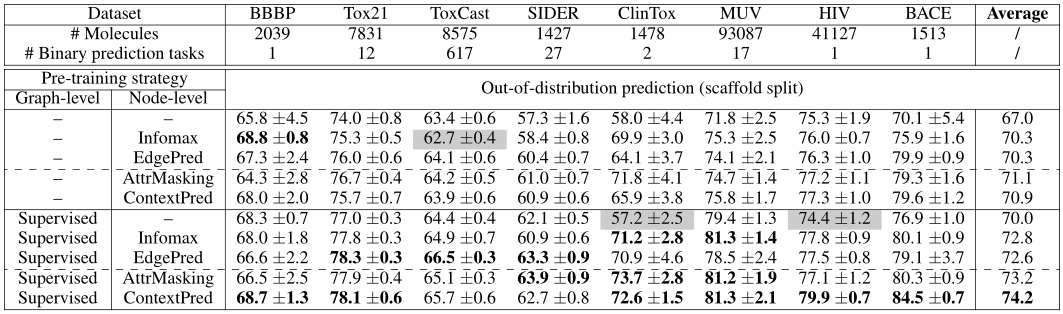
- 实验针对两个领域:化学中的分子性质预测和生物学中的蛋白质功能预测。

若有收获,就点个赞吧
0 人点赞
